hadoop中使用MapReduce单表关联案例:
MapReduce:给出children-parents(孩子——父母)表,要求输出grandchild-grandparent(孙子——爷奶)表。
给出表:
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
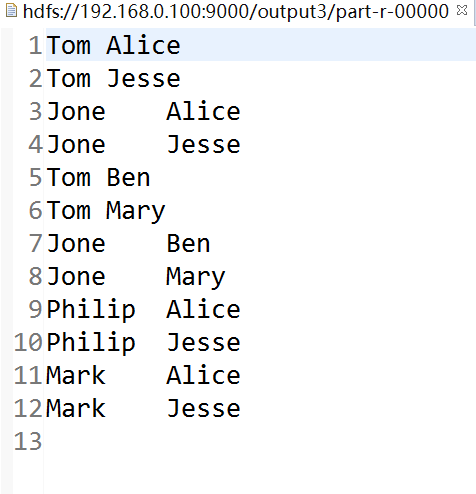
要求实现如下效果:
设计思路:将这张单表分成两张表如下:
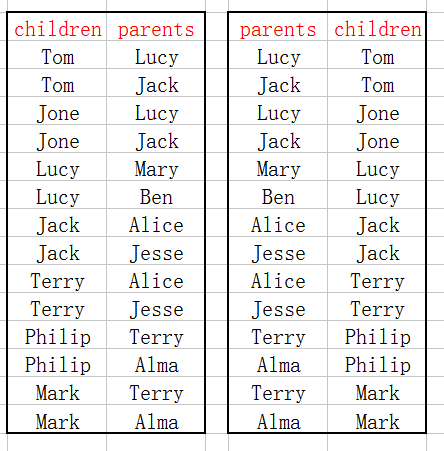
将左表的parents列和右表的child列进行连接,连接结果中除去连接的两列就是所需要的结果:"grandchild--grandparents"表。
因为MapReduce的shuffle过程会将相同的key会连接在一起,所以在map阶段将读入数据分割成children和parents之后,
左表:将parents设置成key,children设置成value进行输出
右表:将children设置成key,parents设置成value进行输出
为了区分输出中的左右表,需要在输出的value中再加上左右表的信息,比如在value的最开始处加上字符1表示左表,加上字符2表示右表。
这样在map的结果中就形成了左表和右表,然后在shuffle过程中完成连接。
reduce接收到连接的结果,遍历values集合,得到每个value的值,将左表中的children放入children数组,右表中的parents放入parents数组,然后对两个数组求笛卡尔积就能得到最后结果。
代码如下(由于水平有限,不保证完全正确,如果发现错误欢迎指正):
package com; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TestParents { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration config = new Configuration(); config.set("fs.defaultFS", "hdfs://192.168.0.100:9000"); config.set("yarn.resourcemanager.hostname", "192.168.0.100"); FileSystem fs = FileSystem.get(config); Job job = Job.getInstance(config); job.setJarByClass(TestParents.class); //设置所用到的map类 job.setMapperClass(myMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //设置用到的reducer类 job.setReducerClass(myReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //设置输入输出地址 FileInputFormat.addInputPath(job, new Path("/input/parent.txt")); Path path = new Path("/output3/"); if(fs.exists(path)){ fs.delete(path, true); } //指定文件的输出地址 FileOutputFormat.setOutputPath(job, path); //启动处理任务job boolean completion = job.waitForCompletion(true); if(completion){ System.out.println("Job Success!"); } } public static class myMapper extends Mapper<Object, Text, Text, Text> { // 实现map函数 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String temp=new String();// 左右表标识 String values=value.toString(); String words[]=values.split(" "); //Tom Lucy // 输出左表 temp = "1"; context.write(new Text(words[1]), new Text(temp +"+"+ words[0] + "+" + words[1])); //(Lucy,1+Tom+Lucy) // 输出右表 temp = "2"; context.write(new Text(words[0]), new Text(temp +"+"+ words[0] + "+" + words[1])); //(Tom,2+Tom+Lucy) } } public static class myReducer extends Reducer<Text, Text, Text, Text> { // 实现reducer函数 public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { List<String> grandchild = new ArrayList<String>(); List<String> grandparent = new ArrayList<String>(); for (Text value : values) { char temp=(char) value.charAt(0); String words[]=value.toString().split("[+]"); //1,Tom+Lucy // +、*、|、/等符号在正则表达示中有相应的不同意义,一般来讲只需要加[]、或是\即可 if(temp == '1'){ grandchild.add(words[1]); } if(temp == '2'){ grandparent.add(words[2]); } } //求笛卡尔儿积 for (String gc : grandchild) { for (String gp : grandparent) { context.write(new Text(gc),new Text(gp)); } } } } }
运行详解:
(1)Map处理如下所示:
Tom Lucy map输出: <Lucy,1+Tom+Lucy> <Tom,2+Tom+Lucy > Tom Jack map输出: <Jack,1+Tom+Jack> <Tom,2+Tom+Jack> Jone Lucy map输出: <Lucy,1+Jone+Lucy> <Jone,2+Jone+Lucy> Jone Jack map输出: <Jack,1+Jone+Jack> <Jone,2+Jone+Jack> Lucy Mary map输出: <Mary,1+Lucy+Mary> <Lucy,2+Lucy+Mary> Lucy Ben map输出: <Ben,1+Lucy+Ben> <Lucy,2+Lucy+Ben> Jack Alice map输出: <Alice,1+Jack+Alice> <Jack,2+Jack+Alice> Jack Jesse map输出: <Jesse,1+Jack+Jesse> <Jack,2+Jack+Jesse> Terry Alice map输出: <Alice,1+Terry+Alice> <Terry,2+Terry+Alice> Terry Jesse map输出: <Jesse,1+Terry+Jesse> <Terry,2+Terry+Jesse> Philip Terry map输出: <Terry,1+Philip+Terry> <Philip,2+Philip+Terry> Philip Alma map输出: <Alma,1+Philip+Alma> <Philip,2+Philip+Alma> Mark Terry map输出: <Terry,1+Mark+Terry> <Mark,2+Mark+Terry> Mark Alma map输出: <Alma,1+Mark+Alma> <Mark,2+Mark+Alma>
(2)Shuffle处理如下:
|
map函数输出 |
排序结果 |
shuffle连接 |
|
<Lucy,1+Tom+Lucy> <Tom,2+Tom+Lucy> <Jack,1+Tom+Jack> <Tom,2+Tom+Jack> <Lucy,1+Jone+Lucy> <Jone,2+Jone+Lucy> <Jack,1+Jone+Jack> <Jone,2+Jone+Jack> <Mary,1+Lucy+Mary> <Lucy,2+Lucy+Mary> <Ben,1+Lucy+Ben> <Lucy,2+Lucy+Ben> <Alice,1+Jack+Alice> <Jack,2+Jack+Alice> <Jesse,1+Jack+Jesse> <Jack,2+Jack+Jesse> <Alice,1+Terry+Alice> <Terry,2+Terry+Alice> <Jesse,1+Terry+Jesse> <Terry,2+Terry+Jesse> <Terry,1+Philip+Terry> <Philip,2+Philip+Terry> <Alma,1+Philip+Alma> <Philip,2+Philip+Alma> <Terry,1+Mark+Terry> <Mark,2+Mark+Terry> <Alma,1+Mark+Alma> <Mark,2+Mark+Alma> |
<Alice,1+Jack+Alice> <Alice,1+Terry+Alice> <Alma,1+Philip+Alma> <Alma,1+Mark+Alma> <Ben,1+Lucy+Ben> <Jack,1+Tom+Jack> <Jack,1+Jone+Jack> <Jack,2+Jack+Alice> <Jack,2+Jack+Jesse> <Jesse,1+Jack+Jesse> <Jesse,1+Terry+Jesse> <Jone,2+Jone+Lucy> <Jone,2+Jone+Jack> <Lucy,1+Tom+Lucy> <Lucy,1+Jone+Lucy> <Lucy,2+Lucy+Mary> <Lucy,2+Lucy+Ben> <Mary,1+Lucy+Mary> <Mark,2+Mark+Terry> <Mark,2+Mark+Alma> <Philip,2+Philip+Terry> <Philip,2+Philip+Alma> <Terry,2+Terry+Alice> <Terry,2+Terry+Jesse> <Terry,1+Philip+Terry> <Terry,1+Mark+Terry> <Tom,2+Tom+Lucy> <Tom,2+Tom+Jack> |
<Alice,1+Jack+Alice, 1+Terry+Alice , 1+Philip+Alma, 1+Mark+Alma > <Ben,1+Lucy+Ben> <Jack,1+Tom+Jack, 1+Jone+Jack, 2+Jack+Alice, 2+Jack+Jesse > <Jesse,1+Jack+Jesse, 1+Terry+Jesse > <Jone,2+Jone+Lucy, 2+Jone+Jack> <Lucy,1+Tom+Lucy, 1+Jone+Lucy, 2+Lucy+Mary, 2+Lucy+Ben> <Mary,1+Lucy+Mary, 2+Mark+Terry, 2+Mark+Alma> <Philip,2+Philip+Terry, 2+Philip+Alma> <Terry,2+Terry+Alice, 2+Terry+Jesse, 1+Philip+Terry, 1+Mark+Terry> <Tom,2+Tom+Lucy, 2+Tom+Jack> |
(3)Reduce处理:
取出values(Jack , {1+Tom+Jack},{1+Jone+Jack},{1+Jone+Jack},{2+Jack+Jesse })遍历出来的一条value的值:1+Tom+Jack
根据1或者2,把值给grandchild数组和grandparent数组。
最后由语句: for (String gc : grandchild) {
for (String gp : grandparent) {
context.write(new Text(gc),new Text(gp));
}
}
得知:只要数组grandchild中没有值或者数组grandparent没有值,则不会做处理,根据这条规则去除无效的shuffle连接,就能得出最后的结果。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击下方的【好文要顶】按钮【精神支持】,因为这两种支持都是使我继续写作、分享的最大动力!