1. 下载Spark
1.1 官网下载Spark
http://spark.apache.org/downloads.html
打开上述链接,进入到下图,点击红框下载Spark-2.2.0-bin-hadoop2.7.tgz,如下图所示:

2. 安装Spark
Spark安装,分为:
- 准备,包括上传到主节点,解压缩并迁移到/opt/app/目录;
- Spark配置集群,配置/etc/profile、conf/slaves以及confg/spark-env.sh,共3个文件,配置完成需要向集群其他机器节点分发spark程序,
- 直接启动验证,通过jps和宿主机浏览器验证
- 启动spark-shell客户端,通过宿主机浏览器验证
2.1 上传并解压Spark安装包
1. 把spark-2.2.0-bin-hadoop2.7.tgz通过Xftp工具上传到主节点的/opt/uploads目录下
2. 在主节点上解压缩
# cd /opt/uploads/
# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz

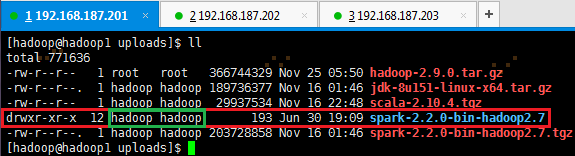
有时解压出来的文件夹,使用命令 ll 查看用户和用户组有可能不是hadoop时,即上图绿框显示,则需要使用如下命令更换为hadoop用户和用户组:
# sudo chown hadoop:hadoop spark-2.2.0-bin-hadoop2.7
3. 把spark-2.2.0-bin-hadoop2.7移到/opt/app/目录下
# mv spark-2.2.0-bin-hadoop2.7 /opt/app/
# cd /opt/app && ll

2.2 配置文件与分发程序
2.2.1 配置/etc/profile
1. 以hadoop用户打开配置文件/etc/profile
# sudo vi /etc/profile

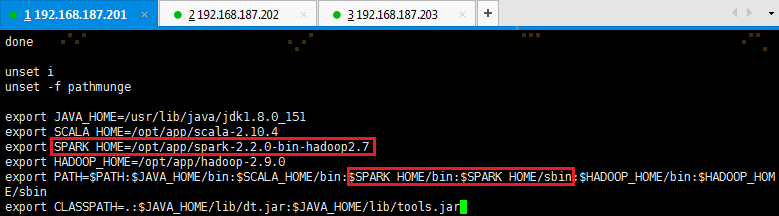
2. 定义SPARK_HOME并把spark路径加入到PATH参数中
export SPARK_HOME=/opt/app/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
2.2.2 配置conf/slaves
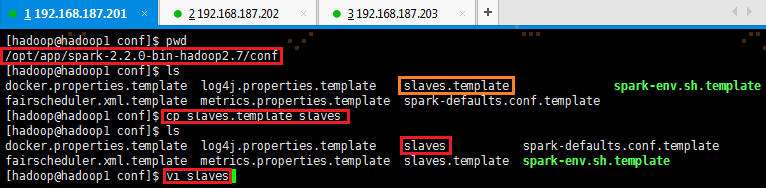
1. 打开配置文件conf/slaves,默认情况下没有slaves,需要使用cp命令复制slaves.template
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/conf 如果不在/opt/app/spark-2.2.0-bin-hadoop2.7目录下,则使用该命令
# cp slaves.template slaves
# sudo vi slaves
2. 加入slaves配置节点
hadoop1
hadoop2
hadoop3

2.2.3 配置conf/spark-env.sh
1. 以hadoop用户,使用如下命令,打开配置文件spark-env.sh
# cd /opt/app/spark-2.2.0-bin-hadoop2.7 如果不在/opt/app/spark-2.2.0-bin-hadoop2.7目录下,则使用该命令
# cp spark-env.sh.template spark-env.sh
# vi spark-env.sh

2. 加入如下环境配置内容,设置hadoop1为Master节点:
export JAVA_HOME=/usr/lib/java/jdk1.8.0_151
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=900M
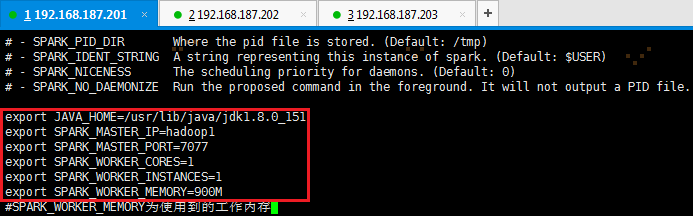
【注意】:SPARK_WORKER_MEMORY为计算时使用的内存,设置的值越低,计算越慢,反之亦然。
2.2.4 向各节点分发Spark程序
1. 进入hadoop1机器/opt/app/目录,使用如下命令把spark文件夹复制到hadoop2和hadoop3机器
# cd /opt/app
# scp -r spark-2.2.0-bin-hadoop2.7 hadoop@hadoop2:/opt/app/
# scp -r spark-2.2.0-bin-hadoop2.7 hadoop@hadoop3:/opt/app/


2. 在从节点查看是否复制成功

2.3 启动Spark
1. 启动Spark
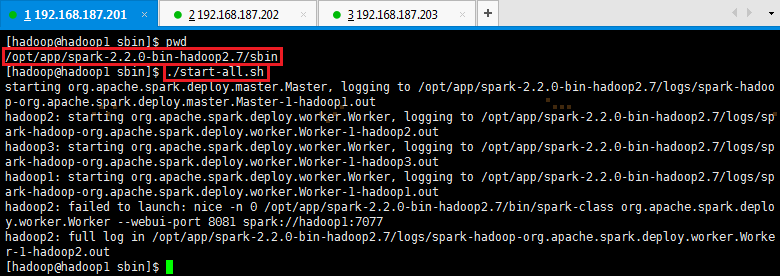
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/sbin
# ./start-all.sh
2. 验证启动
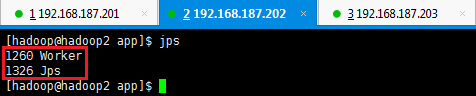
此时在hadoop1上面运行的进程有:Worker和Master
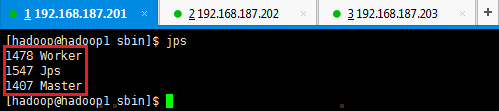
此时在hadoop2和hadoop3上面运行的进程有Worker

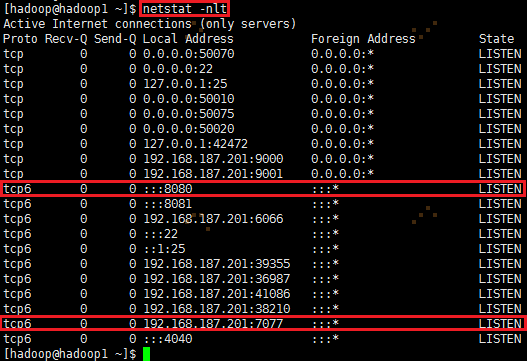
通过netstat -nlt 命令查看hadoop1节点网络情况
在浏览器中输入http://hadoop1:8080,即可以进入Spark集群状态页面(windows防火墙打开,会导致直接访问有问题,看下述步骤)
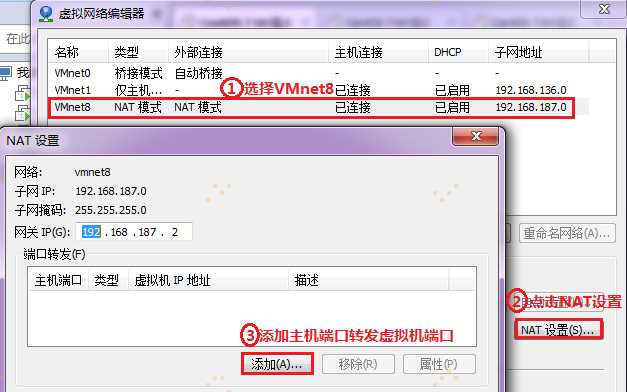
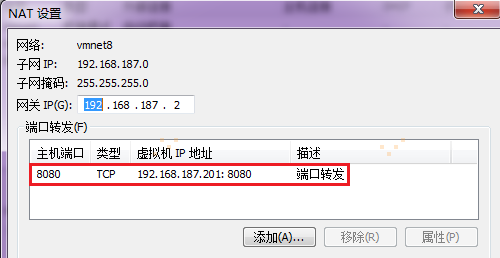
【注意】:在宿主机浏览器上,直接访问(192.168.187.201)hadoop1:8080,会报错(有很大可能是windows防火墙屏蔽了端口,可以通过关闭windows防火墙解决不能直接访问的问题)。下面是通过宿主机端口转移来达到间接访问的目的:要想通过宿主机浏览器,访问(192.168.187.201)hadoop1:8080,需要把宿主机端口与访问的虚拟机端口进行关联配置,通过访问宿主机端口来达到访问虚拟机端口的目的,如图所示:
首先,点击VMware的菜单栏编辑里面的虚拟网络编辑器:
然后,进行下述操作:
接着跳转到映射传入端口窗口,如下:

最后完成,如下。
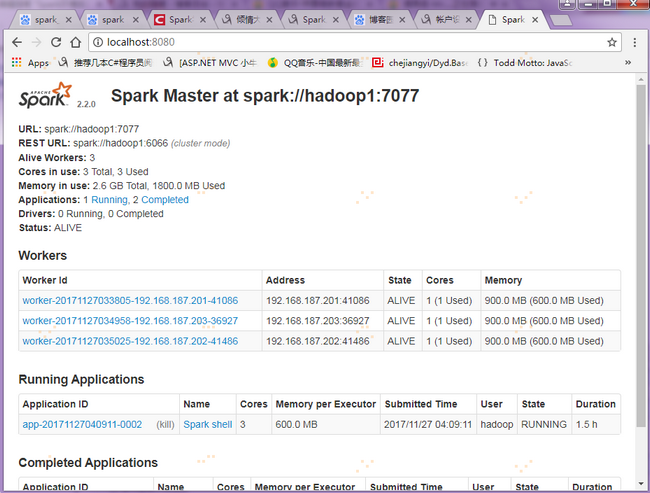
验证,在宿主机浏览器上输入localhost:8080,映射到hadoop1:8080,即可访问Spark集群状态
2.4 验证客户端连接
1. 进入hadoop1节点,进入spark的bin目录,使用spark-shell连接集群
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/bin
# spark-shell --master spark://hadoop1:7077 --executor-memory 600m
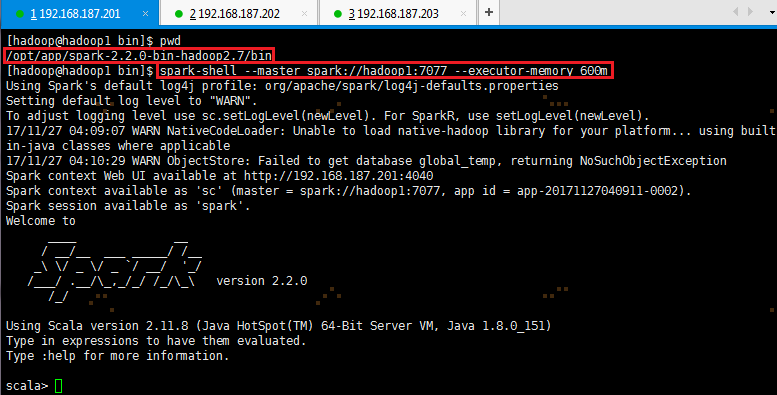
在命令中只指定了内存大小并没有指定核数,所以该客户端将占用该集群所有核并在每个节点分配600M内存
2. 查看Spark集群状态,通过上一步骤【注意】的IP端口映射设置,在宿主机浏览器输入localhost:8080,可以会直接映射到(192.168.187.201)hadoop1:8080上,如图:
