本系列文章经补充和完善,已修订整理成书《Java编程的逻辑》,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http://item.jd.com/12299018.html

栈
上节我们介绍了函数的基本概念,在最后我们提到了一个系统异常java.lang.StackOverflowError,栈溢出错误,要理解这个错误,我们需要理解函数调用的实现机制。本节就从概念模型的角度谈谈它的基本原理。
我们之前谈过程序执行的基本原理:CPU有一个指令指示器,指向下一条要执行的指令,要么顺序执行,要么进行跳转(条件跳转或无条件跳转)。
基本上,这依然是成立的,程序从main函数开始顺序执行,函数调用可以看做是一个无条件跳转,跳转到对应函数的指令处开始执行,碰到return语句或者函数结尾的时候,再执行一次无条件跳转,跳转回调用方,执行调用函数后的下一条指令。
但这里面有几个问题:
- 参数如何传递?
- 函数如何知道返回到什么地方?在if/else, for中,跳转的地址都是确定的,但函数自己并不知道会被谁调用,而且可能会被很多地方调用,它并不能提前知道执行结束后返回哪里。
- 函数结果如何传给调用方?
解决思路是使用内存来存放这些数据,函数调用方和函数自己就如何存放和使用这些数据达成一个一致的协议或约定。这个约定在各种计算机系统中都是类似的,存放这些数据的内存有一个相同的名字,叫栈。
栈是一块内存,但它的使用有特别的约定,一般是先进后出,类似于一个桶,往栈里放数据,我们称为入栈,最下面的我们称为栈底,最上面的我们称为栈顶,从栈顶拿出数据,通常称为出栈。栈一般是从高位地址向低位地址扩展,换句话说,栈底的内存地址是最高的,栈顶的是最小的。
计算机系统主要使用栈来存放函数调用过程中需要的数据,包括参数、返回地址,函数内定义的局部变量也放在栈中。计算机系统就如何在栈中存放这些数据,调用者和函数如何协作做了约定。返回值不太一样,它可能放在栈中,但它使用的栈和局部变量不完全一样,有的系统使用CPU内的一个存储器存储返回值,我们可以简单认为存在一个专门的返回值存储器。 main函数的相关数据放在栈的最下面,每调用一次函数,都会将相关函数的数据入栈,调用结束会出栈。
以上描述可能有点抽象,我们通过一个例子来说明。
一个简单的例子
我们从一个简单例子开始,下面是代码:
1 public class Sum { 2 3 public static int sum(int a, int b) { 4 int c = a + b; 5 return c; 6 } 7 8 public static void main(String[] args) { 9 int d = Sum.sum(1, 2); 10 System.out.println(d); 11 } 12 13 }
这是一个简单的例子,main函数调用了sum函数,计算1和2的和,然后输出计算结果,从概念上,这是容易理解的,让我们从栈的角度来讨论下。
当程序在main函数调用Sum.sum之前,栈的情况大概是这样的:

主要存放了两个变量args和d。在程序执行到Sum.sum的函数内部,准备返回之前,即第5行,栈的情况大概是这样的:
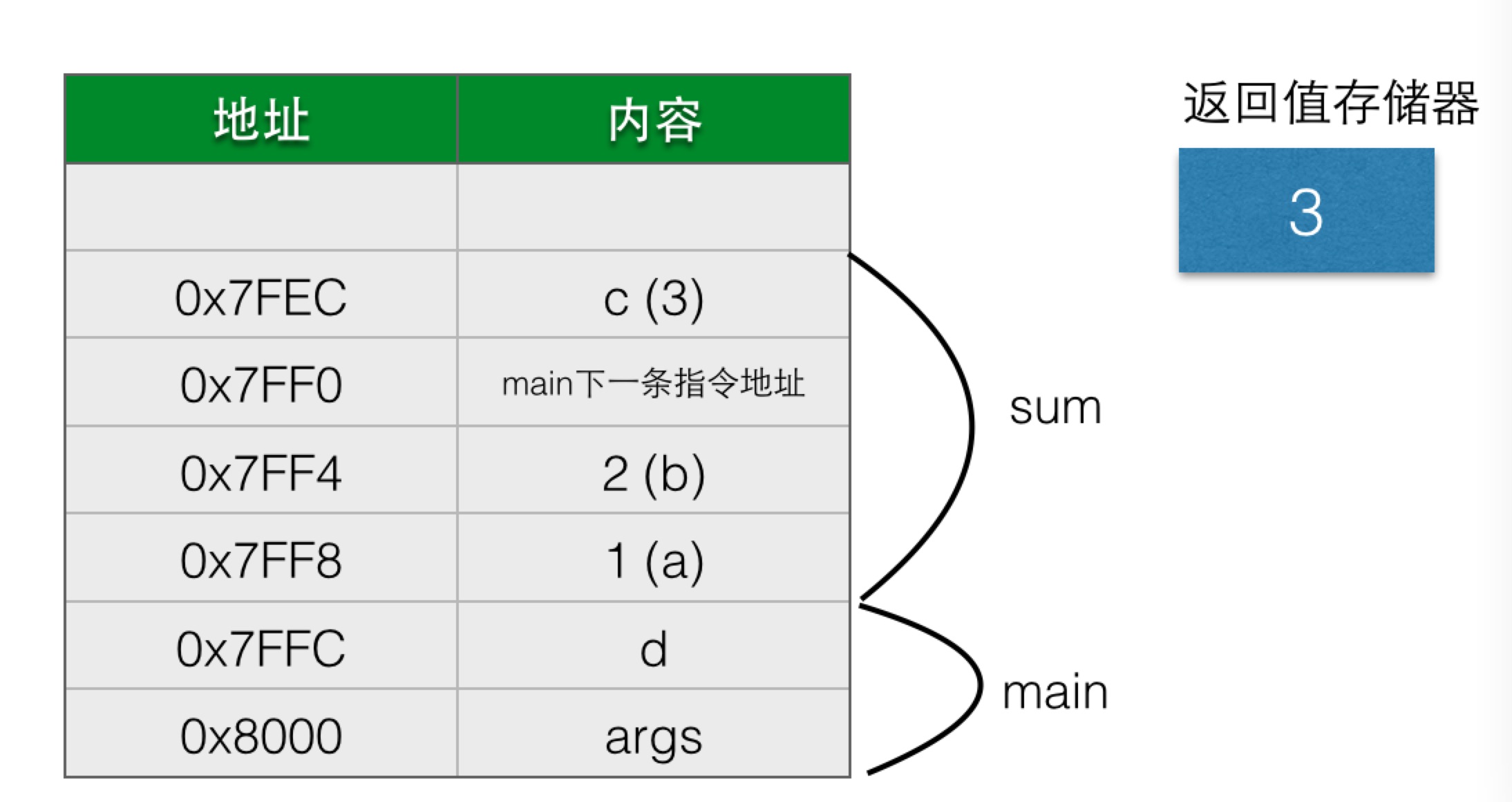
我们解释下,在main函数调用Sum.sum时,首先将参数1和2入栈,然后将返回地址(也就是调用函数结束后要执行的指令地址)入栈,接着跳转到sum 函数,在sum函数内部,需要为局部变量c分配一个空间,而参数变量a和b则直接对应于入栈的数据1和2,在返回之前,返回值保存到了专门的返回值存储器 中。
在调用return后,程序会跳转到栈中保存的返回地址,即main的下一条指令地址,而sum函数相关的数据会出栈,从而又变回下面这样:
main的下一条指令是根据函数返回值给变量d赋值,返回值从专门的返回值存储器中获得。
函数执行的基本原理,简单来说就是这样。但有一些需要介绍的点,我们讨论一下。
变量的生命周期
我们在第一节的时候说过,定义一个变量就会分配一块内存,但我们并没有具体谈什么时候分配内存,具体分配在哪里,什么时候释放内存。
从以上关于栈的描述我们可以看出,函数中的参数和函数内定义的变量,都分配在栈中,这些变量只有在函数被调用的时候才分配,而且在调用结束后就被释放了。但这个说法主要针对基本数据类型,接下来我们谈数组和对象。
数组和对象
对于数组和对象类型,我们介绍过,它们都有两块内存,一块存放实际的内容,一块存放实际内容的地址,实际的内容空间一般不是分配在栈上的,而是分配在堆(也是内存的一部分,后续文章介绍)中,但存放地址的空间是分配在栈上的。
我们来看个例子,下面是代码:
public class ArrayMax { public static int max(int min, int[] arr) { int max = min; for(int a : arr){ if(a>max){ max = a; } } return max; } public static void main(String[] args) { int[] arr = new int[]{2,3,4}; int ret = max(0, arr); System.out.println(ret); } }
这个程序也很简单,main函数新建了一个数组,然后调用函数max计算0和数组中元素的最大值,在程序执行到max函数的return语句之前的时候,内存中栈和堆的情况大概是这样的:
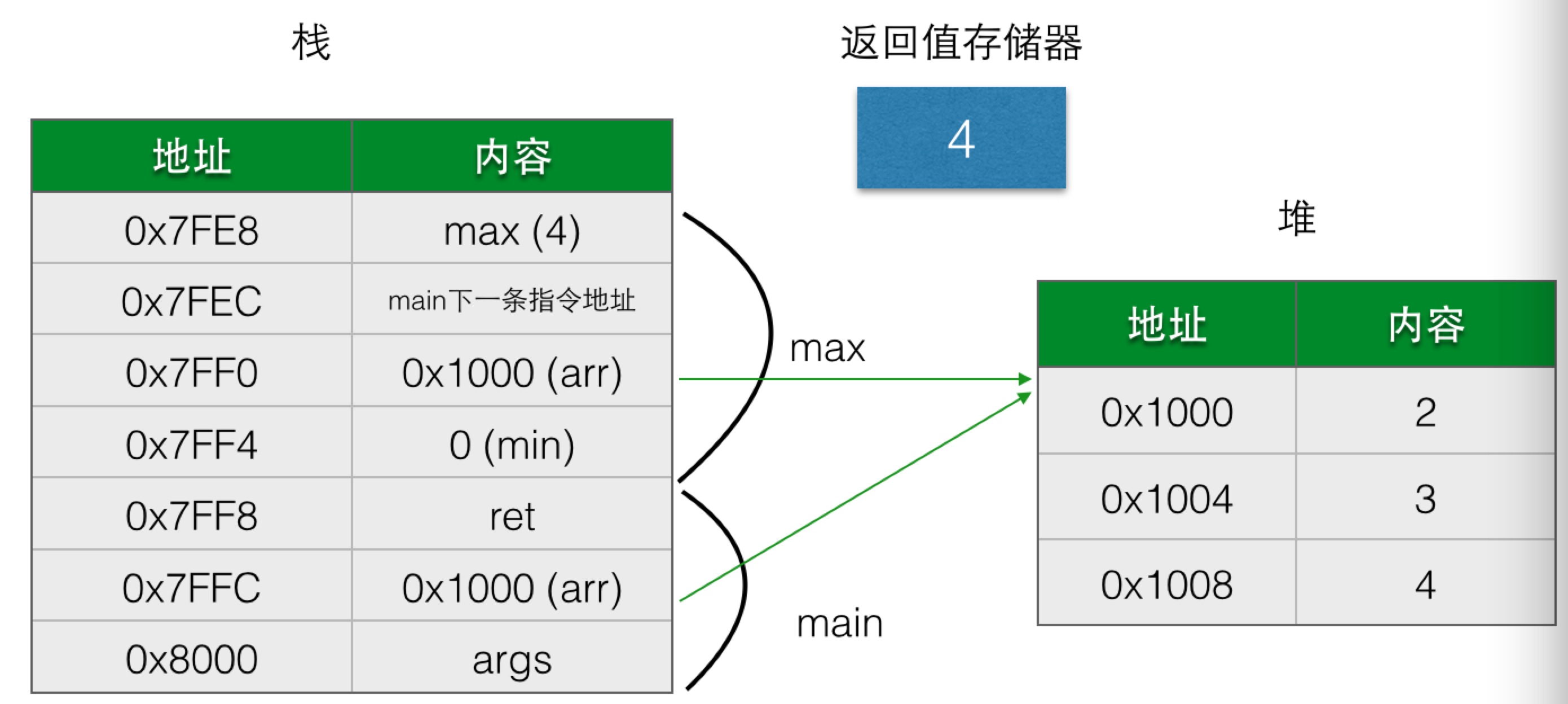
对于数组arr,在栈中存放的是实际内容的地址0x1000,存放地址的栈空间会随着入栈分配,出栈释放,但存放实际内容的堆空间不受影响。
但说堆空间完全不受影响是不正确的,在这个例子中,当main函数执行结束,栈空间没有变量指向它的时候,Java系统会自动进行垃圾回收,从而释放这块空间。
递归调用
我们再通过栈的角度来理解一下递归函数的调用过程,代码如下:
public static int factorial(int n) { if(n==0){ return 1; }else{ return n*factorial(n-1); } } public static void main(String[] args) { int ret = factorial(4); System.out.println(ret); }
在factorial第一次被调用的时候,n是4,在执行到 n*factorial(n-1),即4*factorial(3)之前的时候,栈的情况大概是:
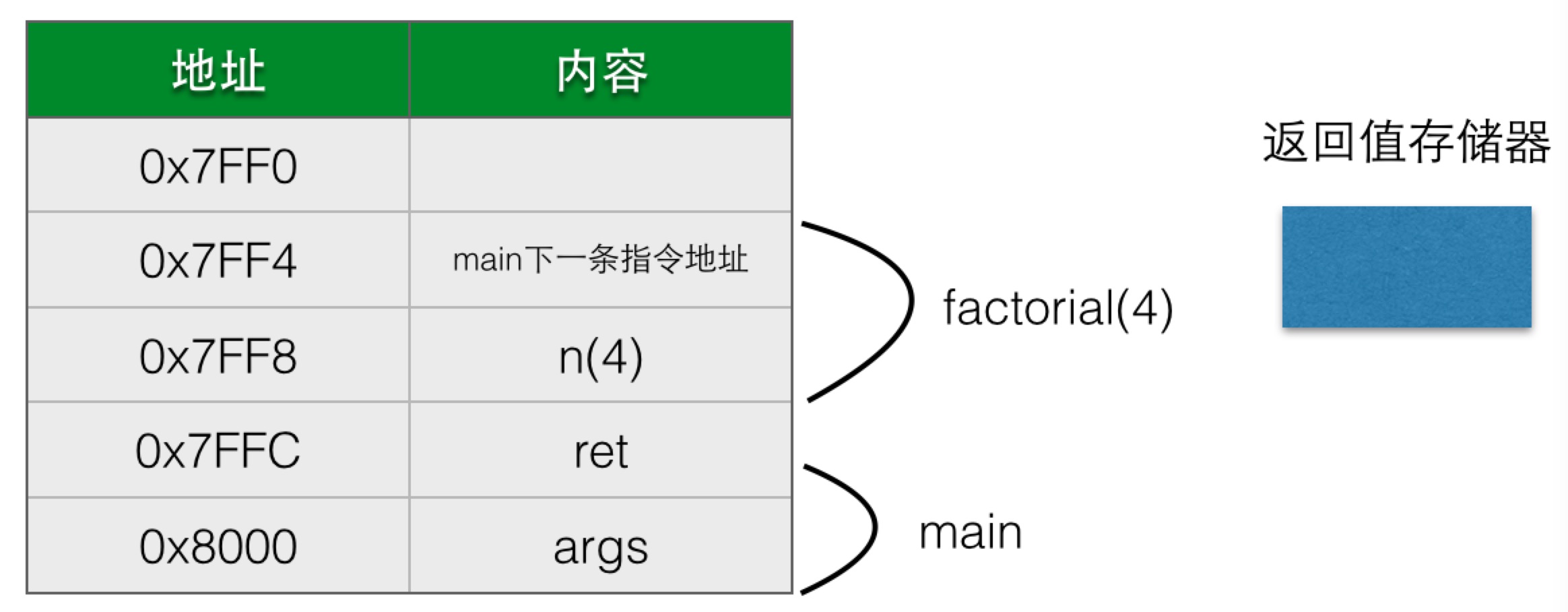
注意返回值存储器是没有值的,在调用factorial(3)后,栈的情况变为了:
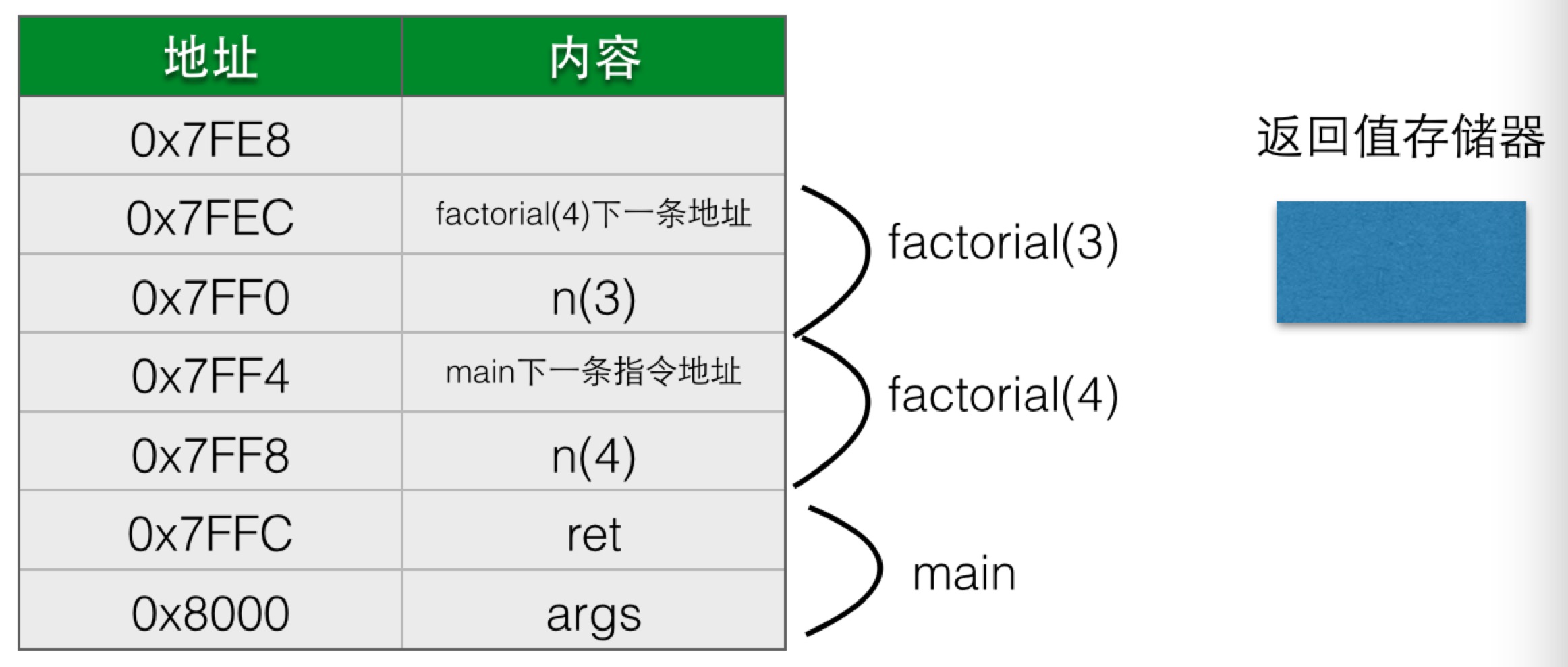
栈的深度增加了,返回值存储器依然为空,就这样,每递归调用一次,栈的深度就增加一层,每次调用都会分配对应的参数和局部变量,也都会保存调用的返回地址,在调用到n等于0的时候,栈的情况是:
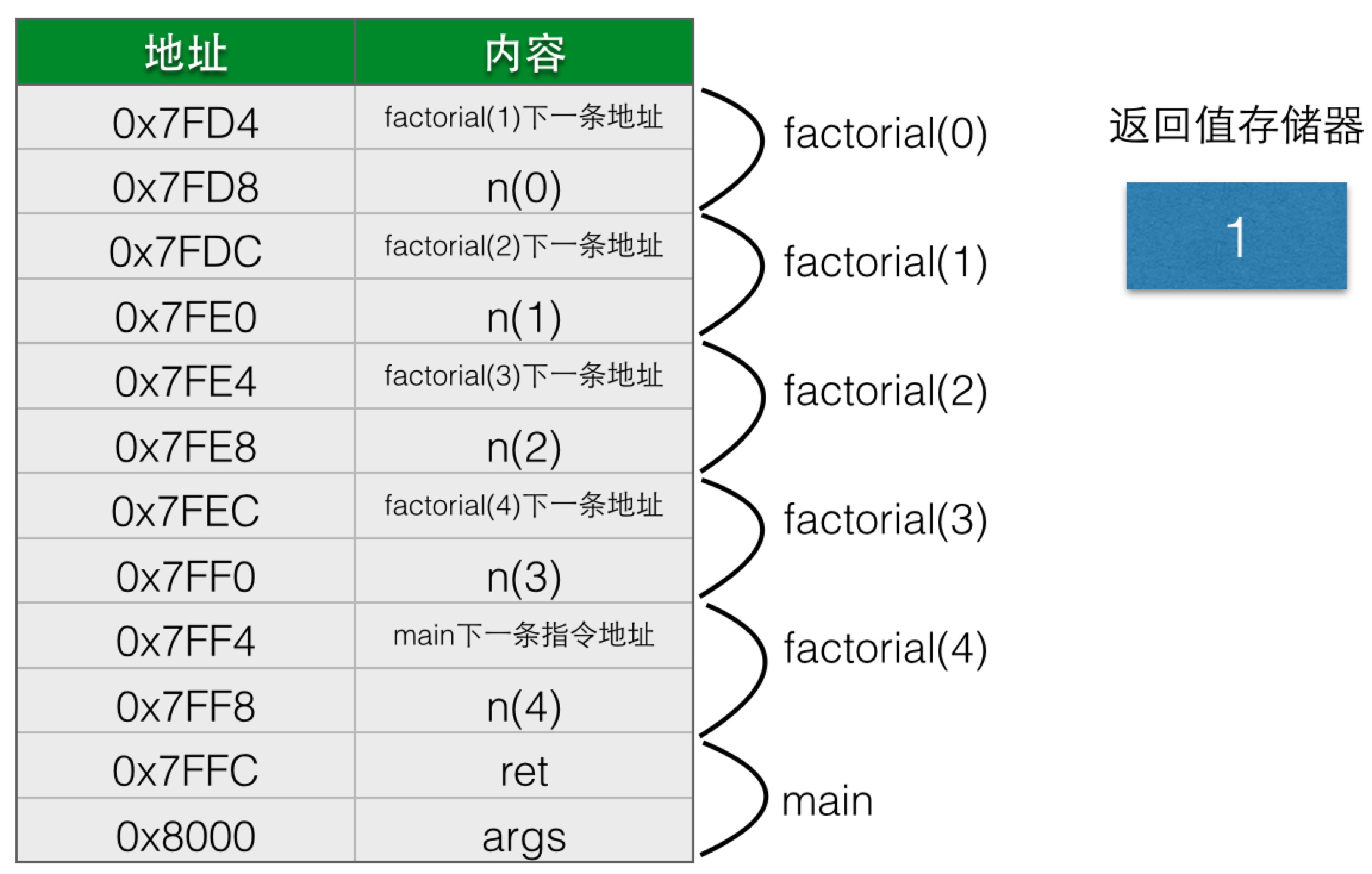
这个时候,终于有返回值了,我们将factorial简写为f。f(0)的返回值为1,f(0)返回到f(1),f(1)执行1*f(0),结果也是1,然
后返回到f(2),f(2)执行2*f(1),结果是2,然后接着返回到f(3),f(3)执行3*f(2),结果是6,然后返回到f(4),执行
4*f(3),结果是24。
以上就是递归函数的执行过程,函数代码虽然只有一份,但在执行的过程中,每调用一次,就会有一次入栈,生成一份不同的参数、局部变量和返回地址。
函数调用的成本
从函数调用的过程我们可以看出,调用是有成本的,每一次调用都需要分配额外的栈空间用于存储参数、局部变量以及返回地址,需要进行额外的入栈和出栈操作。
在递归调用的情况下,如果递归的次数比较多,这个成本是比较可观的,所以,如果程序可以比较容易的改为别的方式,应该考虑别的方式。
另外,栈的空间不是无限的,一般正常调用都是没有问题的,但像上节介绍的例子,栈空间过深,系统就会抛出错误,java.lang.StackOverflowError,即栈溢出。
小结
本节介绍了函数调用的基本原理,函数调用主要是通过栈来存储相关数据的,系统就函数调用者和函数如何使用栈做了约定,返回值我们简化认为是通过一个专门的返回值存储器存储的,我们主要从概念上介绍了其基本原理,忽略了一些细节。
在本节中,我们假设函数的修饰符都是public static,如果不是static的,则会略有差别,后续文章会介绍。
我们谈到,在Java中,函数必须放在类中,目前我们简化认为类只是函数的容器,但类在Java中远不止有这个功能,它还承载了很多概念和思维方式,在接下来的几节中,让我们一起来探索类的世界。
----------------
未完待续,查看最新文章,敬请关注微信公众号“老马说编程”(扫描下方二维码),从入门到高级,深入浅出,老马和你一起探索Java编程及计算机技术的本质。原创文章,保留所有版权。

-----------
更多相关原创文章