***hibernate原理
1、通过 Configuration().configure();读取并解析 hibernate.cfg.xml 配置文件(读取并解析配置文件)。
2、由 hibernate.cfg.xml 中的<mappingresource="com/xx/User.hbm.xml"/>读取解析映射信息。
3、通过 config.buildSessionFactory();(创建 SessionFactory)。
4、sessionFactory.openSession();//得到 session(打开 Session)。
5、session.beginTransaction();//开启事务(创建事务 Transation)。
6、persistent operate;
7、session.getTransaction().commit();//提交事务
8、关闭 session;
9、关闭 sessionFactory;
说明:如果记不住代码,就回答后面的注释或者括号里面的内容就行了。
***简述 Hibernate 中对象的状态
结合下面一官方的图来说一下 Hibernate 的三种状态,临时态(瞬时态)Transient、持久态 Persistent、游离态(脱管态)Deatched。
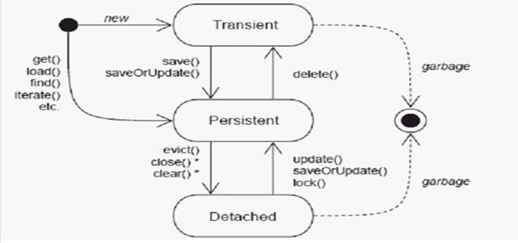
1、临时状态(transient):刚刚用 new 语句创建,还没有被持久化,不处于 Session的缓存中。处于临时状态的 Java 对象被称为临时对象。(和 Session 没有关联, 数据库中没有对应记录)
2、持久化状态(persistent):已经被持久化,加入到 Session 的缓存中。处于持久化状态的 Java 对象被称为持久化对象。(和 Session 有关联,数据库中有对应记录)
3、游离状态(detached):已经被持久化,但不再处于 Session 的缓存中。处于游离状态的 Java 对象被称为游离对象。(和 Session 没有关联,数据库中有对应记录)
***Load()和Get()的区别
Load 和 get 都是根据指定的实体类和 id 从数据库读取记录,并返回与之对应的实体对象,主要区别如下:
1、Load 支持延迟加载,而 Get 不支持延时加载。
2、对于 Get 方法,hibernate 会确认一下该 id 对应的数据是否存在,首先在session 缓存中查找,然后在二级缓存中查找,还没有就查询数据库,数据库中没有就返回 null。
3、对于 Load 方法,load 方法加载实体对象的时候,根据映射文件上类级别的lazy 属性的配置(默认为 true) (a)若为 true,则首先在 Session 缓存中查找,如果不存在则使用延迟加载,返回实体的代理类对象(该代理类为实体类的子类,由CGLIB 动态生成)。等到具体使用该对象(除获取 OID 以外)的时候,再查询二级缓存和数据库,若仍没发现符合条件的记录,则会抛出一个异常。(b)若为 false,就跟 get 方法查找顺序一样,只是最终若没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
***hibernate的缓存机制
一级缓存:一级缓存也叫 session 级缓存或事务级缓存,一级缓存的生命周期和 Session 的生命周期一致,也就是当 session 关闭时缓存即被清除,一级缓存在 Hibernate 中是不可配置的,即不能被卸载。(Session 为应用程序提供了两个管理缓存的方法: evict(Object obj),从缓存中清除参数指定的持久化对象; clear(), 清空缓存中所有持久化对象。)
二级缓存:二级缓存也称进程级缓存或 SessionFactory 级缓存,二级缓存可以被所有的 session 共享,二级缓存的生命周期和 SessionFactory 的生命周期一致。二级缓存在 Hibernate 中是可以配置的,可以通过 class-cache 配置类粒度级别的缓存(class-cache 在 class 中数据发生任何变化的情况下自动更新),同时也可通过collection-cache 配置集合粒度级别的缓存(collection-cache 仅在 collection 中增加了元素或者删除了元素的情况下才自动更新,也就是当 collection 中元素发生值的变化的情况下它是不会自动更新的)。
查询缓存:查询缓存,查询的结果集也可以被缓存。只有当经常使用同样的参数进行查询时, 这才会有些用处。要使用查询缓存, 首先你必须打开它:hibernate.cache.use_query_cache true。该设置将会创建两个缓存区域 - 一个用于保存查询结果集(org.hibernate.cache.StandardQueryCache);另一个则用于保存最近查询的一系列表的时间戳(org.hibernate.cache.UpdateTimestampsCache)。请注意:在查询缓存中,它并不缓存结果集中所包含的实体的确切状态;它只缓存这些实体的标识符属性的值、以及各值类型的结果。所以查询缓存通常会和二级缓存一起使用。绝大多数的查询并不能从查询缓存中受益,所以 Hibernate 默认是不进行查询缓存的。如若需要进行缓存,请调用 Query.setCacheable(true)方法。这个调用会让查询在执行过程中时先从缓存中查找结果,并将自己的结果集放到缓存中去。查询缓存在 Hibernate 同样是可配置的,默认是关闭的。
扩展:二级缓存适合放哪些数据,不适合放哪些数据? 适合放二级缓存中的数据:
1) 很少被修改的数据
2) 不是很重要的数据,允许出现偶尔并发的数据
3) 不会被并发访问的数据
4) 常量数据
不适合存放到第二级缓存的数据:
1) 经常被修改的数据
2) 绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发
3) 与其他应用共享的数据。
***hibernate中悲观锁与乐观锁的区别
hibernate 中经常用到当多个线程对同一数据同时进行修改的时候, 会发生脏数据,造成数据的不一致性,解决办法是可以通过悲观锁和乐观锁来实现。
悲观锁:采用数据库自带的锁的机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据),系统谨慎的认为每个线程的操作都可能导致数据的不一致性,于是当前的线程进行加锁处理,其它线程阻塞,直到当前线程结束释放锁(数据库执行的语句应该是 select * from table where id.. for update 操作)。
乐观锁:悲观锁虽然能够很好的保证数据一致性,但由于会造成阻塞,系统性能很低;而乐观锁是 Hibernate 级别的锁,它是乐观派通常认为多个事务同时操纵同一数据的情况是很少的,因为根本不做数据库层次上的锁定,只是基于数据的版本标识实现应用程序级别上的锁定机制,能够更好的提高系统性能。
***hibernate中update()和 saveOrUpdate()的区别
update()和 saveOrUpdate()是用来对 Session 的 PO 进行状态管理的。
update()方法操作的对象必须是持久化了的对象。也就是说,如果此对象在数据库中不存在的话,就不能使用 update()方法。
saveOrUpdate()方法操作的对象既可以使持久化了的,也可以使没有持久化的对象。如果是持久化了的对象调用 saveOrUpdate()则会更新数据库中的对象;如果是未持久化的对象使用此方法,则 save 到数据库中。
***hibernate的优点和缺点
优点:
1、对象/关系数据库映射(ORM),是一种面向对象数据库操作,将开发人员从自己写 SQL 语句中解放出来,开发人员只要基于 API 对对象的操作,就可以完成数据库层的开发。降低了开发人员的要求,提高了开发和维护的效率。
2、低侵入性设计,Hibernate 的引入没有任何侵入性,不仅可以与 Web 应用简单集成,也可以直接与 APP 应用集成使用,不依赖服务器容器,测试方便, 可以随便通过 Junit,main 方法就能完成测试。
3、可移植性好,Hibernate 是基于配置开发,在对于不同的数据库进行切换时, 只要简单的修改配置就可以完成,性能很高。
4、Hibernate 实现了透明持久化:当保存一个对象时,这个对象不需要继承Hibernate 中的任何类、实现任何接口,只是个纯粹的单纯对象—称为 POJO 对象, 带有持久化状态的、具有业务功能的单线程对象,此对象生存期很——这些对象唯一特殊的是他们正与(仅仅一个)Session 相关联。一旦这个 Session 被关闭, 这些对象就会脱离持久化状态,这样就可被应用程序的任何层自由使用。
5、缓存机制,大大提高了 Hibernate 执行效率。
缺点:
1、Hibernate 的开发成本低,但学习成本高;Hibernate 对开发人员的要求很高,尤其在复杂的关联关系,延迟策略等开发上,很注重开发人员的能力修为。
2、维护成本高,由于 Hibernate 对 SQL 的操作是基于对象的,而 SQL 的生成机制我们很少关心,尤其是复杂对象引用嵌套时,生成 SQL 会很复杂,但运维出现问题时,你会发现跟踪问题很麻烦,有时间想找一条合适的 SQL 都很麻烦。
3、应用层次优化很难,JDBC 开发时我们可以自己来优化 SQL,Hibernate 在这块想提高性能优化是不容易实现的。
4、批量操作不容易,而且调用过程、函数等也不如 JDBC 方便。