本文我们来介绍一下编程中常见的一些数据结构。
为什么要学习数据结构?
随着业务场景越来越复杂,系统并发量越来也高,要处理的数据越来越多,特别是大型互联网的高并发、高性能、高可用系统,对技术要求越来越高,我们引入各种中间件,这些中间件底层涉及到的各种数据结构和算法,是其核心技术之一。如:
ElasticSearch中用于压缩倒排索引内存存储空间的FST,用于查询条件合并的SkipList,用于提高范围查找效率的BKDTree;
各种分库分表技术的核心:hash算法;
Dubbo或者Nginx等的负载均衡算法;
MySQL索引中的B树、B+树等;
Redis使用跳跃表作为有序集合键的底层实现之一;
Zookeeper的节点树;
J.U.C并发包的各种实现的阻塞队列,AQS底层实现涉及到的链式等待队列;
JDK对HashMap的Hash冲突引入的优化数据结构红黑树…
可以发现,数据结构和算法真的是无处不在,作为一个热爱技术,拒绝粘贴复制的互联网工程师,怎么能不掌握这些核心技术呢?

与此同时,如果你有耐心听8个小时通俗易懂的数据结构入门课,我强烈建议你看一下以下这个视频,来自一位热衷于分享的Google工程师:
Data Structures Easy to Advanced Course - Full Tutorial from a Google Engineer
https://www.youtube.com/watch?v=RBSGKlAvoiM
阅读完本文,你将了解到一些常见的数据结构(或者温习,因为大部分朋友大学里面其实都是学过的)。在每个数据结构最后一小节都会列出代码实现,以及相关热门的算法题,该部分需要大家自己去探索与书写。只有自己能熟练的编写各种数据结构的代码才是真正的掌握了,大家别光看,动手写起来。阅读完本文,您将了解到:
抽象数据类型与数据结构的关系;
如何评估算法的复杂度;
了解以下数据结构,并且掌握其实现思路:数组,链表,栈,队列,优先级队列,索引式优先队列,二叉树,二叉搜索树BST,平衡二叉搜搜书BBST,AVL树,HashTable,并查集,树状数组,后缀数组。
文章里面不会贴这些数据结构的完整实现,但是会附带实现的链接,同时每种数据类型最后一节的相关实现以及练习题,建议大家多动手尝试编写这些练习题,以及尝试自己动手实现这些数据结构。
1、抽象数据类型
抽象数据类型(ADT abstract data type):是数据结构的抽象,它仅提供数据结构必须遵循的接口。接口并未提供有关应如何实现某种内容或以哪种编程语言的任何特定详细信息。
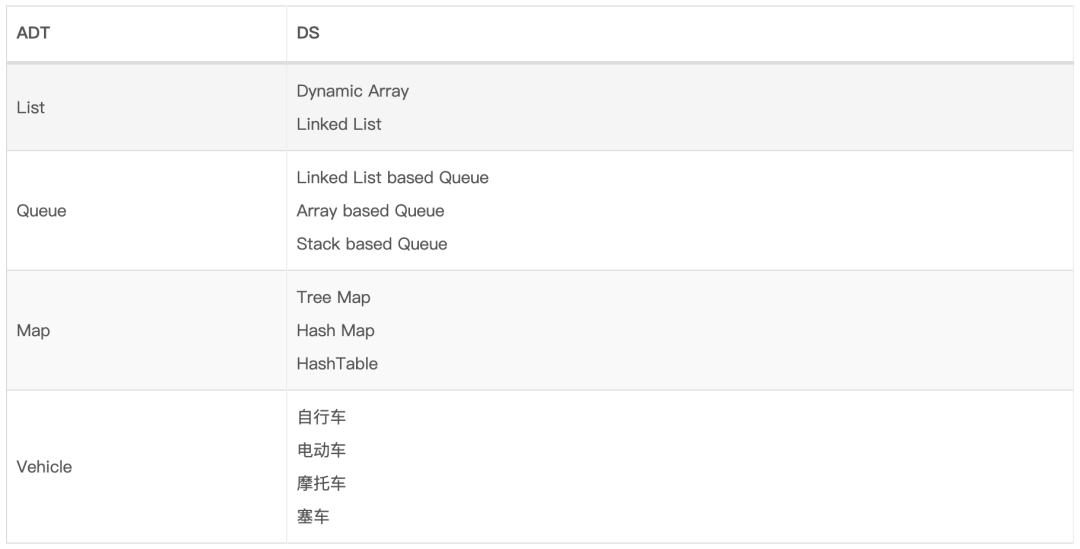
下标列举了抽象数据类型和数据结构之间的构成关系:
2、时间与空间复杂度
我们一般会关注程序的两个问题:
时间复杂度:这段程序需要花费多少时间才可以执行完成?
空间复杂度:执行这段代码需要消耗多大的内存?
有时候时间复杂度和空间复杂度二者不能兼得,我们只能从中取一个平衡点。
下面我们通过Big O表示法来描述算法的复杂度。
2.1、时间复杂度
2.1.1、BIG-O
Big-O表示法给出了算法计算复杂性的上限。
T(n) = O(f(n)),该公式又称为算法的渐进时间复杂度,其中f(n)函数表示每行代码执行次数之和,O表示执行时间与之形成正比例关系。
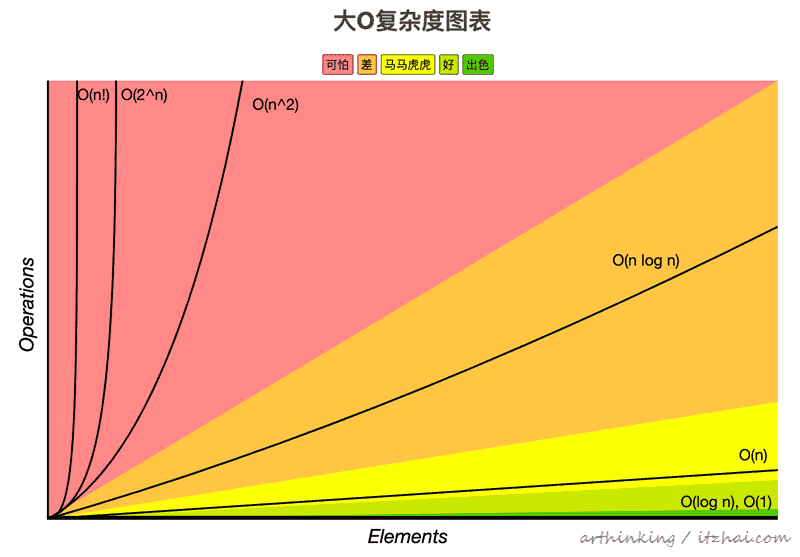
常见的时间复杂度量级,从上到下时间复杂度越来越大,执行效率越来越低:
常数阶 Constant Time: O(1)
对数阶 Logarithmic Time: O(log(n))
线性阶 Linear Time: O(n)
线性对数阶 Linearithmic Time: O(nlog(n))
平方阶 Quadratic Time: O(n^2)
立方阶 Cubic Time: O(n^3)
n次方阶 Exponential Time: O(b^n), b > 1
指数阶 Factorial Time: O(n!)
下面是我从 Big O Cheat Sheet[1]引用过来的一张表示各种度量级的时间复杂度图表:
2.1.2、如何得出BIG-O
所谓Big-O表示法,就是要得出对程序影响最大的那个因素,用于衡量复杂度,举例说明:
O(n + c) => O(n),常量可以忽略;
O(cn) => O(n), c > 0,常量可以忽略;
2log(n)3 + 3n2 + 4n3 + 5 => O(n3),取对程序影响最大的因素。
练习:请看看下面代码的时间复杂度:

image-20200411175500608
答案依次为:O(1), O(n), O(log(n)), O(nlog(n)), O(n^2)
第三个如何得出对数?假设循环x次之后退出循环,也就是说 2^x = n,那么 x = log2(n),得出O(log(n))
2.2、空间复杂度
空间复杂度是对一个算法在运行过程中占用存储空间的大小的衡量。
O(1):存储空间不随变量n的大小而变化;
O(n):如:new int[n];
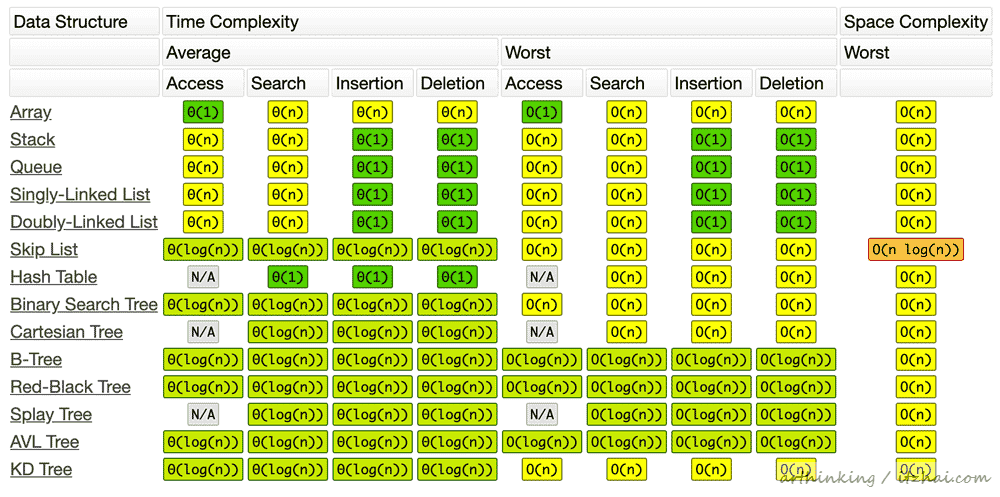
2.3、常用数据结构复杂度
一些常用的数据结构的复杂度(注:以下表格图片来源于 Big O Cheat Sheet[1]):
2.4、常用排序算法复杂度
(注:以下表格图片来源于 Big O Cheat Sheet[1])

关于复杂度符号
O:表示渐近上限,即最差时间复杂度;
Θ:表示渐近紧边界,即平均时间复杂度;
Ω:表示渐近下界,即最好时间复杂度;
3、静态数组和动态数组
3.1、静态数组
静态数组是固定长度的容器,其中包含n个可从[0,n-1]范围索引的元素。
问:“可索引”是什么意思?
答:这意味着数组中的每个插槽/索引都可以用数字引用。
3.1.1、使用场景
1)存储和访问顺序数据
2)临时存储对象
3)由IO例程用作缓冲区
4)查找表和反向查找表
5)可用于从函数返回多个值
6)用于动态编程中以缓存子问题的答案
3.1.2、静态数组特点
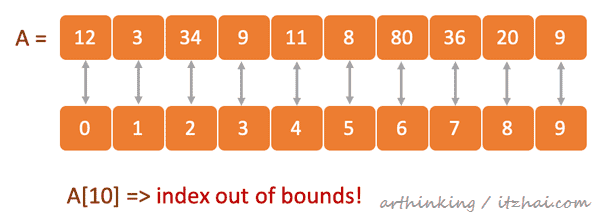
只能由数组下标访问数组元素,没有其他的方式了;
第一个下标为0;
下标超过范围了会触发数组越界错误。
3.2、动态数组
动态数组的大小可以增加和缩小。
3.2.1、如何实现一个动态数组
使用一个静态数组:
创建具有初始容量的静态数组;
将元素添加到基础静态数组,同时跟踪元素的数量;
如果添加元素将超出容量,则创建一个具有两倍容量的新静态数组,然后将原始元素复制到其中。
3.3、时间复杂度
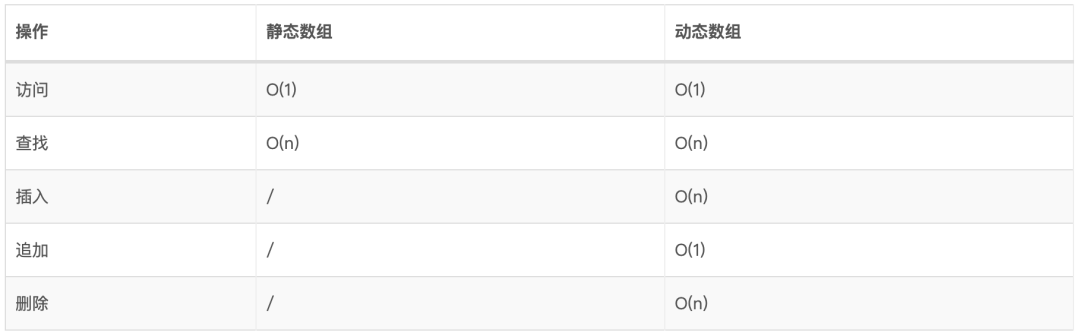
3.4、编程实践
JDK中的实现:java.util.ArrayList
练习:
两数之和:
https://leetcode-cn.com/problems/two-sum/
删除排序数组中的重复项:
https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/
杨辉三角:
https://leetcode-cn.com/problems/pascals-triangle/
最大子序和:
https://leetcode-cn.com/problems/maximum-subarray/
旋转数组:
https://leetcode-cn.com/problems/rotate-array/
4、链表
4.1、使用场景
在许多列表,队列和堆栈实现中使用;
非常适合创建循环列表;
可以轻松地对诸如火车等现实世界的物体进行建模;
某些特定的Hashtable实现用于处理散列冲突;
用于图的邻接表的实现中。
4.2、术语
Head:链表中的第一个节点;
Tail:链表中的最后一个节点;
Pointer:指向下一个节点;
Node:一个对象,包含数据和Pointer。

4.3、实现思路
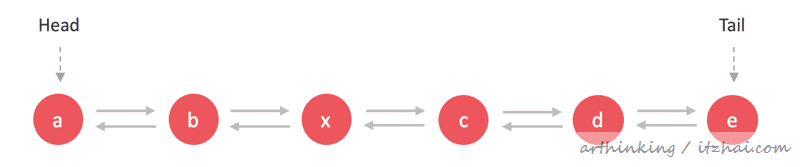
这里使用双向链表作为例子进行说明。
4.3.1、插入节点
往第三个节点插入:x
从链表头遍历,直到第三个节点,然后执行如下插入操作:
遍历到节点位置,把新节点指向前后继节点:
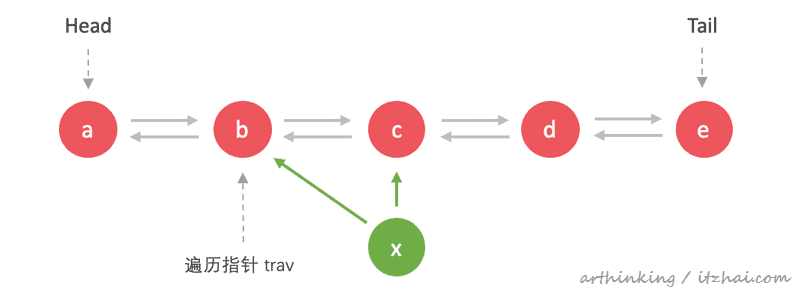
后继节点回溯连接到新节点,并移除旧的回溯关系:
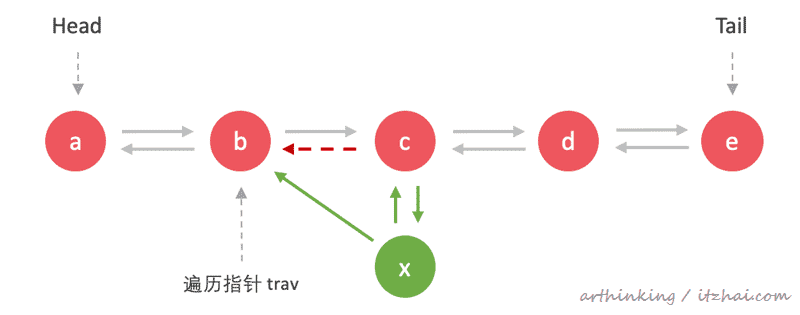
前继节点遍历连接到新节点,并移除旧的遍历关系:
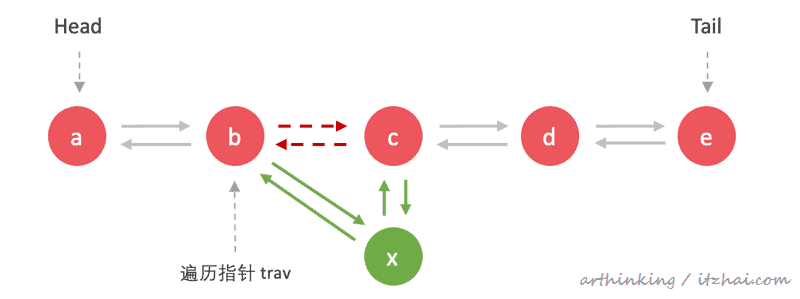
完成:
注意指针处理顺序,避免在添加过程中导致遍历出现异常。
4.3.2、删除节点
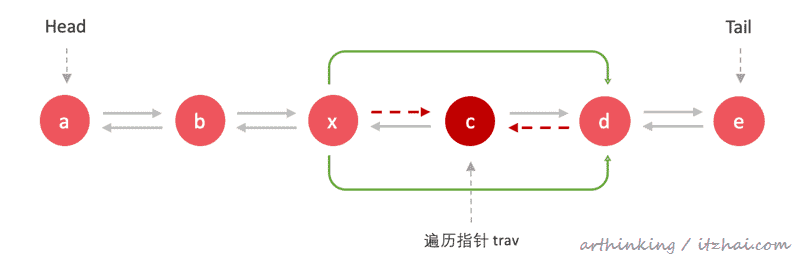
删除c节点:
从链表头遍历,直到找到c节点,然后把c节点的前继节点连接到c的后继接节点:

把c节点的后继节点连接到c的前继节点:
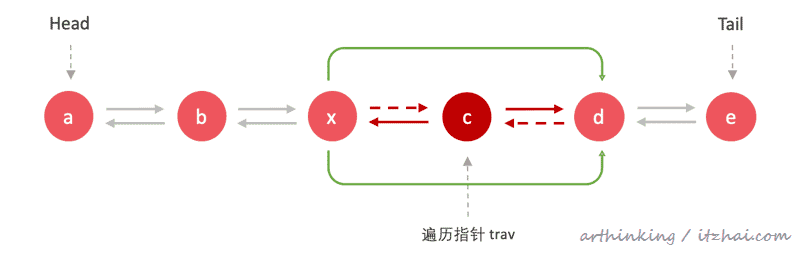
移除多余指向关系以及c节点:
完成:
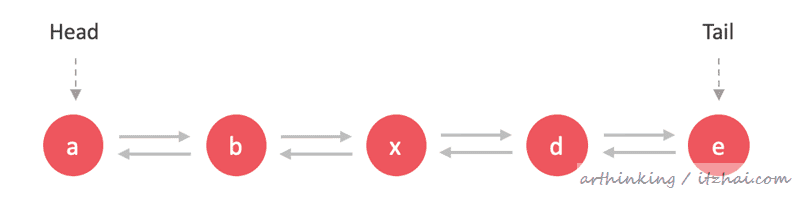
同样的,注意指针处理顺序,避免在添加过程中导致遍历出现异常。
4.4、时间复杂度
郑州妇科医院http://www.zztjyy.com/
郑州不孕不育医院哪家好http://www.zzfkyy120.com/
郑州不孕不育医院http://www.xasgnk.com/
4.5、编程实践
JDK中的实现:java.util.LinkedList
练习:
反转链表:
https://leetcode-cn.com/problems/reverse-linked-list/
回文链表:
https://leetcode-cn.com/problems/palindrome-linked-list
两数相加:
https://leetcode-cn.com/problems/add-two-numbers
复制带随机指针的链表:
https://leetcode-cn.com/problems/copy-list-with-random-pointer
5、栈
堆栈是一种单端线性数据结构,它通过执行两个主要操作(即推入push和弹出pop)来对现实世界的堆栈进行建模。
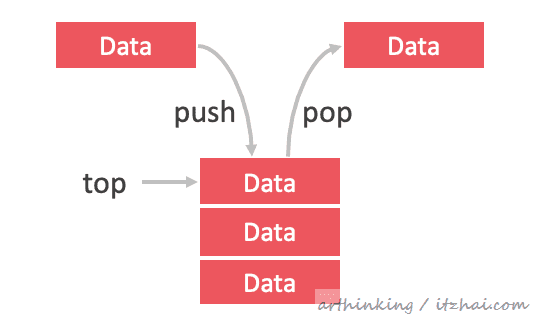
5.1、使用场景
文本编辑器中的撤消机制;
用于编译器语法检查中是否匹配括号和花括号;
建模一堆书或一叠盘子;
在后台使用,通过跟踪以前的函数调用来支持递归;
可用于在图上进行深度优先搜索(DFS)。
5.2、编程实战
5.2.1、语法校验
给定一个由以下括号组成的字符串:()[] {},确定括号是否正确匹配。
例如:({}{}) 匹配,{()(]} 不匹配。
思路:
凡是遇到( { [ 都进行push入栈操作,遇到 ) } ] 则pop栈中的元素,看看是否与当前处理的元素匹配:
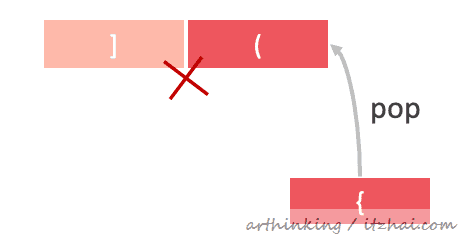
匹配完成之后,栈必须是空的。
5.3、复杂度