1. 任务概述
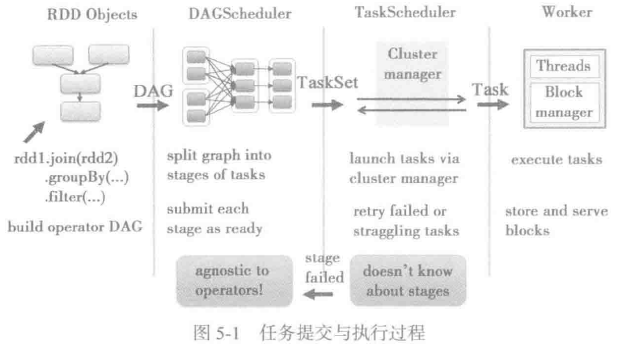
任务提交与执行过程:
1) build operator DAG:此阶段主要完成RDD的转换及DAG的构建;
2) split graph into stages of tasks:此阶段主要完成finalStage的创建与Stage的划分,做好Stage与Task的准备工作后,最后提交Stage与Task;
3) launch tasks via cluster manager:使用集群管理器(Cluster manager)分配资源与任务调度,对于失败的任务还会有一定的重试与容错机制;
4) execute tasks:执行任务,并将任务中间结果和最终结果存入存储体系
2 广播Hadoop的配置信息
SparkContext的broadcast方法用于广播Hadoop的配置信息,其实现见代码如下:

上面的代码通过使用BroadcastManager发送广播,广播结束将广播对象注册到ContextCleaner中,以便清理。BroadcastManager的newBroadcast方法实际代理了broadcastFactory的newBroadcast方法。而在BroadcastManager类初始化initialize方法里面创建TorrentBroadcastFactory,它实际上是broadcastFactory的子类,broadcastFactory的newBroadcast方法实际上调用了TorrentBroadcastFactory的生成newBroadcast方法生成TorrentBroadcast对象的代码如下:
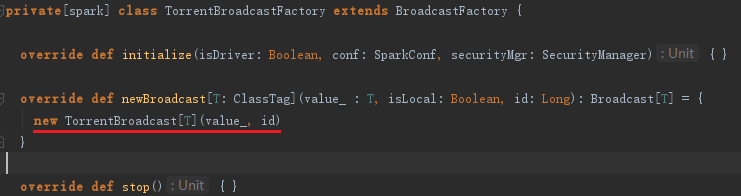
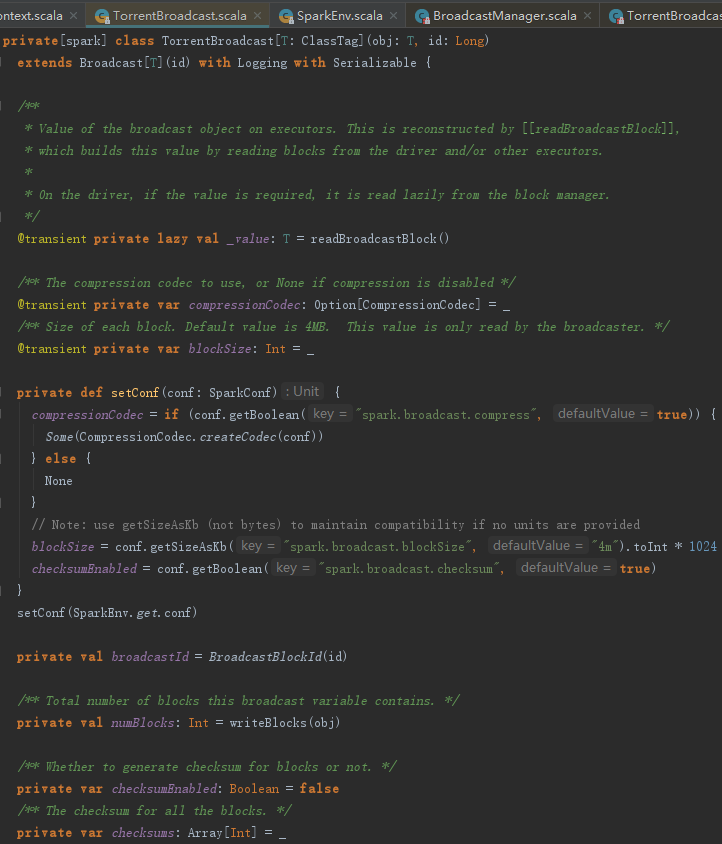
从下述代码中可以看到TorrentBroadcast的过程分为三步:
1) 设置广播配置信息。根据spark.broadcast.compress配置属性确认是否对广播消息进行压缩,并且生成CompressionCodec对象。根据spark.broadcast.blockSize配置属性确认块的大小,默认为4MB。
2) 生成BroadcastBlockId。
3) 块的写入操作,返回广播变量包含的块数。
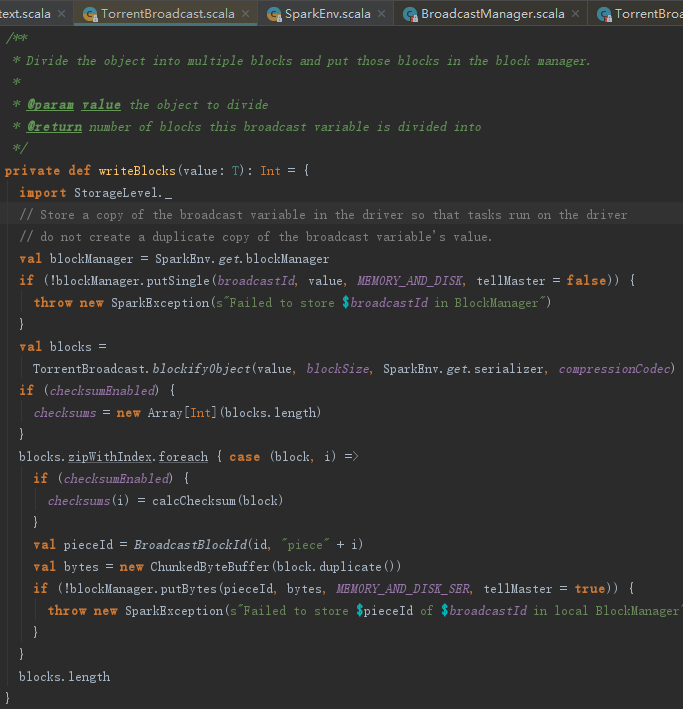
块的写入操作writeBlocks
从下述代码中,看到块写入操作writeBlocks的工作分三步:
1) 将要写入的对象在本地的存储体系中备份一份,以便于Task也可以在本地的Driver上运行;
2) 给ByteArrayChunkOutputStream指定压缩算法,并且将对象以序列化方式写入ByteArrayChunkOutputStream后转换为Array[ByteBuffer];
3) 将每一个ByteBuffer作为一个Block,使用putBytes方法写入存储体系;
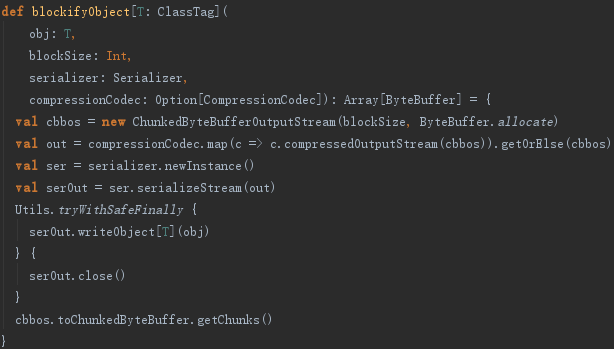
TorrentBroadcast.blockifyObject方法用于将对象序列化写入ByteArrayChunkOutputStream,并用CompressionCodec压缩,最终将ByteArrayChunkOutputStream转换为Array[ByteBuffer]。blockifyObject的实现如下:
3. RDD转换及DAG构建
3.1 为什么需要RDD
以下从数据处理模型、依赖划分原则、数据处理效率及容错处理4个方面解释Spark发明RDD的原因。
1. 数据处理模型
RDD是一个容错的、并行的数据结构,可以控制将数据存储到磁盘或内存,能够获取数据的分区。RDD提供了一组类似于Scala的操作,比如map、flatMap、filter等,这些操作实际是对RDD进行转换(transformation)。此外,RDD还提供了join、groupBy、reduceByKey等操作完成数据计算(注意:reduceByKey是action,而非transformation)。
当前的大数据应用场景非常丰富,如流式计算、图计算、机器学习等。它们既有相似之处,又各有不同。为了能够对所有场景下的数据处理使用统一的方式,抽象出RDD这一模型。
通常数据处理的模型包括:迭代计算、关系查询、MapReduce、流式处理等。Hadoop采用MapReduce模型,Storm采用流式处理模型,而Spark则实现了以上所有模型。
2. 依赖划分原则
一个RDD包含一个或多个分区,每个分区实际是一个数据集合的片段。在构建DAG的过程中,会将RDD用依赖关系串联起来。每个RDD都有其依赖(除了最顶级RDD的依赖是空列表),这些依赖分为NarrowDependency和ShuffleDependency两种。为什么要对依赖进行区分?从功能角度讲它们是不一样的。NarrowDependency会被划分到同一Stage中,这样它们就能以管道的方式迭代执行。ShuffleDependency由于依赖的上游RDD不止一个,所以往往需要跨节点传输数据。从容灾角度讲,它们恢复计算结果的方式不同。NarrowDependency只需要重新执行父RDD的丢失分区的计算即可恢复。而ShuffleDependency则需要考虑恢复所有父RDD的丢失分区。
解释了依赖划分的原因,实际也解释了为什么要划分Stage这个问题。
3. 数据处理效率
ShuffleDependency所依赖的上游RDD的计算过程允许在多个节点并发执行,如图所示,实际也就是后面将会讲到的ShuffleMapTask在多个节点上的多个实例。如果数据量很大,可以适当增加分区数量,这种根据硬件条件对并发任务数量的控制,能更好地利用各种资源,也能有效提高Spark的数据处理效率。
4. 容错处理
传统关系型数据库往往采用日志记录的方式来容灾容错,数据恢复都依赖于重新执行日志中的SQL。Hadoop为了避免单机故障概率较高的问题,通过将数据备份到其他机器容灾。由于所有备份机器同时出故障的概率比单机故障概率低很多,从而在宕机等问题发生时,从备份机读取数据。RDD本身是一个不可变的(Scala中称为immutable)数据集,当某个Worker节点上的任务失败时,可以利用DAG重新调度计算这个失败的任务。由于不用复制数据,也大大降低了网络通信。在流式计算的场景中,Spark需要记录日志和检查点(CheckPoint),以便利用CheckPoint和日志对数据进行恢复。
3.2 RDD实现分析
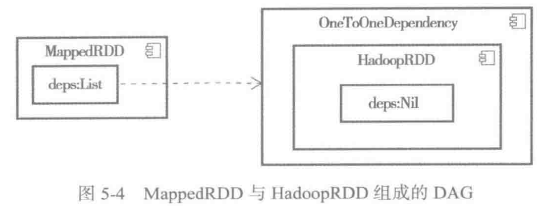
HadoopRDD的DAG。
hadoopFile方法创建完HadoopRDD后,会调用RDD的map方法。map方法将HadoopRDD封装为MappedRDD。
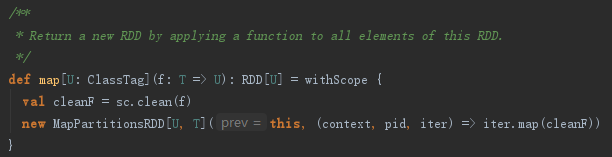
这里调用了SparkContext的clean方法,实现如下:
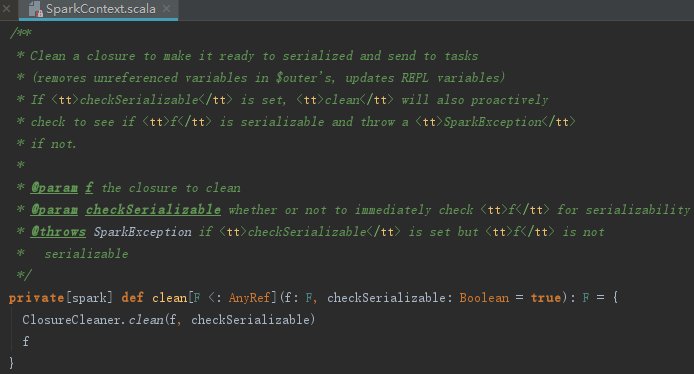
clean方法实际调用了ClosureCleaner的clean方法,这里意在清除闭包中的不能序列化的变量,防止RDD在网络传输过程中反序列化失败。
构造MapPartitionsRDD的步骤如下:
1) 调用MapPartitionsRDD的父类RDD的辅助构造器,RDD的辅助构造器如下:

辅助构造器首先将oneParent封装为OneToOneDependency,OneToOneDependency继承自NarrowDependency,其实现如下:

2) 调用RDD的主构造器,主构造器实现如下:
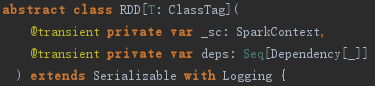
构建完MapPartitionsRDD后,此时的DAG如图所示:
MapPartitionsRDD在JavaSparkContext中会被隐式转换为JavaRDD。接着执行JavaRDD的flatMap方法,由于JavaRDD实现了JavaRDDLike特质,所以实际调用了JavaRDDLike的flatMap方法,它的实现如下:
略
此时,JavaRDD内部的rdd属性实质上还是MapPartitionsRDD,调用MapPartitionsRDD的构造器方法,其实现如下:

接着执行JavaRDD的mapToPair方法时,JavaRDD由于实现了JavaRDDLike特质,所以实际调用了JavaRDDLike的mapToPair方法,代码实现如下:
略
此时,JavaRDD内部的rdd属性实际上还是MapPartitions,此时调用RDD的map,又被封装为MapPartitionsRDD。
然后执行PairRDDFunctions的reduceByKey方法,其实现见代码如下:

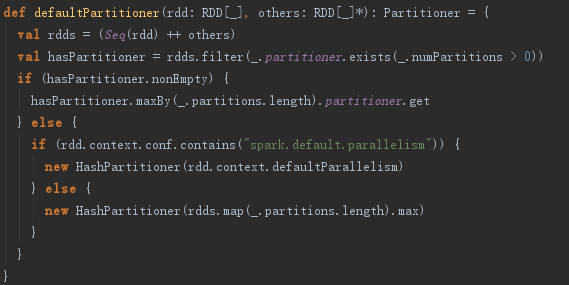
defaultPartitioner方法的实现见代码如下,其功能实现如下:
1) 将RDD转换为Seq,然后对Seq按照RDD的partitions_:Array[Partition]的size倒序排列。
2) 创建HashPartitioner对象。如果配置了spark.default.parallelism属性,则用此属性值作为分区数量。否则使用Seq中所有RDD的partitions函数返回值的最大值作为分区数量。
RDD的partitions方法的实现见代码如下:
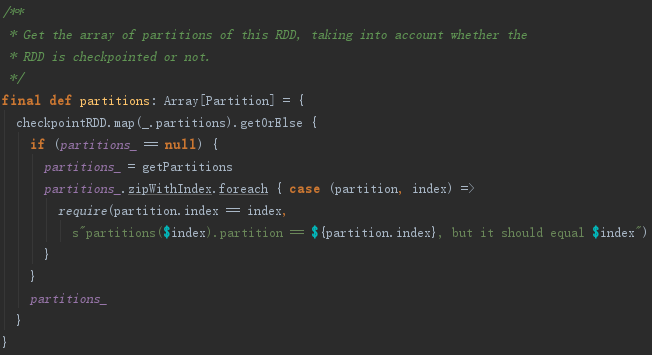
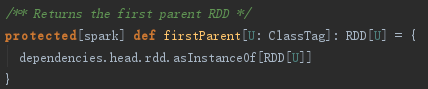
本例中,partitions方法实际调用了MapPartitionsRDD的getPartitions方法。MapPartitionsRDD的getPartitions方法调用了RDD的firstParent,见代码如下:

firstParent用于返回依赖的第一个父RDD,代码实现如下:
略
4. 任务提交
4.1 任务提交的准备
现在要执行JavaPairRDD的word count例子方法了。collect中调用了RDD的collect方法后转成Array,其代码实现如下:
略
RDD的collect方法调用了SparkContext的runJob,见代码如下:

SparkContext的runJob又调用了重载的runJob,见代码如下:

接着又调用两个重载的runJob,见代码如下:
最终调用的runJob方法里又一次调用clean方法防止闭包的反序列化错误,然后运行dagScheduler的runJob,见代码如下:
dagScheduler的runJob方法主要调用submitJob方法,之后的waiter.awaitResult()说明了任务的运行是异步的,见代码如下:
1. 提交Job
submitJob方法用来将一个Job提交到job scheduler,见代码如下:
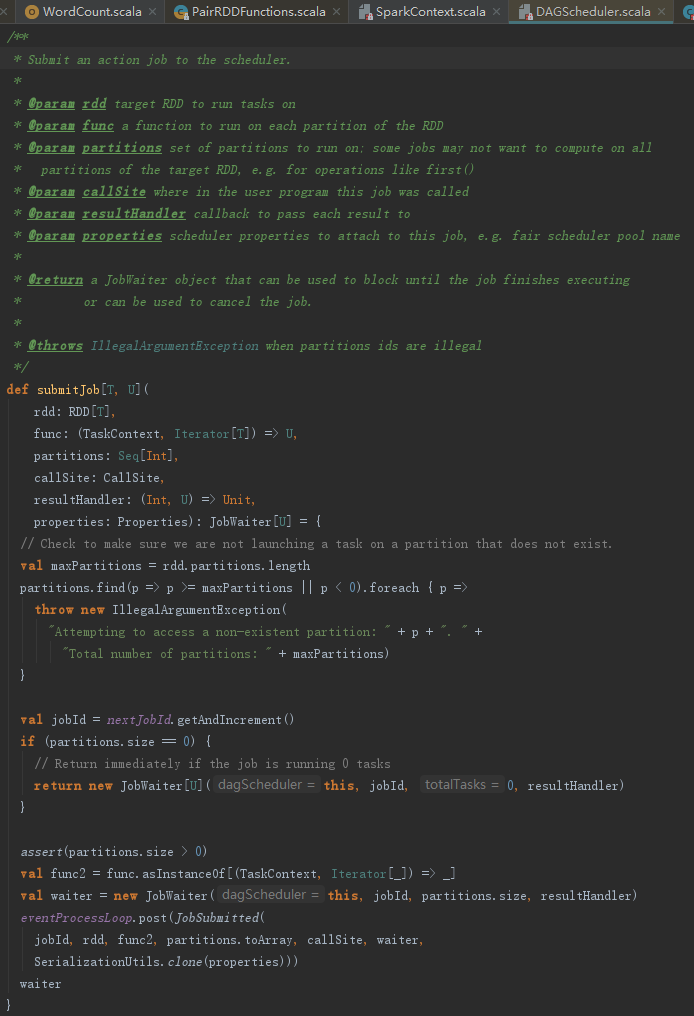
根据上述代码分析,submitJob的处理步骤如下:
1) 调用RDD的partitions函数来获取当前Job的最大分区数,即maxPartitions。根据maxPartitions,确认我们没有在一个不存在的partition上运行任务。
2) 生成当前Job的jobId。
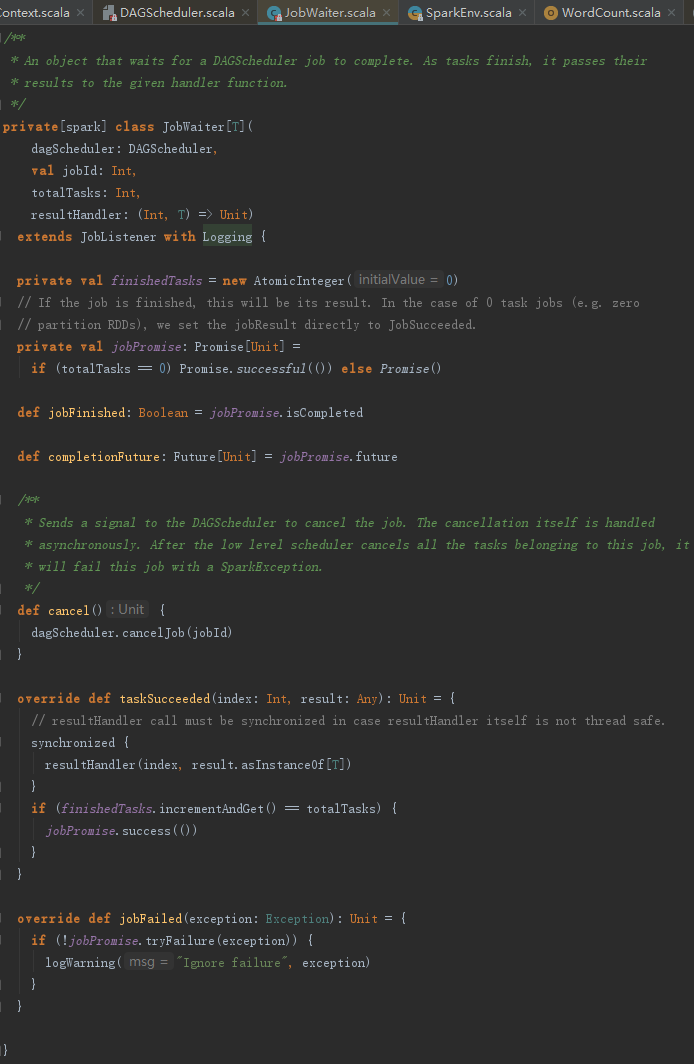
3) 创建JobWaiter,望文生义,即Job的服务员。此JobWaiter被阻塞,直到job完成或者被取消。
4) 向eventProcessLoop发送JobSubmitted事件。
5) 返回JobWaiter。
2. 处理Job提交
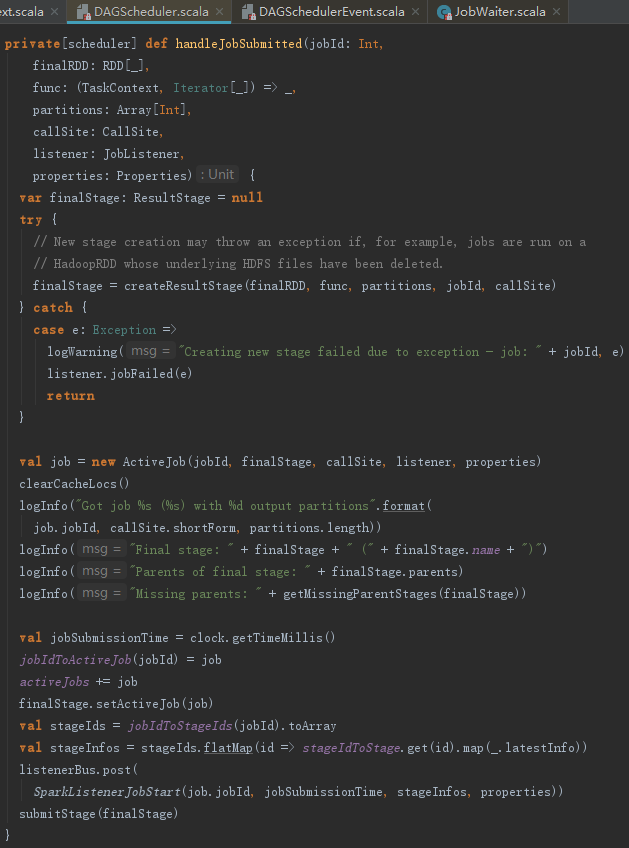
DAGSchedulerEventProcessLoop收到JobSubmitted事件,会调用dagScheduler的handleJobSubmitted方法。handleJobSubmitted的具体执行过程如下:
1) 创建finalStage及Stage的划分。创建Stage的过程可能发生异常。比如,运行在HadoopRDD上的任务所依赖的底层HDFS文件被删除了。所以当异常发生时需要主动调用JobWaiter的jobFailed方法。
2) 创建ActiveJob并更新jobIdToActiveJob = new HashMap[Int, ActiveJob]、activeJobs = new HashSet[ActiveJob] 和 finalStage.resultOfJob。
3) 向listenerBus发送SparkListenerJobStart事件。
4) 提交finalStage。
5) 提交等待中的Stage。
4.2 finalStage的创建与Stage的划分
在Spark中,一个Job可能被划分为一个或多个Stage,各个之间存在依赖关系,其中最下游的Stage也称为最终的Stage,用来处理Job最后阶段的工作。
1. createResultStage的实现分析
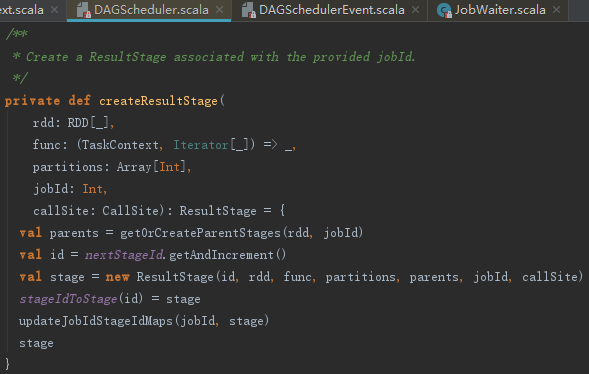
handleJobSubmitted方法使用createResultStage方法创建finalStage,createResultStage的处理步骤如下:
1) 调用getOrCreateParentStages获取所有的父Stage的列表,父Stage主要是宽依赖(如ShuffleDependency)对应的Stage,此列表内的Stage包含以下几种:
①当前RDD的直接或间接的依赖是ShuffleDependency且已经注册过的Stage。
②当前RDD的直接或间接的依赖是ShuffleDependency且没有注册过Stage的,则根据ShuffleDependency本身的RDD,找到它的直接或间接的依赖是ShuffleDependency且没有注册过Stage的所有ShuffleDependency,为他们生成Stage并注册。
③当前RDD的直接或间接的依赖是ShuffleDependency且没有注册过Stage的,为它们生成Stage且注册,最后也添加此Stage到List。
2) 生成Stage的Id,并创建Stage。
3) 将Stage注册到stageIdToStage = new HashMap[Int,Stage]中。
4) 调用updateJobIdStageIdMaps方法Stage及其祖先Stage与jobId的对应关系。
2. 获取父Stage列表
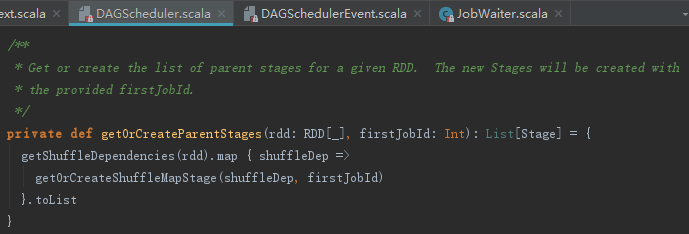
Spark中Job会被划分为一到多个Stage,这些Stage的划分是从finalStage开始,从后往前边划分边创建的。getOrCreateParentStages方法用于获取或者创建给定RDD的所有父Stage,这些Stage将被分配到jobId对应的job,其处理步骤如下:
1) 通过调用RDD的getShuffleDependencies方法获取RDD的所有Dependency的序列。
2) 逐个访问每个RDD及其依赖的非Shuffle的RDD,遍历每个RDD的ShuffleDependency依赖,并调用getOrCreateShuffleMapStage获取或者创建Stage,并将这些返回的Stage都放入parents:HashSet[Stage]。由此可见,Stage的划分是以ShuffleDependency为分界线的。
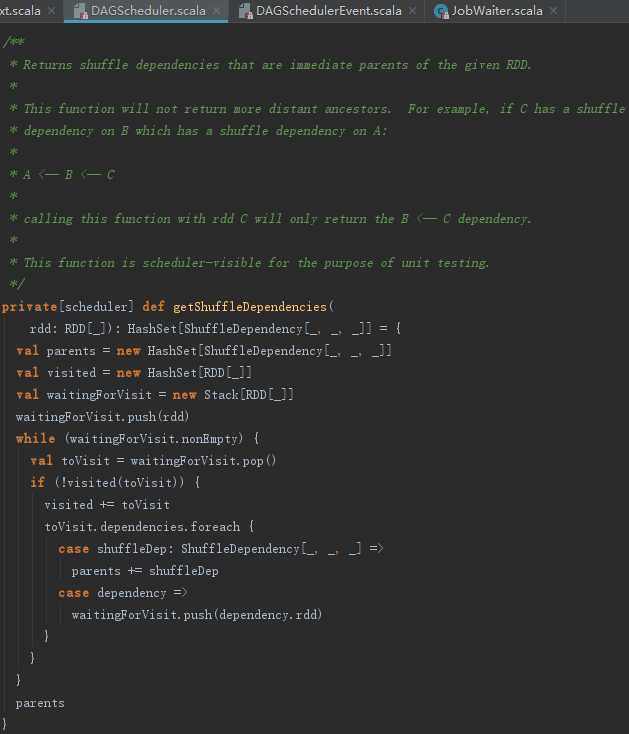
3. 获取map任务对应Stage
getOrCreateShuffleMapStage方法用于获取或者创建Stage并注册到shuffleToMapStage:HashMap[Int, Stage]中,处理步骤如下:
1) 如果已经注册了ShuffleDependency对应的Stage,则直接返回此Stage。
2) 否则调用getMissingAncestorShuffleDependencies方法找到所有祖先中,还没有为其注册过Stage的ShuffleDependency,调用方法createShuffleMapStage创建Stage并注册。最后还会为当前ShuffleDependency,调用方法createShuffleMapStage创建、注册并返回此Stage。
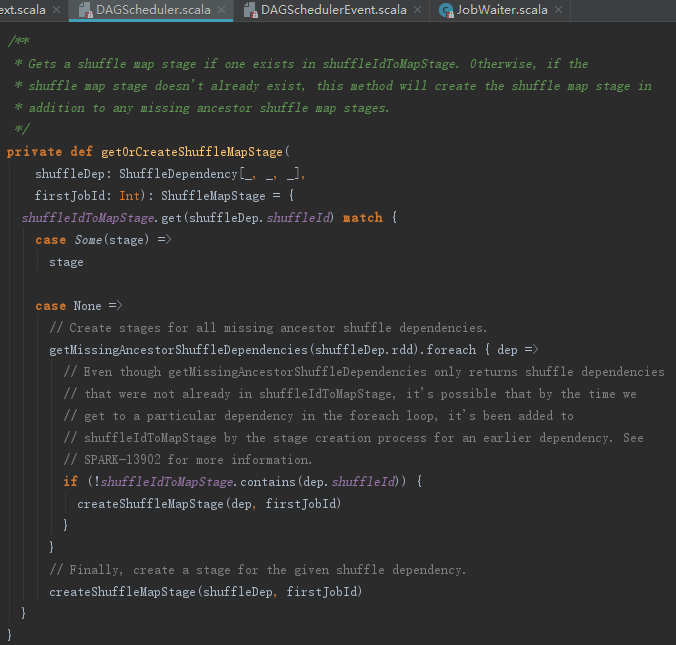
getMissingAncestorShuffleDependencies用来找到RDD直接或者间接依赖的所有祖先中,还没有为其注册过Stage的ShuffleDependency,见代码如下:
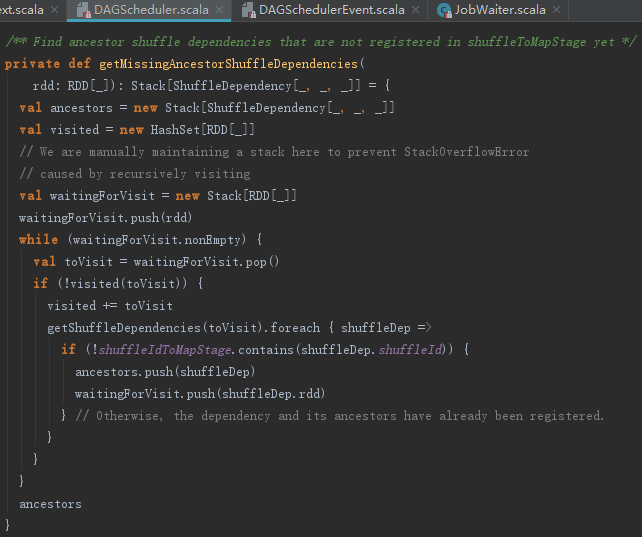
createShuffleMapStage方法:首先调用ShuffleMapStage创建Stage,然后将ShuffleDependency的shuffleId和partitions的length注册到MapOutputTrackerMaster的mapStatuses = new ConcurrentHashMap[Int,Array[MapStatus]]() 中。
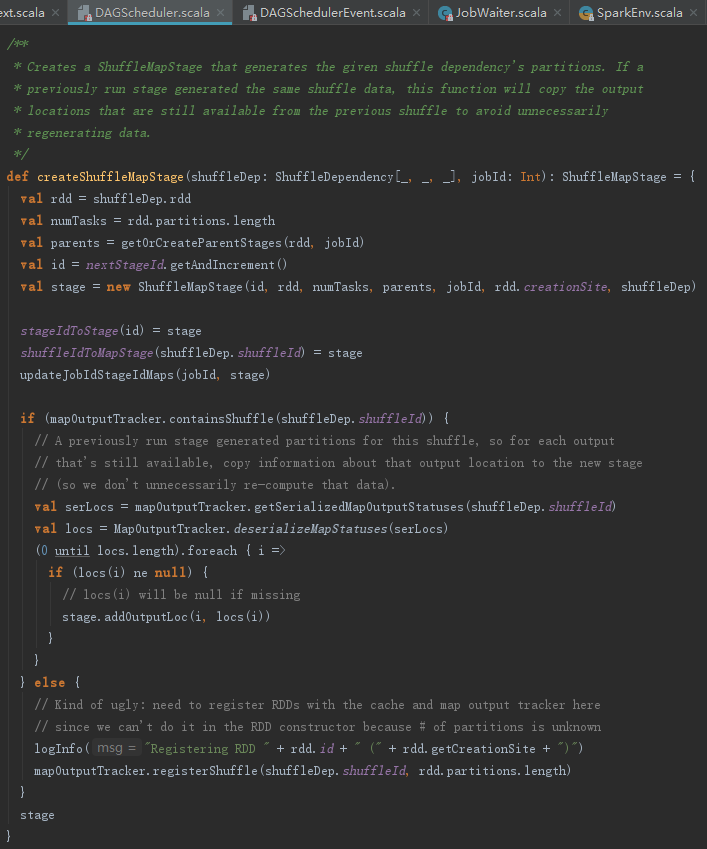
很多地方都调用了createShuffleMapStage创建Stage,从下述代码中来看看Stage的数据结构。
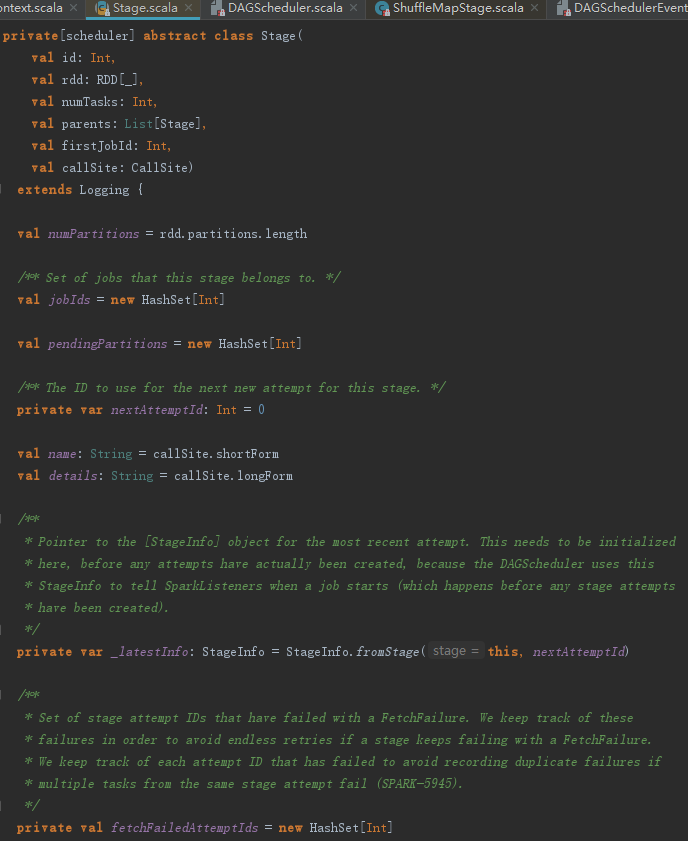
Stage的构造过程中调用了StageInfo的fromStage方法创建StageInfo。
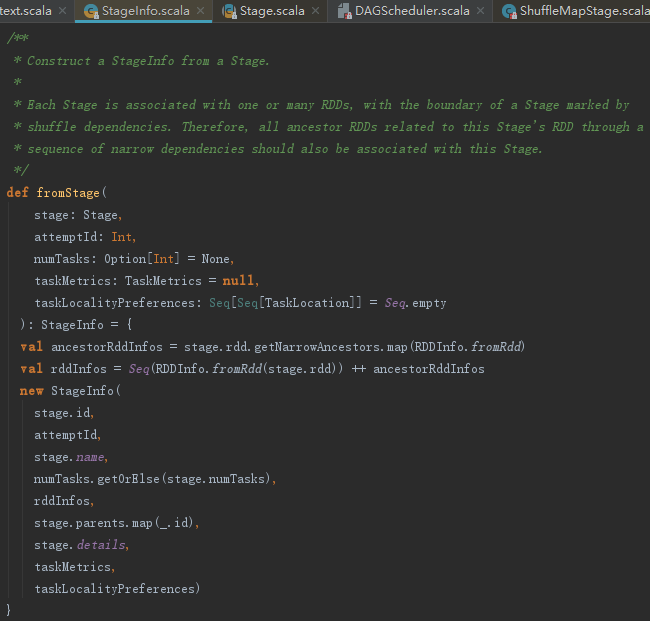
创建StageInfo的步骤如下:
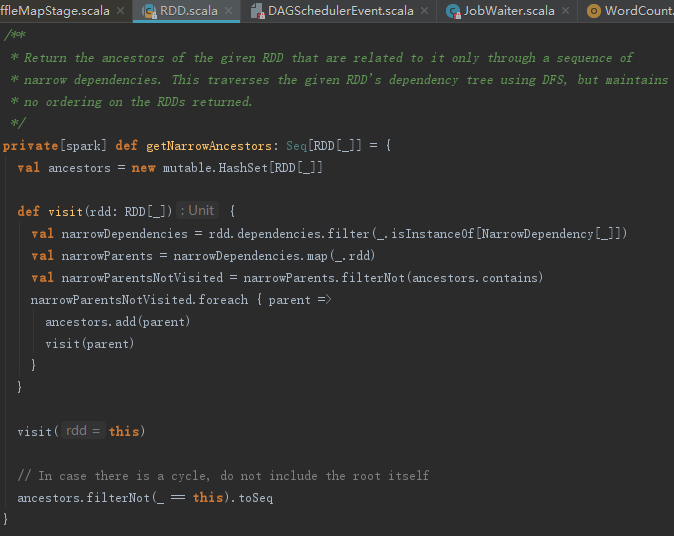
1) 调用getNarrowAncestors方法获取RDD的所有直接或者间接的NarrowDependency的RDD,见代码如下:
返回的Seq[RDD[]]全部map到RDDInfo.fromRdd方法,生成RddInfo,代码如下:
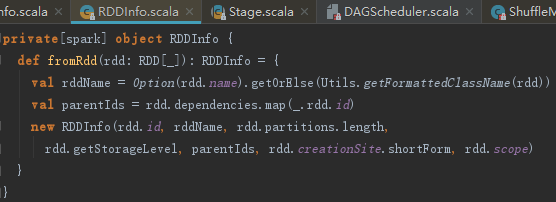
2) 对当前Stage的RDD调用RDDInfo.fromRdd方法,也生成RDDInfo,然后所有生成的RDDInfo都合入rddInfos中。
3) 创建当前Stage的StageInfo。
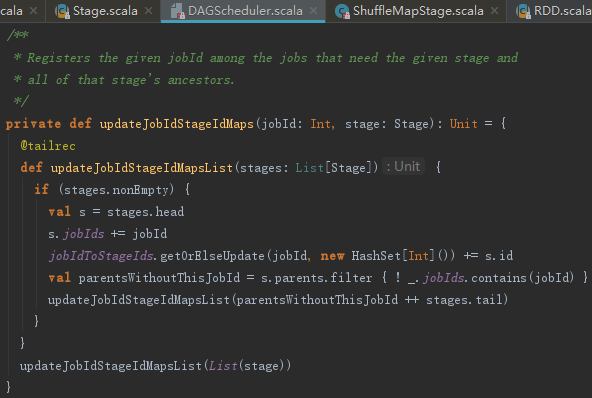
回头看看4.2.1节点中调用的updateJobIdStageIdMaps方法,它的功能如下:
通过迭代调用内部的updateJobIdStageIdMapsList函数,最终将jobId添加到Stage及它的所有祖先Stage的映射jobIds = new HashSet[Int]中,将jobId和Stage及它的所有祖先Stage的id,更新到jobIdToStageIds = new HashMap[Int,HashSet[Int]]中。updateJobIdStageIdMaps的实现见代码如下:
4.3 创建Job
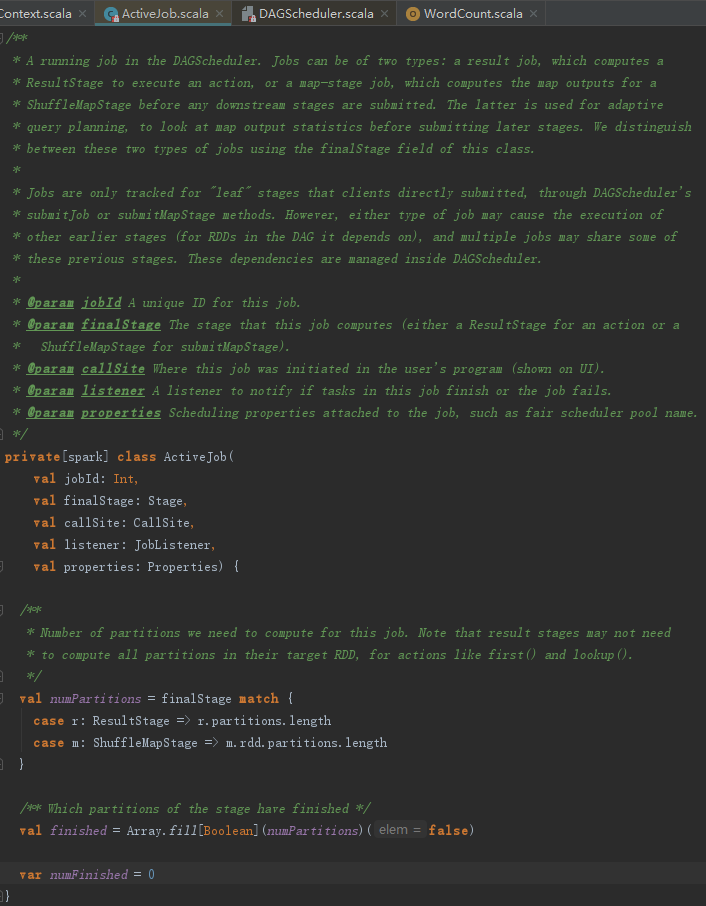
ActiveJob的定义见代码如下,这里对其中的一些定义做些解释:
- numPartitions:任务的分区数量。
- finished:标识每个partition相关的任务是否完成。
- numFinished:已经完成的任务数。
我们回头看看SparkListenerJobStart事件的处理,SparkListenerBus的sparkListeners(比如JobProgressListener)中,凡是实现了onJobStart方法的,将被处理。
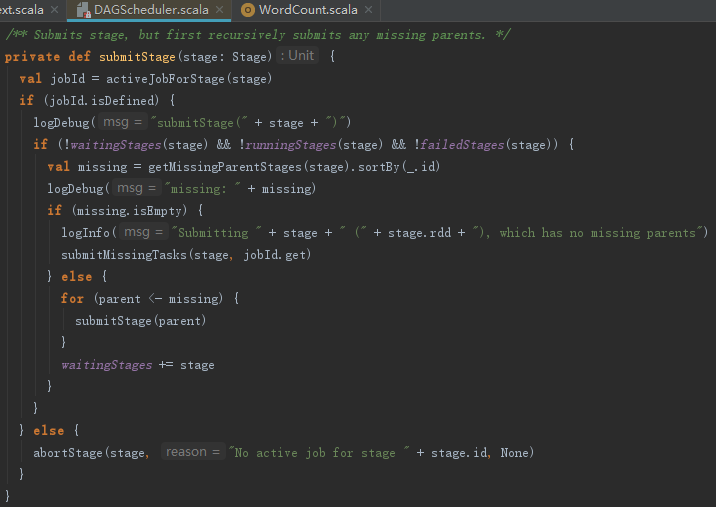
4.4 提交Stage
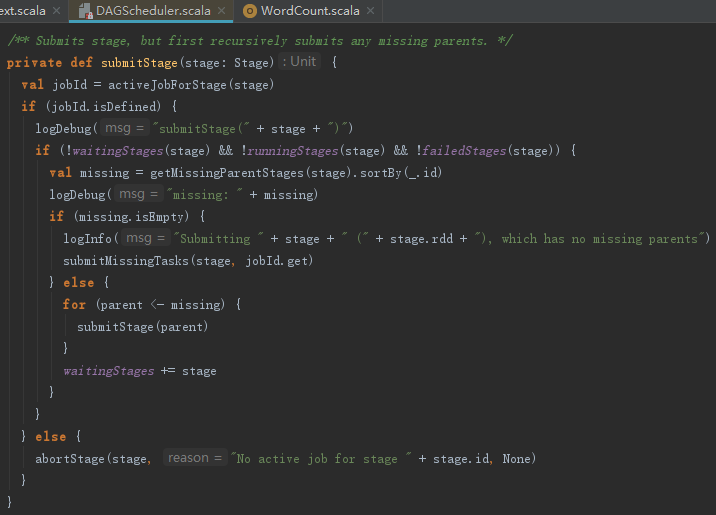
在提交finalStage之前,如果存在没有提交的祖先Stage,则需要先提交所有没有提交的祖先Stage。每个Stage提交之前,如果存在没有提交的祖先Stage,都会先提交祖先Stage,并且将子Stage放入waitingStages = new HashSet[Stage]中等待,如果不存在没有提交的祖先Stage,则提交所有未提交的Task。提交Stage的实现见代码如下:
getMissingParentStages方法用来找到Stage的所有不可用的祖先Stage,见代码如下:
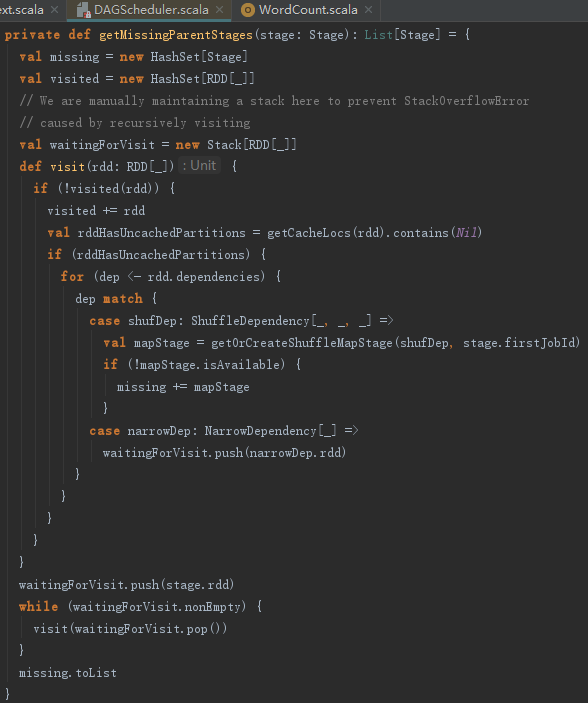
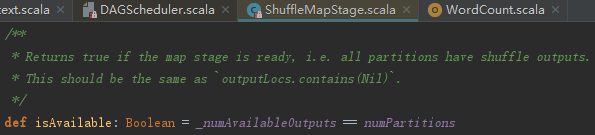
如何判断Stage可用?它的判断十分简单:如果Stage不是Map任务,那么它是可用的;否则它的已经输出计算结果的分区任务数量要和分区数一样,即所有分区上的子任务都要完成。判断逻辑如下:
回头看看handleJobSubmitted方法中调用的submitStages方法,submitStages实际上循环missingStages中的Stage并调用submitStage,实现如下:
4.5 提交Task
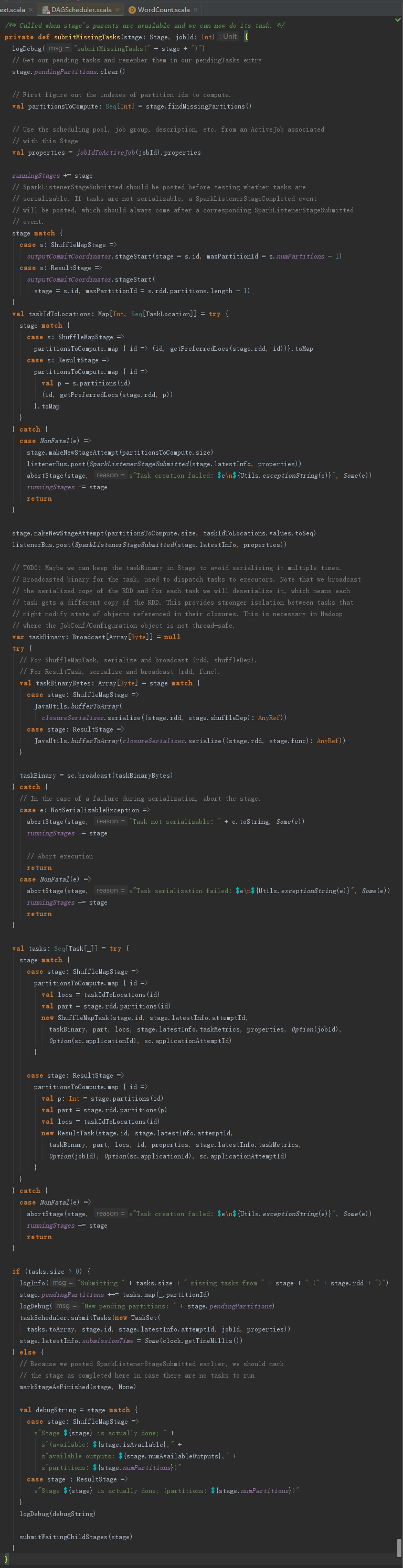
提交Task的入口是submitMissingTask函数,此函数在Stage没有不可用的祖先Stage时,被调用处理当前Stage未提交的任务。
1.提交还未计算的任务
submitMissingTasks用于提交还未计算的任务。在分析submitMissingTasks之前,先对一些定义进行描述:
- pendingTasks:类型时HashSet[Task[_]],存储有待处理的Task。
- MapStatus:包括执行Task的BlockManager的地址和要传给reduce任务的Block的估算大小。
- outputLocs:如果Stage是map任务,则outputLocs记录每个Partition的MapStatus。
submitMissingTasks的执行过程如下:
1) 清空pendingTasks。由于当前Stage的任务刚开始提交,所以需要清空,便于记录需计算的任务。
2) 找出还未计算的partition(如果Stage是map任务,那么outputLocs中partition对应的List[MapStatus]为Nil,说明此partition还未计算。如果Stage不是map任务,那么需要获取Stage的finalJob,并调用finished方法判断每个partition的任务是否完成)。
3) 将当前Stage加入运行中的Stage集合(runningStages:HashSet[Stage])中。
4) 使用StageInfo.fromStage方法创建当前Stage的latestInfo(StageInfo)。
5) 向listenerBus发送SparkListenerStageSubmitted事件。
6) 如果Stage是map任务,那么序列化Stage的RDD及ShuffleDependency。如果Stage不是map任务,那么序列化Stage的RDD及resultOfJob的处理函数。这些序列化得到的字节数组最后需要使用sc.broadcast进行广播。
7) 如果Stage是map任务,则创建ShuffleMapTask,否则创建ResultTask。还未计算的partition个数决定了最终创建的Task个数。并将创建的所有Task都添加到Stage的pendingTasks中。
8) 利用上一步创建的所有Task、当前Stage的id、jobId等信息创建TaskSet,并调用taskScheduler的submitTasks,批量提交Stage及其所有Task。
submitTasks方法,提交任务主要分为以下步骤:
1) 构建任务集管理器。即将TaskScheduler、TaskSet及最大失败次数(maxTaskFailures)封装为TaskSetManager。
2) 设置任务集调度策略(调度模式有FAIR和FIFO两种,此处以默认的FIFO为例)。将TaskSetManager添加到FIFOSchedulableBuilder中,代码如下:

实际上是把TaskSetManager加入rootPool的先进先出(FIFO)的调度队列schedulableQueue和schedulableNameToSchedulable中,并且设置TaskSetManager的parent是Pool。
注意:由于同时可能有多个任务提交,所以需要一种调度策略来决定究竟先提交哪个任务集,例如本例中的FIFO调度策略。
3) 资源分配。调用LocalSchedulerBackend的reviveOffers方法,实际向localEndpoint发送ReviveOffers消息。localEndpoint对ReviveOffers消息的匹配执行reviveOffers方法。
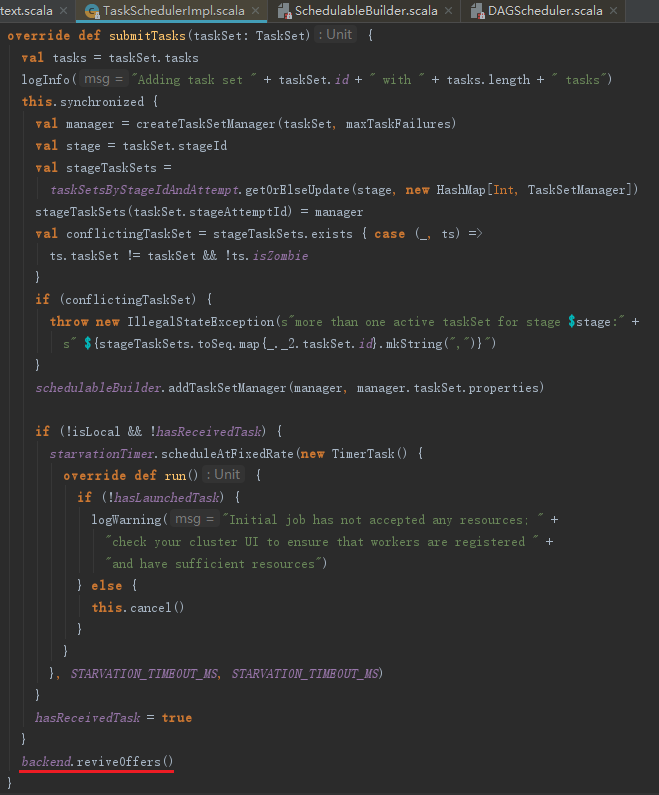
reviveOffers的处理步骤如下:
1) 使用ExecutorId、ExecutorHostName、freeCores(空闲CPU核数)创建WorkerOffer;
2) 调用TaskSchedulerImpl的resourceOffers方法分配资源;
3) 调用Executor 的launchTask方法运行任务。
发送消息

接收到消息启动
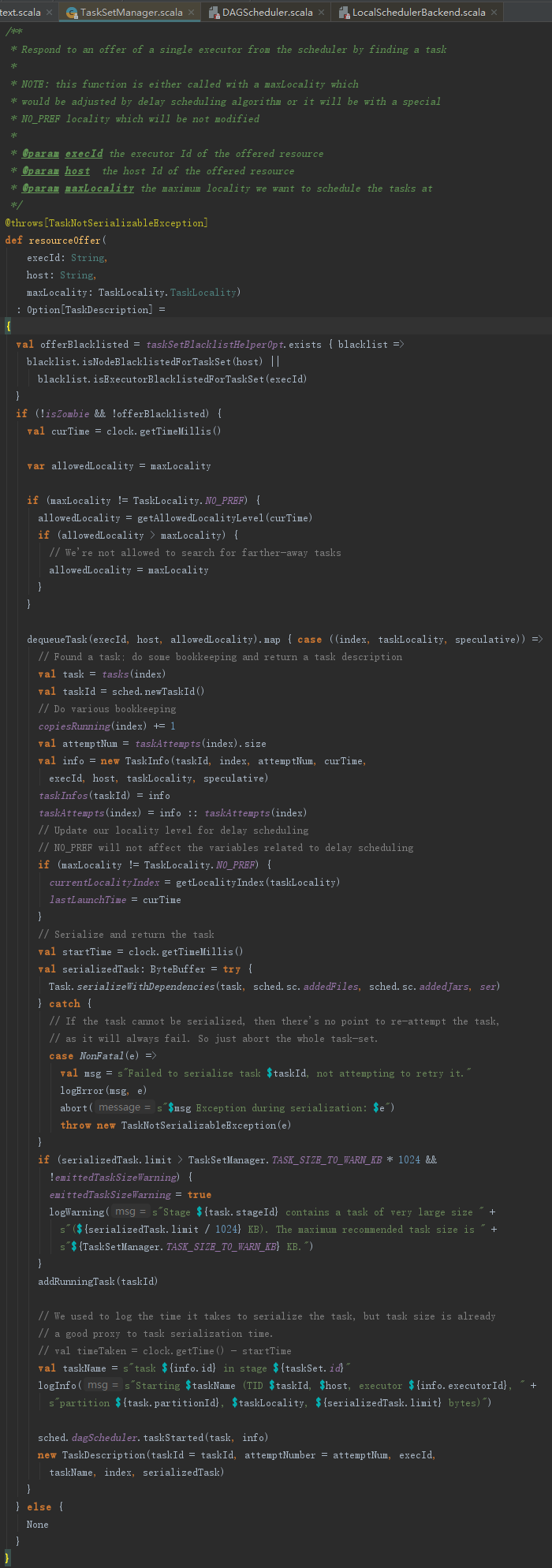
2. 资源分配
resourceOffers方法用于Task任务的资源分配,其处理步骤如下:
1) 标记Executor与host的关系,增加激活的Executor的id,按照host对Executor分组,并向DAGSchedulerEventProcessActor发送ExecutorAdded事件等。
2) 计算资源的分配与计算。对所有WorkerOffer随机洗牌,避免将任务总是分配给同样的WorkerOffer。
3) 根据每个WorkerOffer的可用的CPU核数创建同等尺寸的任务描述(TaskDescription)数组。
4) 将每个WorkerOffer的可用的CPU核数统计到可用CPU(availableCpus)数组中。
5) 对rootPool中的所有TaskSetManager按照调度算法排序(本例中为FIFO调度算法)。
6) 调用每个TaskSetManager的resourceOffer方法,根据WorkerOffer的ExecutorId和host找到需要执行的任务并进一步进行资源处理。
7) 任务分配到相应的host和Executor后,将taskId和TaskSetId的关系、taskId与ExecutorId的关系、executors与Host的分组关系等更新并且将availableCpus数目减去每个任务分配的CPU核数(CPUS_PER_TASK)。
8) 返回第3)步生成的TaskDescription列表。
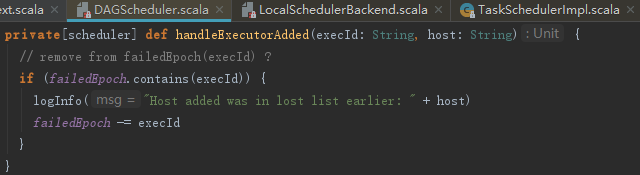
DAGSchedulerEventProcessLoop会将ExecutorAdded事件匹配执行DagScheduler的handleExecutorAdded方法,用于将跟踪失败的节点重新恢复正常和提交等待中的Stage,见代码如下:
3. Worker任务分配
resourceOffer方法用于给Worker分配Task,其处理步骤如下:
1) 获取当前任务集允许使用的本地化级别。
2) 调用findTask寻找Executor、Host、pendingTasksWithNoPrefs中有待运行的task。
3) 创建TaskInfo,并对task,addedFiles、addedJars进行序列化。
4) 调用DagScheduler的taskStarted方法,笔者认为此处方法名不当,因为taskStarted的功能是向DAGSchedulerEventProcessLoop发送BeginEvent事件,它的实现如下:
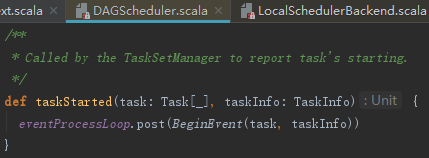
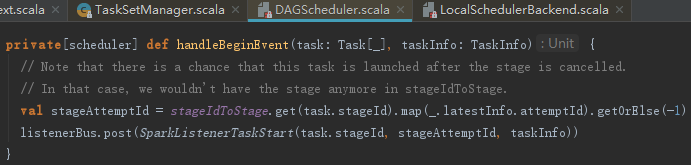
DAGSchedulerEventProcessLoop在接收BeginEvent事件后,调用了dagScheduler的方法handleBeginEvent。handleBeginEvent方法通过发送SparkListenerTaskStart事件给listenerBus,用以各种监听器更新SparkUI的显示。
5) 最终封装TaskDescription对象并返回。
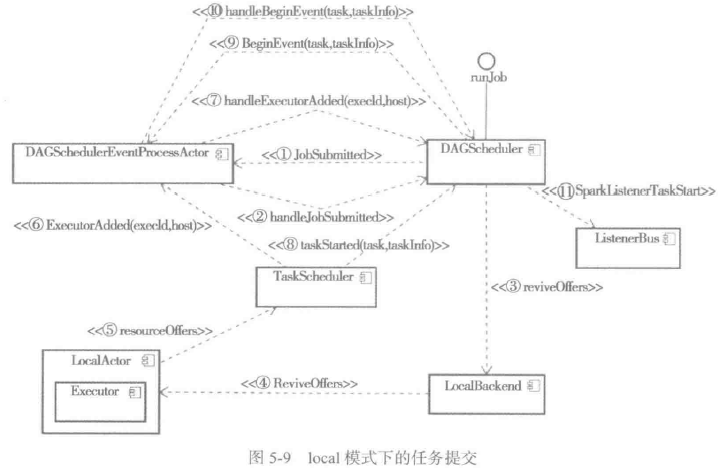
local模式下,任务提交的过程可以用图5-9来表示:
4. 本地化分析
与Hadoop类似,Spark中任务的处理也要考虑数据的本地性(Locality)。Spark目前支持PROCESS_LOCAL(本地进程)、NODE_LOCAL(本地节点)、NO_PREF(没有喜好)、RACK_LOCAL(本地机架)、ANY(任何)几种。
Spark涉及本地性的数据只有两种、HadoopRDD和数据源于存储体系的RDD(即由CacheManager从BlockManager中读取,或者Streaming数据源RDD)。
除了NO_PREF,其他定义都比较好理解。什么是NO_PREF?
当Driver应用程序刚刚启动,Driver分配获得Executor很可能还没有初始化完毕。所以会有一部分任务的本地化级别被设置为NO_PREF。如果是ShuffleRDD,其本地性始终为NO_PREF。对于这两种本地化级别是NO_PREF的情况,在任务分配时会被优先分配到非本地节点执行,达到一定的优化效果。
调用getAllowedLocalityLevel方法来获取任务集允许使用的本地化级别。在讲解getAllowedLocalityLevel之前,我们先介绍本地化的几个概念。
- myLocalityLevels:当前TaskSetManager允许使用的本地化级别。
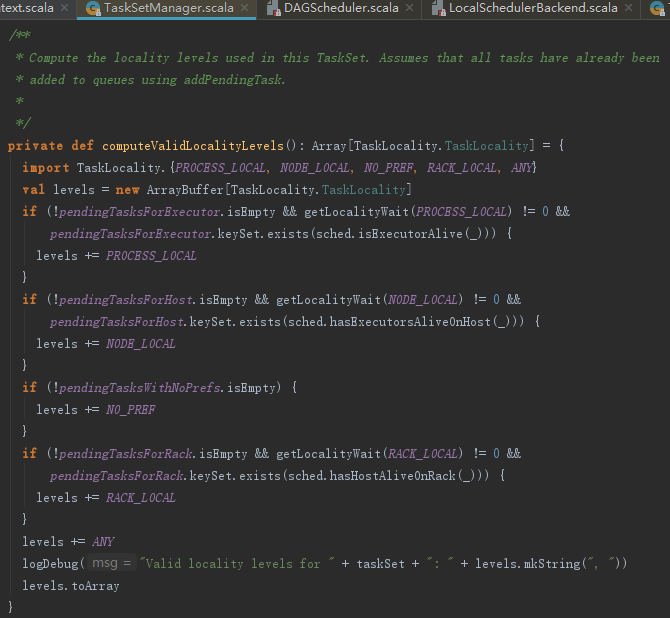
myLocalityLevels实际是对函数computeValidLocalityLevels的引用,代码如下:

computeValidLocalityLevels方法用于计算有效的本地化级别。以PROCESS_LOCAL为例,如果存在Executor中有待执行的任务(pendingTasksForExecutor步为空)且PROCESS_LOCAL本地化的等待时间不为0(调用getLocalityWait方法获得)且存在Executor已被激活(pendingTasksForExecutor中的ExecutorId有存在于TaskScheduler的activeExecutorIds中的),那么允许的本地化级别里包括PROCESS_LOCAL。
getLocalityWait方法用于获取各个本地化级别的等待时间,这些配置如下所示:
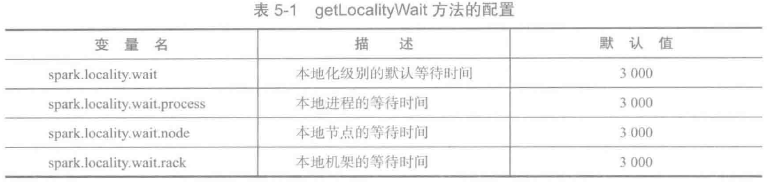
- localityWaits:本地化级别等待时间。
localityWaits实际是对myLocalityLevels应用getLocalityWait方法获得,代码如下:

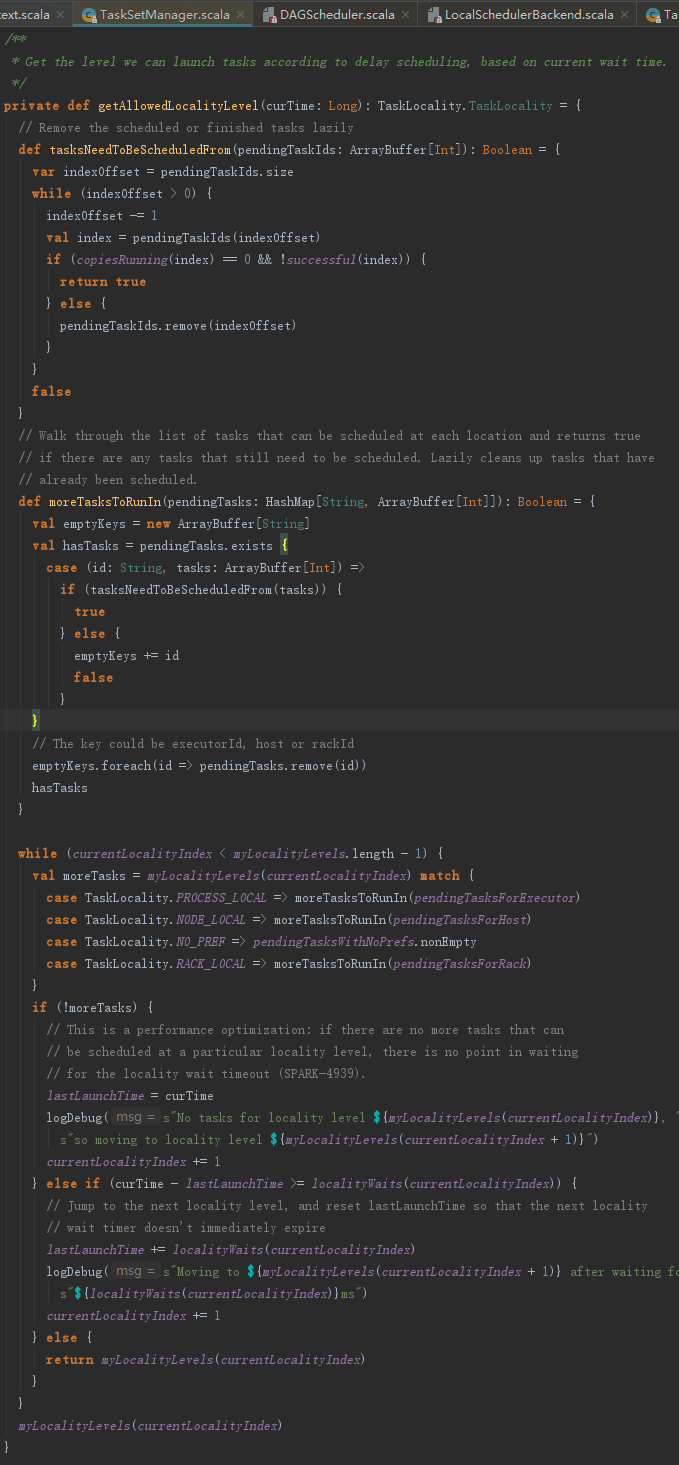
现在一起分析getAllowedLocalityLevel方法,它的处理步骤如下:
1) 根据当前本地化级别索引(currentLocalityIndex刚开始为0),获取此本地化级别的等待时长;
2) 如果当前时间与上次运行本地化时间(lastLaunchTime)之差大于等于上一步获得的时长并且当前本地化级别索引小于myLocalityLevels的索引范围,那么将第1)步的时长增加到lastLaunchTime中,然后使currentLocalityIndex增加1,最后重新从第1)步开始执行(这个过程也称为本地化级别跳级)。
5. 执行任务
调用Executor的launchTask方法时,标志着任务执行阶段的开始。launchTask的执行过程如下:
1) 创建TaskRunner,并将其与taskId、taskName及serializedTask添加到runningTasks = new ConcurrentHashMap[Long, TaskRunner]中。
2) TaskRunner实现了Runnable接口(Scala中称为Runnable特质),最后使用线程池执行TaskRunner。
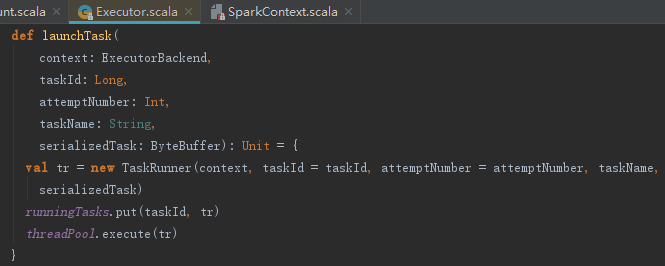
我们知道线程执行时,会调用TaskRunner的run方法。run方法的处理动作包括状态更新、任务反序列化、任务运行。
5.1 状态更新
调用execBackend的statusUpdate方法更新任务状态,代码如下:

以LocalSchedulerBackend为例,实际向LocalEndpoint发送statusUpdate消息,代码如下:

LocalEndpoint在接收到statusUpdate事件时,匹配执行TaskSchedulerImpl的statusUpdate方法,并根据Task的最新状态做一系列处理。
5.2 任务还原
所谓任务还原就是将Driver提交的Task在Executor上通过反序列化、更新依赖达到Task还原效果的过程
对4.5.3序列化的serializedTask执行反序列化操作,代码如下:

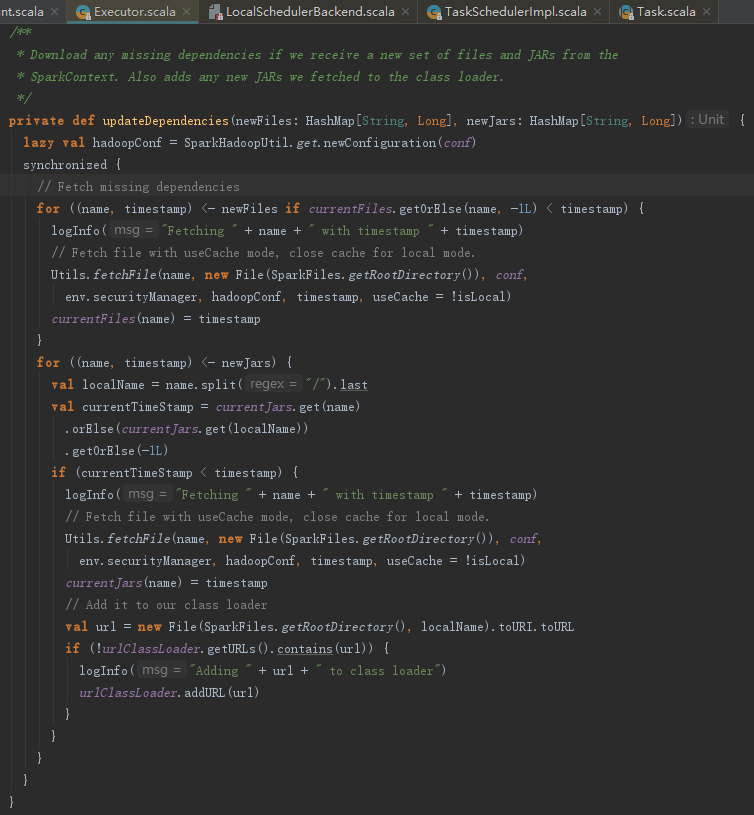
更新依赖的文件或者jar包,代码如下:

updateDependencies方法获取依赖是利用了Utils.fetchFile方法实现的。下载的jar文件还会添加到Executor自身类加载器的URL中。
最后将Task的ByteBuffer反序列化为Task实例,实现如下:

5.3 任务运行
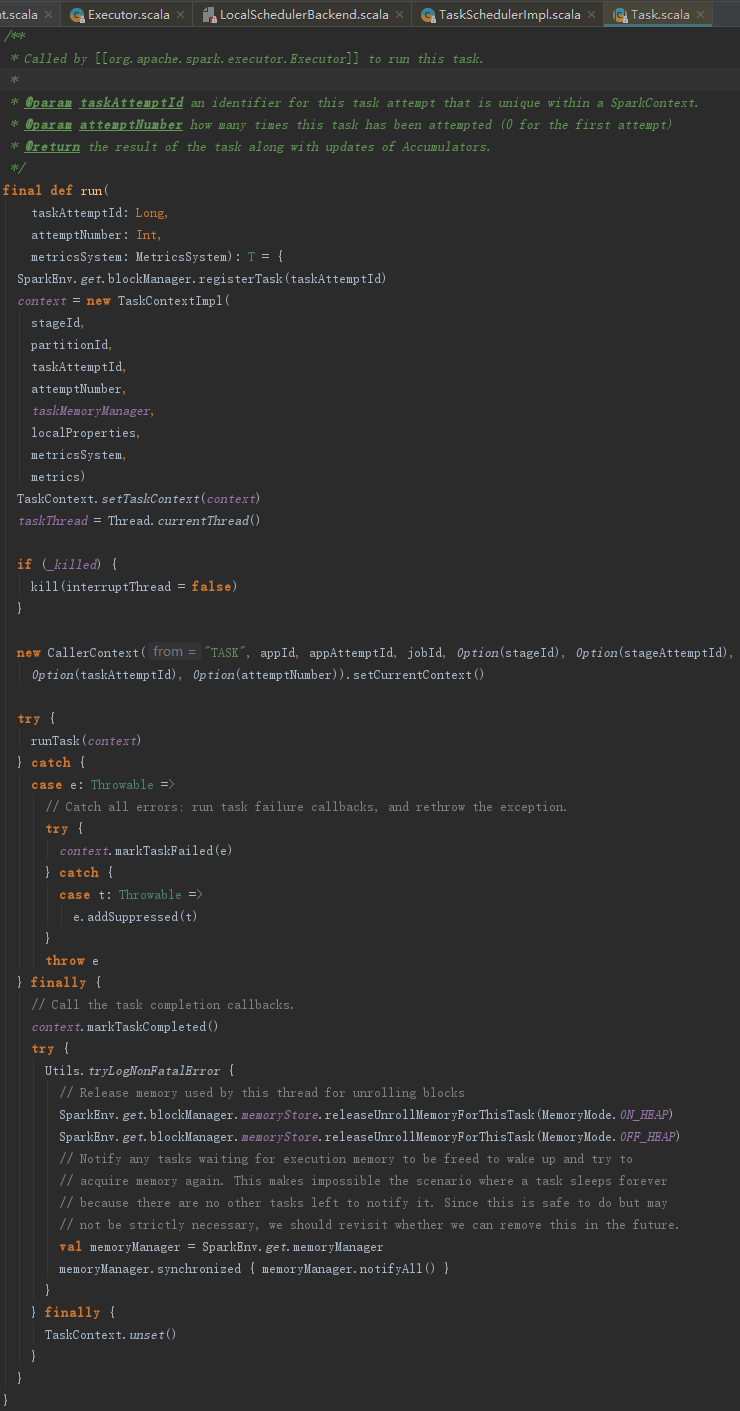
TaskRunner最终调用Task的run方法来运行任务,实现如下:
run方法中创建了TaskContextImpl,并且设置到TaskContext的ThreadLocal中。最后调用runTask方法,见代码如下:
在word count的例子中,首先执行的Task是ShuffleMapTask,那么ShuffleMapTask的runTask方法都做了什么?曾经介绍submitMissingTasks的时候,其中对任务的RDD和ShuffleDependency进行过序列化操作,现在是时候反序列化了,这样可以得到RDD和ShuffleDependency。接下来调用SortShuffleManager的getWriter方法获取partitionId指定分区的SortShuffleWriter。之后便利用此Writer将计算的中间结果写入文件。
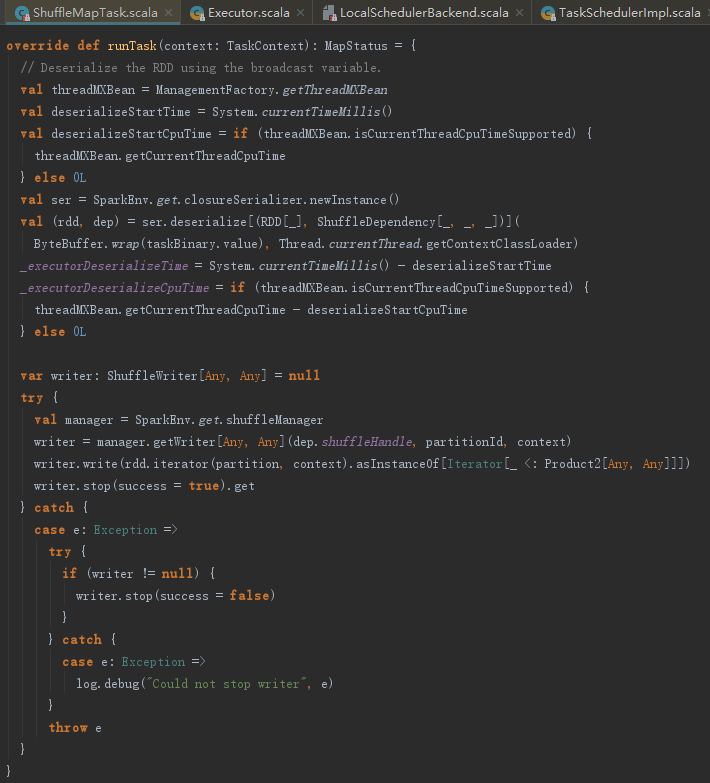
SortShuffleManager的getWriter实现,参数mapId实际传入的是partitionId,由此我们可以看到partition与map任务的关系。
SortShuffleWriter负责计算结果的缓存处理持久化。我们暂时只需理解的是map任务的Stage的任务执行结果将通过SortShuffleManager持久化到存储体系即可。RDD的iterator方法触发任务计算。
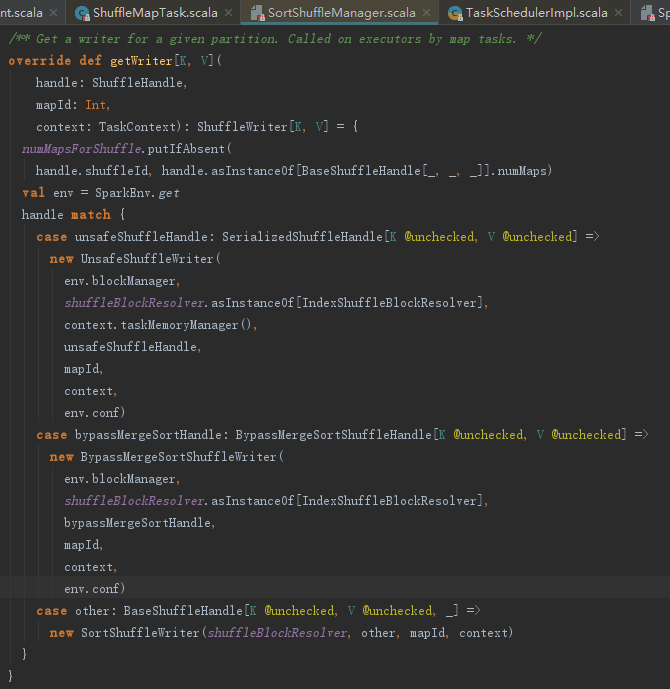
6. 任务执行后续处理
6.1 计量统计与执行结果序列化
分析下述代码,可以看到任务执行结束后,还会有以下处理。
1) 任务执行结果的简单序列化
2) 计量统计,需要更新的指标有:
- Executor反序列化消耗的时间;
- Executor实际执行任务消耗的时间;
- Executor执行垃圾回收消耗的时间;
- Executor执行结果序列化消耗的时间。
3) 将前两步得到的简单序列化结果和计量统计内容封装为DirectTaskResult,然后序列化。
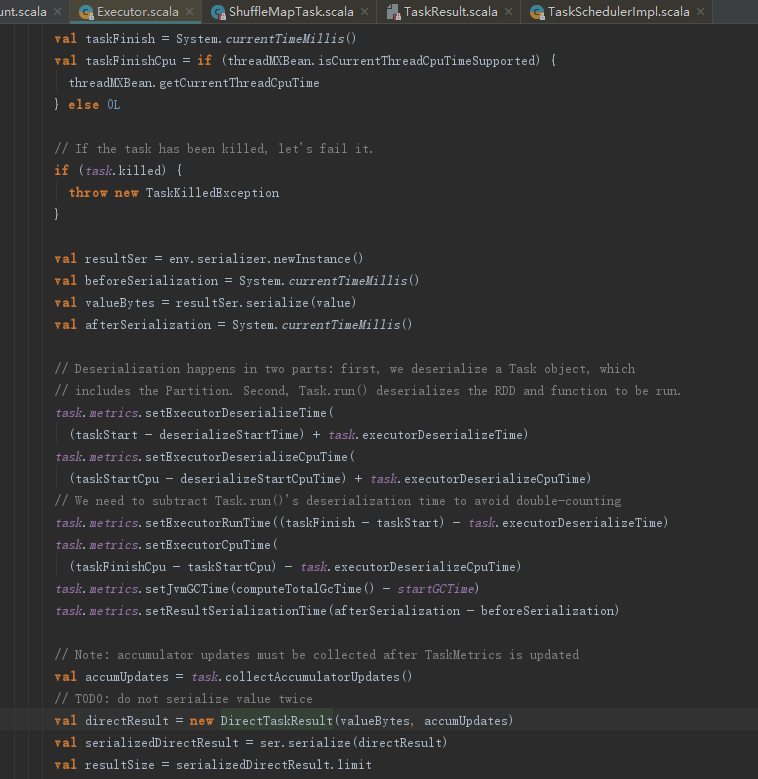
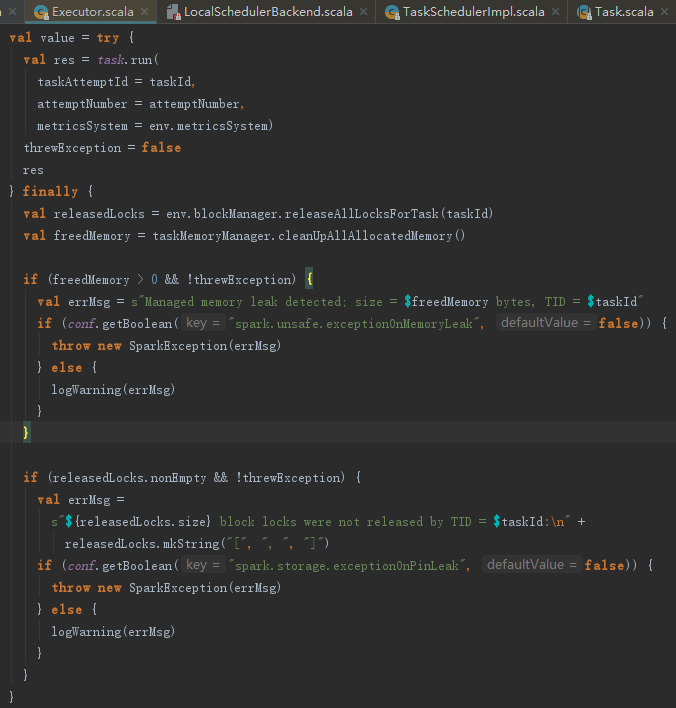
6.2 内存回收
TaskRunner的run方法最后还会在finally中做一些清理工作,包括:
1) 释放当前线程通过ShuffleMemoryManager获得的内存;
2) 释放当前线程在MemoryStore的unrollMemoryMap中展开占用的内存;
3) 释放当前线程用于聚合计算占用的内存;
4) 将当前Task从runningTasks中移除。
暂略
6.3 执行结果处理
任务完成的时候会发送一次statusUpdate消息,LocalEndpoint会先匹配执行TaskSchedulerImpl的statusUpdate方法,然后调用reviveOffers方法调用其他的任务。
TaskSchedulerImpl的statusUpdate方法会从taskIdToTaskSetId、taskIdToExecutorId中移除此任务,并且调用taskResultGetter的enqueueSuccessfulTask方法。
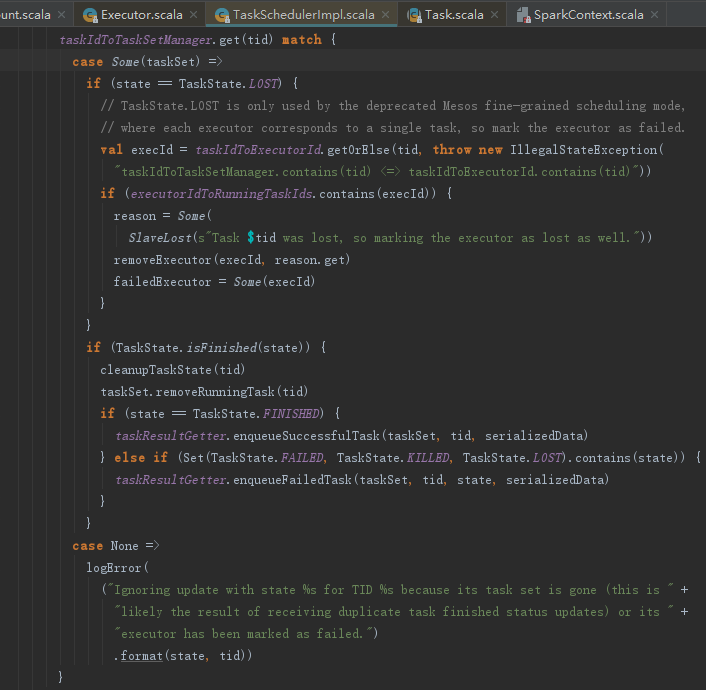
taskResultGetter的enqueueSuccessfulTask和enqueueFailedTask方法,分别用于处理执行成功任务的返回结果和执行失败任务的返回结果。我们以enqueueSuccessfulTask方法为例:
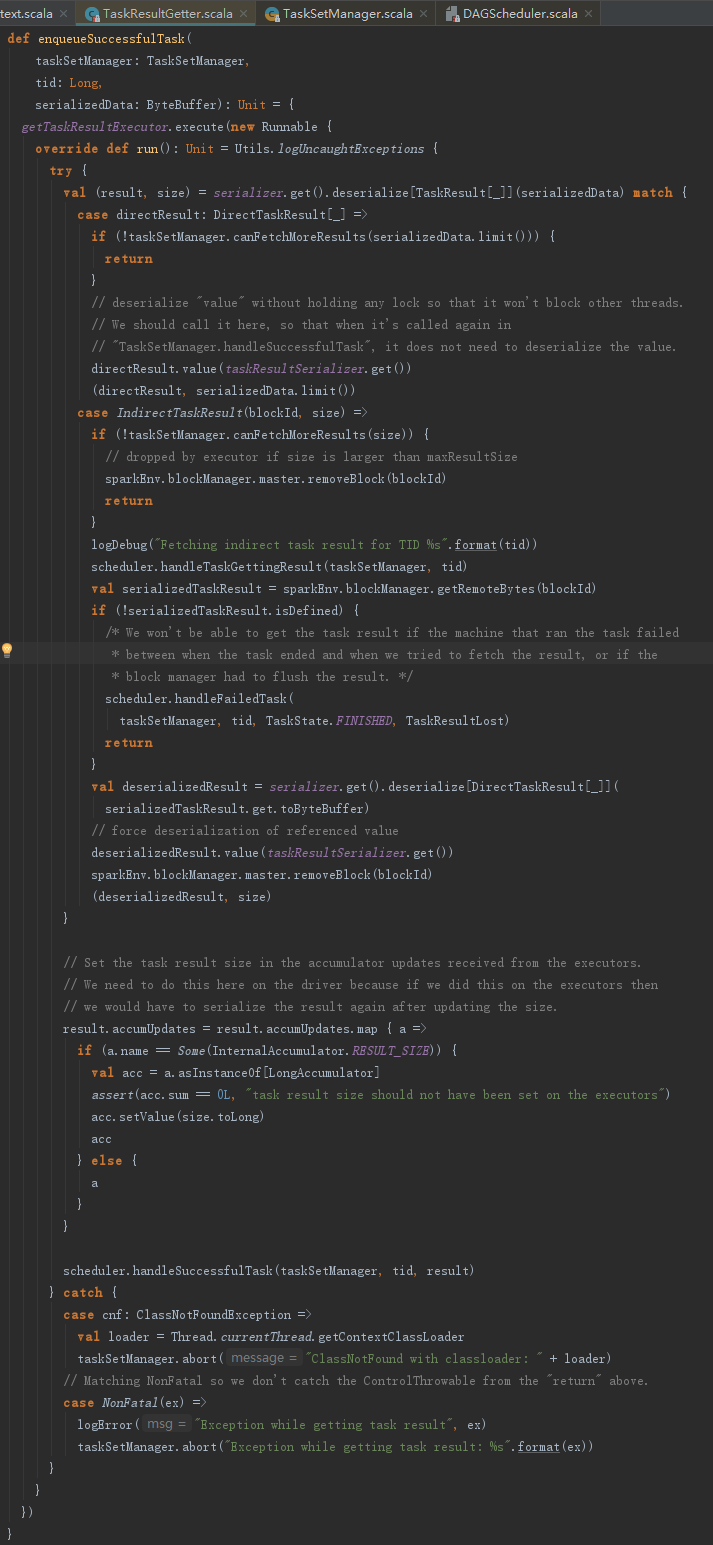
从enqueueSuccessfulTask的实现不难看出其中另起的线程,主要调用了TaskSchedulerImpl的handleSuccessfulTask方法。TaskSchedulerImpl的handleSuccessfulTask方法的实现如下:
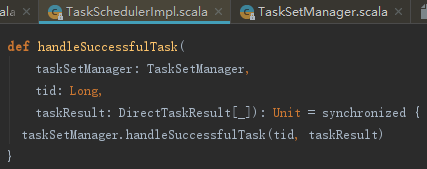
TaskSetManager的handleSuccessfulTask方法对TaskSet中的任务信息进行成功状态标记,然后调用DagScheduler的taskEnded方法。
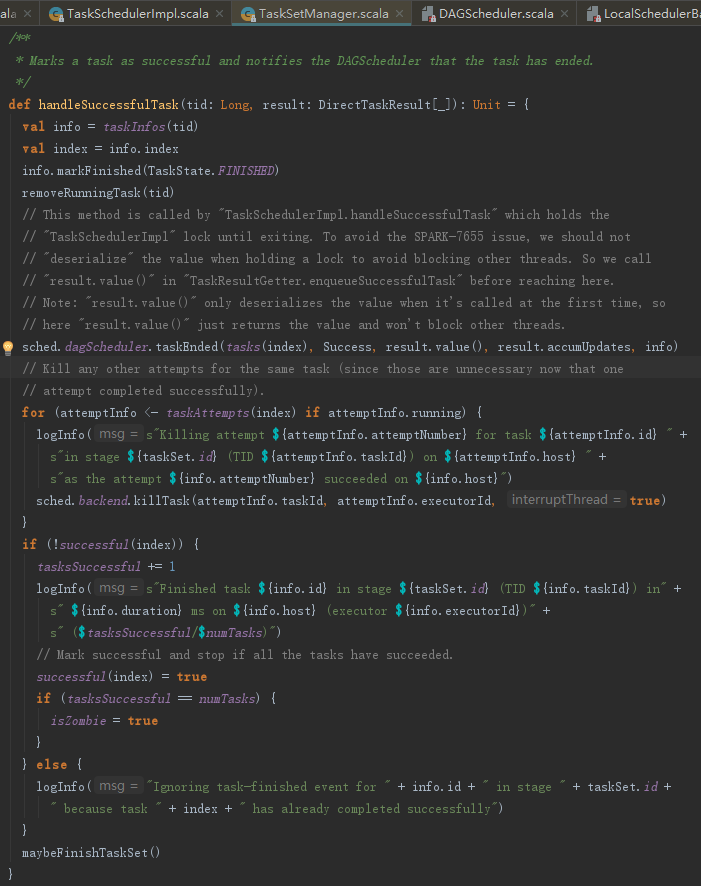
DagScheduler的taskEnded方法的实现如下:
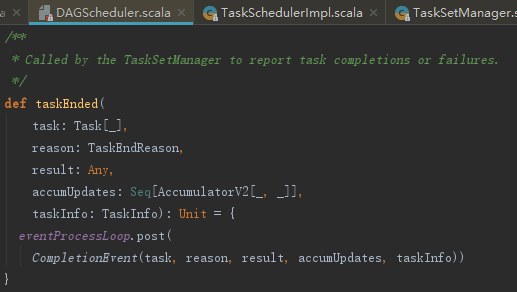
DAGSchedulerEventProcessLoop接收CompletionEvent消息,将处理交给了handleTaskCompletion。handleTaskCompletion方法首先向listenerBus发送SparkListenerTaskEnd,代码如下:
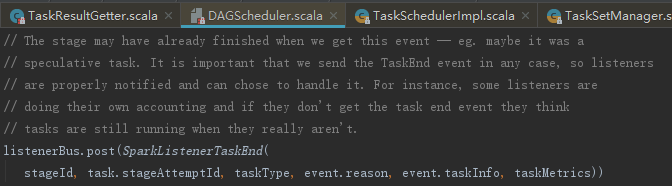
1. ResultTask任务的结果处理
如果是ResultTask,那么将执行下面的代码,其处理步骤如下:
1) 标识ActiveJob的finished里对应分区的任务为完成状态,并且将已完成的任务数numFinished加1。
2) 如果ActiveJob的所有任务都完成,则标记当前Stage完成并向listenerBus发送SparkListenerJobEnd事件。
3) 调用JobWaiter的taskSucceeded方法,以便通知JobWaiter有任务成功。
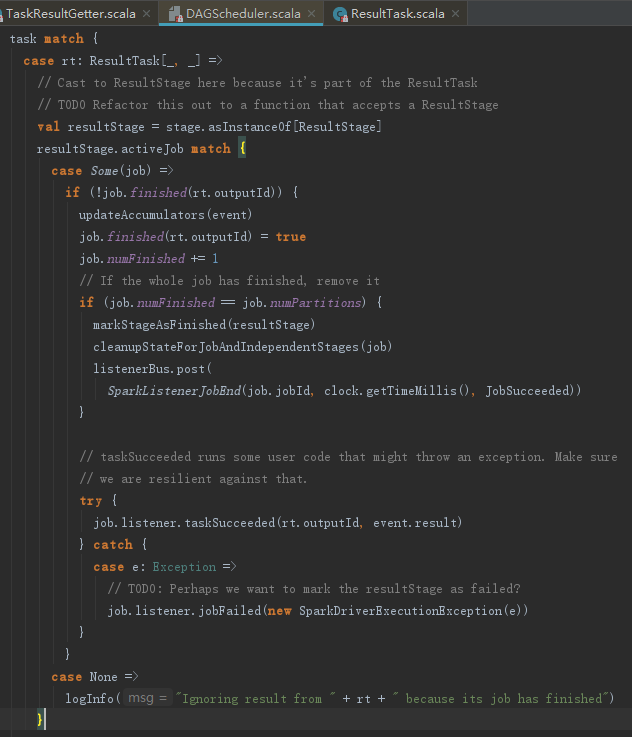
JobWaiter的taskSucceeded方法,其处理步骤如下:
1) JobWaiter中的resultHandler实际是代码清单5-20里的匿名函数(index,res) => results(index) = res,通过回调此匿名函数,将当前任务的结果加入最终结果集。
2) finishedTasks自增,当完成任务数finishedTasks等于全部任务数totalTasks时,标记job完成,并且唤醒等待的线程,即执行代码清单5-22中调用awaitResult方法的线程。
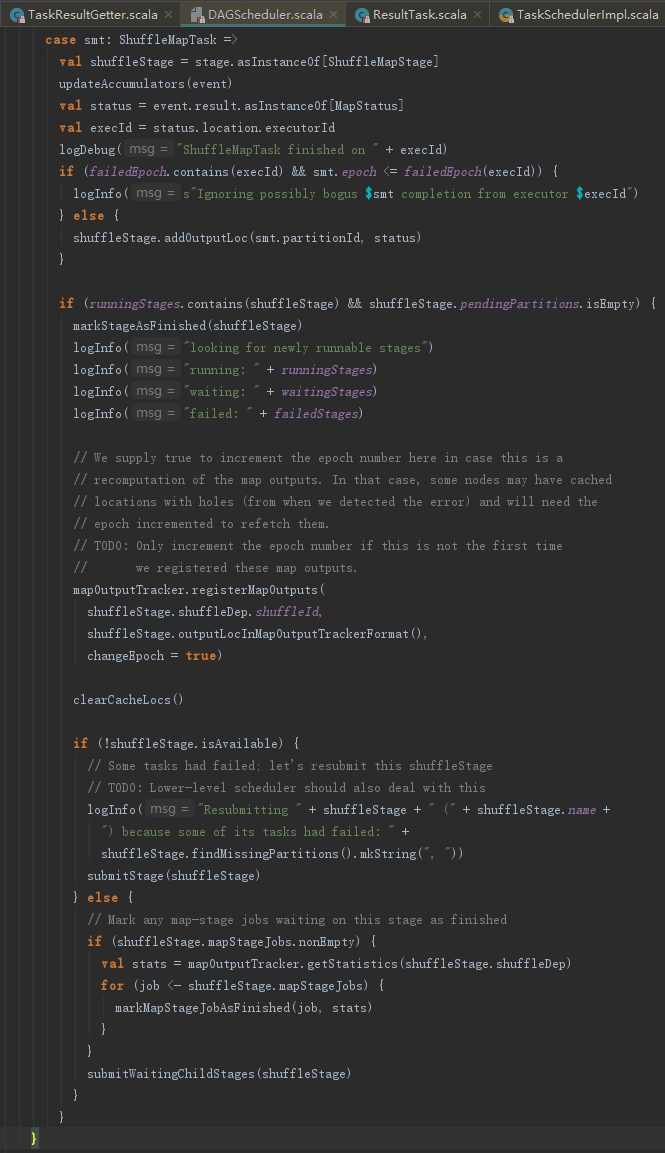
2. ShuffleMapTask任务的结果处理
如果是ShuffleMapTask,那么将执行下述代码所示的代码分支,其处理步骤如下:
1) 将Task的partitionId和MapStatus追加到Stage的outputLocs中。
2) 将当前Stage标记为完成,然后将当前Stage的shuffleId和outputLocs中的MapStatus注册到mapOutputTracker。根据3.2.3节的内容,这里注册的map任务状态将最终被reduce任务所用。
3) 如果Stage的outputLocs中某个分区的输出为Nil,那么说明有任务失败了,这时需要再次提交此Stage。
4) 如果不存在Stage的outputLocs中某个分区的输出为Nil,那么说明所有任务执行成功了,这时需要遍历waitingStages中的Stage并将它们放入runningStages,最后调用submitMissingTasks方法逐个提交这些准备运行的Stage的任务。在word count例子里,由于map任务的Stage已经运行完成,现在运行的是reduce任务的Stage,所以此时调用submitMissingTasks方法则创建了ResultTask。
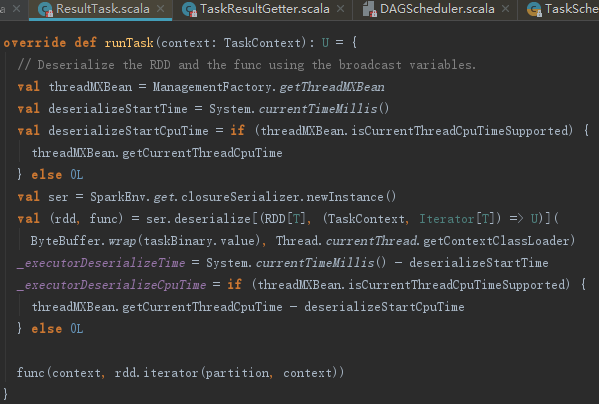
ResultTask的runTask方法与ShuffleMapTask有很多不同,见如下代码:
参考资料:
暂无