文章主要内容分为以下五个章节:
一、为什么需要全文检索技术
二、全文检索定义
三、倒排索引
四、分词
五、全文检索搜索过程
六、打分公式
一、为什么需要全文检索技术
简单点来说,就是解决数据库中like查询效率低下的问题。
如:在数据库商品表的一个字段,字段名为“goodsName”(商品名称),字段值类似"房间灯卧室灯 现代简约 创意 个性 北欧","卧室灯 现代 个性"。
如果产品需求是这样的:搜索“卧室灯”,那么上面这两条记录都要被搜索出来。如果使用传统的数据库的like查询,因为like的模糊匹配%xxx%不能用到查询索引,(各位知道like的匹配查询逻辑是怎么样的吗?)
一旦商品表的数据量一大,那么查询性能会变得越来越差,耗时越来越长,所以,这变的不可取。所以,这时候就需要另外一个解决类似需求的方法了:全文检索技术。
二、全文检索定义
全文检索:将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
通常全文检索技术的实现框架,采用倒排索引思想,建立词到文档的映射关系来达到快速检索的目的,如lucence,solr,elesticsearch,都是采用这种思想。
三、倒排索引
倒排索引是指通过分析文档中的包含的词语要素,然后建立起词语->文档的映射关系。
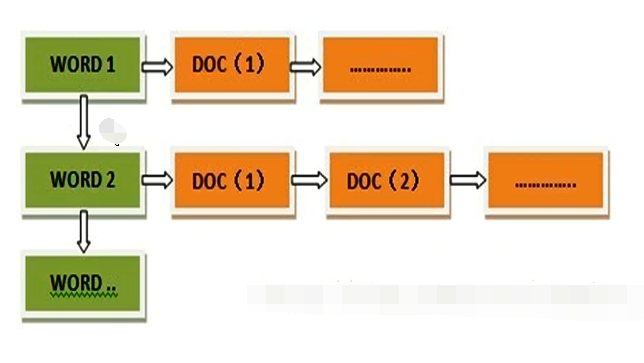
例如有如下的5个文档:
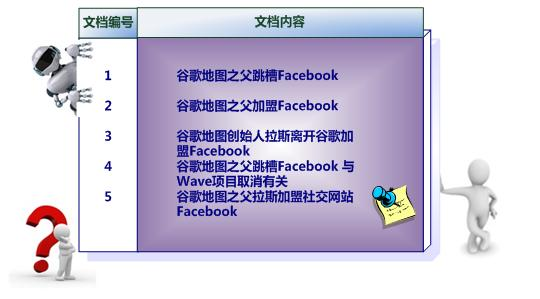
在建立倒排索引后的结构如下:
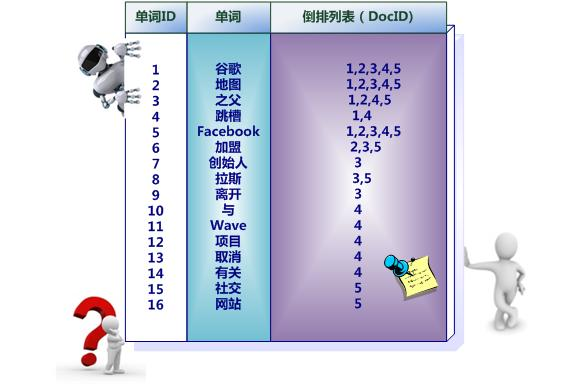
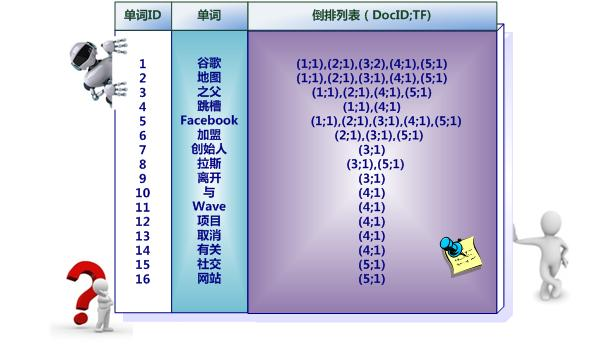
上面倒排索引是最简单的,是因为这个索引系统只记载了哪些文档包含某个单词,而事实上,索引系统还可以记录除此之外的更多信息。图5是一个相对复杂些的倒排索引,与图4的基本索引系统比,在单词对应的倒排列表中不仅记录了文档编号,还记载了单词频率信息(TF),即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。在图5的例子里,单词“创始人”的单词编号为7,对应的倒排列表内容为:(3:1),其中的3代表文档编号为3的文档包含这个单词,数字1代表词频信息,即这个单词在3号文档中只出现过1次,其它单词对应的倒排列表所代表含义与此相同。
四、分词
分词定义:
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,
虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。
分词方法参考:https://baike.baidu.com/item/%E4%B8%AD%E6%96%87%E5%88%86%E8%AF%8D/371496?fr=aladdin
分词体验:http://www.78901.net/participle/?ac=done
五、全文检索搜索过程
假如搜索引擎里面已经存储了跟上面(章节3)描述一样的数据, 在搜索框中输入"创始人拉斯" ,那么搜索引擎会把输入句子分为两个词:"创始人"、"拉斯"。
那么,通过搜索引擎里面已经建立好的倒排索引,会找到id为3的文档包含"创始人"这个关键词,id为3和5的文档包含"拉斯"这个关键词,然后搜索引擎会把包含所有关键词的文档作为命中的结果集,
再根据文档跟输入语句的相似度排序输出,相似度越大,那么就优先排在前面。
参考链接:https://blog.csdn.net/wangyangzhizhou/article/details/68947519
评分机制
- tf, 表示term匹配文章的程度,如果在一篇文章中该term出现了次数越多,说明该term对该文章的重要性越大,因而更加匹配。相反的出现越少说明该term越不匹配文章。但是这里需要注意,出现次数与重要性并不是成正比的,比如term A出现10次,term B出现1次,对于该文章的重要性term A并不是term B的10倍,所以这里tf的值进行平方根计算。
tf(t in d) = numTermOccurrencesInDocument 1/2
- idf, 表示包含该文章的个数,与tf不同,idf 越大表明该term越不重要。比如this很多文章都包含,但是它对于匹配文章帮助不大。这也如我们程序员所学的技术,对于程序员本身来说,这项技术掌握越深越好(掌握越深说明花时间看的越多,tf越大),找工作时越有竞争力。然而对于所有程序员来说,这项技术懂得的人越少越好(懂得的人少df小),找工作越有竞争力。人的价值在于不可替代性就是这个道理。
idf(t) = 1 + log (numDocs / (docFreq +1))
- t.getBoost,boost是人为给term提升权重的过程,我们可以在Index和Query中分别加入term boost,但是由于Query过程比较灵活,所以这里介绍给Query boost。term boost 不仅可以对Pharse进行,也可以对单个term进行,在查询的时候用^后面加数字表示:
- title:(solr in action)^2.5 对solr in action 这个pharse设置boost
- title:(solr in action) 默认的boost时1.0
- title:(solr^2in^.01action^1.5)^3OR"solrinaction"^2.5