一些网站中访问其中的数据需要登陆,并且需要输入验证码。
那么为什么要有验证码?
验证码就是一种防止机器识别的措施,也就是一种反爬机制。
那么我们应该如何破解这种反爬机制?
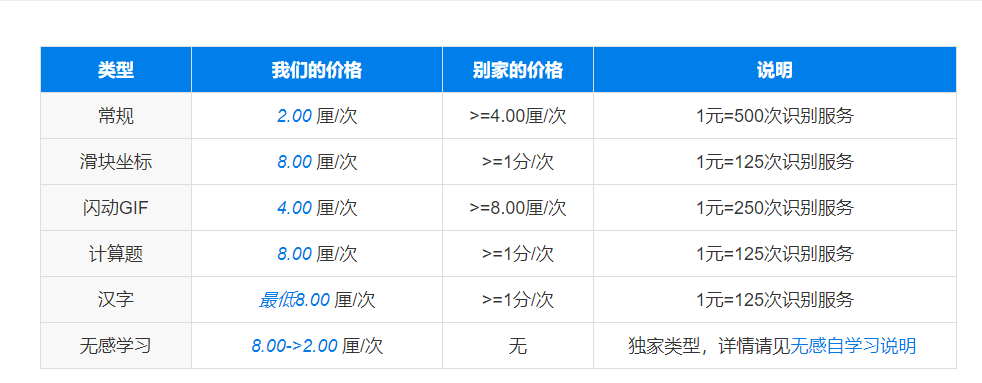
我们可以使用第三方平台,这里推荐使用图鉴http://www.ttshitu.com/price.html
我们需要做的是,注册,登陆,充值一定金额(每一次识别需要一定费用),然后下载它的源代码。
源代码


import json import requests import base64 from PIL import Image from io import BytesIO from sys import version_info def base64_api(uname, pwd, img): img = img.convert('RGB') buffered = BytesIO() img.save(buffered, format="JPEG") if version_info.major >= 3: b64 = str(base64.b64encode(buffered.getvalue()), encoding='utf-8') else: b64 = str(base64.b64encode(buffered.getvalue())) data = {"username": uname, "password": pwd, "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/base64", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"] return "" if __name__ == "__main__": img_path = "图片路径" img = Image.open(img_path) result = base64_api(uname='用户名', pwd='密码', img=img) print(result)
使用时直接插入爬虫程序即可。
示例:识别古诗文网的验证码
import json import requests import base64 from PIL import Image from io import BytesIO from sys import version_info from lxml import etree def base64_api(uname, pwd, img): img = img.convert('RGB') buffered = BytesIO() img.save(buffered, format="JPEG") if version_info.major >= 3: b64 = str(base64.b64encode(buffered.getvalue()), encoding='utf-8') else: b64 = str(base64.b64encode(buffered.getvalue())) data = {"username": uname, "password": pwd, "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/base64", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"] return "" if __name__ == "__main__":
"""
以上为源码
"""
# 拿到登陆页面的验证码图片 url = 'https://www.gushiwen.com/main/login.html' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36', } page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) img_src = 'https://www.gushiwen.com/'+tree.xpath('//*[@id="main"]/div/div/form/div/ul/li[3]/img/@src')[0] img_data = requests.get(url=img_src,headers=headers).content with open('./code.jpg','wb') as f: f.write(img_data)
# 交给第三方平台识别 img_path = "code.jpg" img = Image.open(img_path) result = base64_api(uname='Mrterrific', pwd='WQ2017617sxy', img=img) print(result)