异步爬取牛客网帖子信息并作出高频词汇词云图
流程分析:
1.打开对应的url='https://www.nowcoder.com/discuss?type=0&order=0'
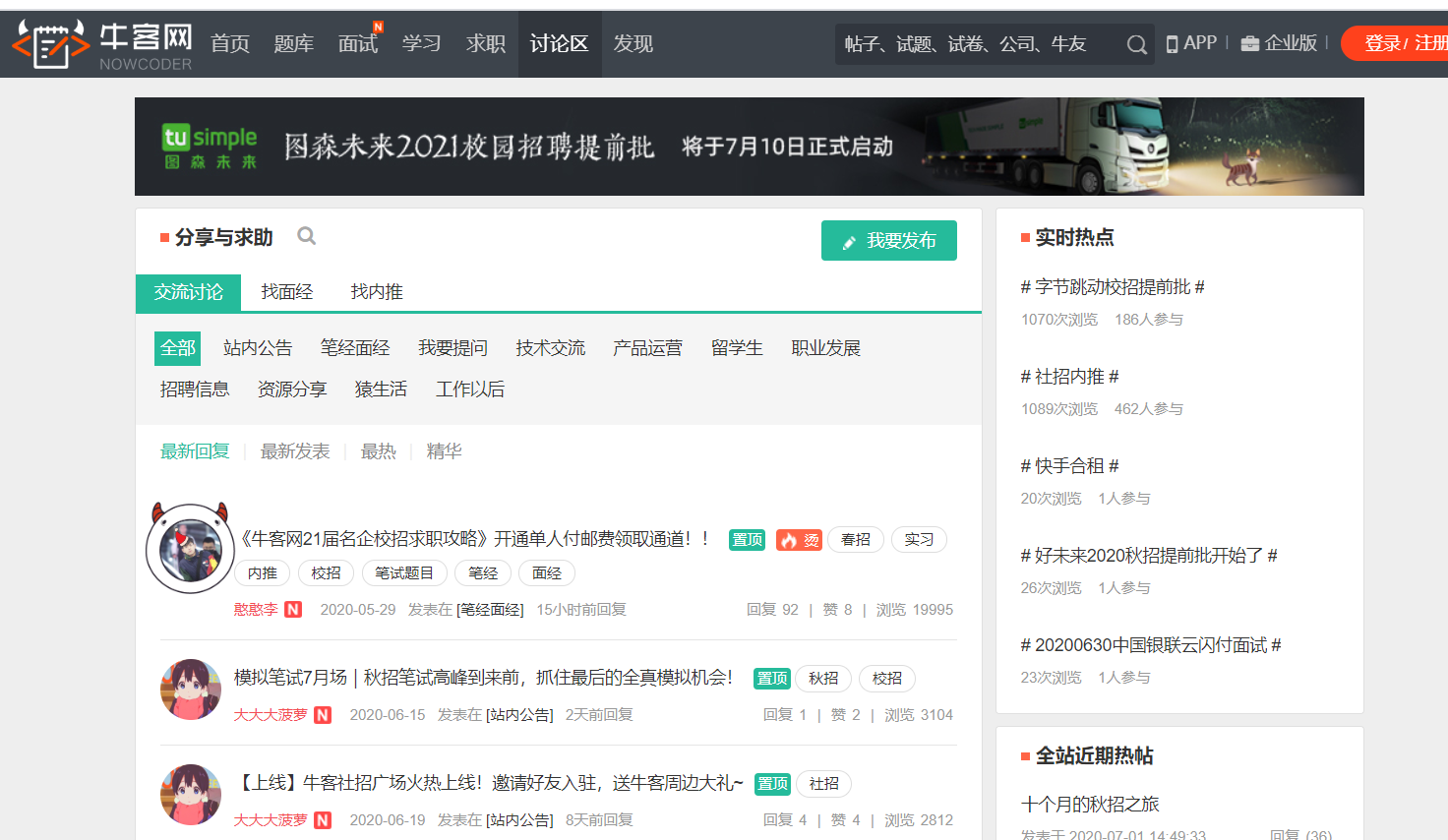
2.获取每一条帖子的通用的标签位置
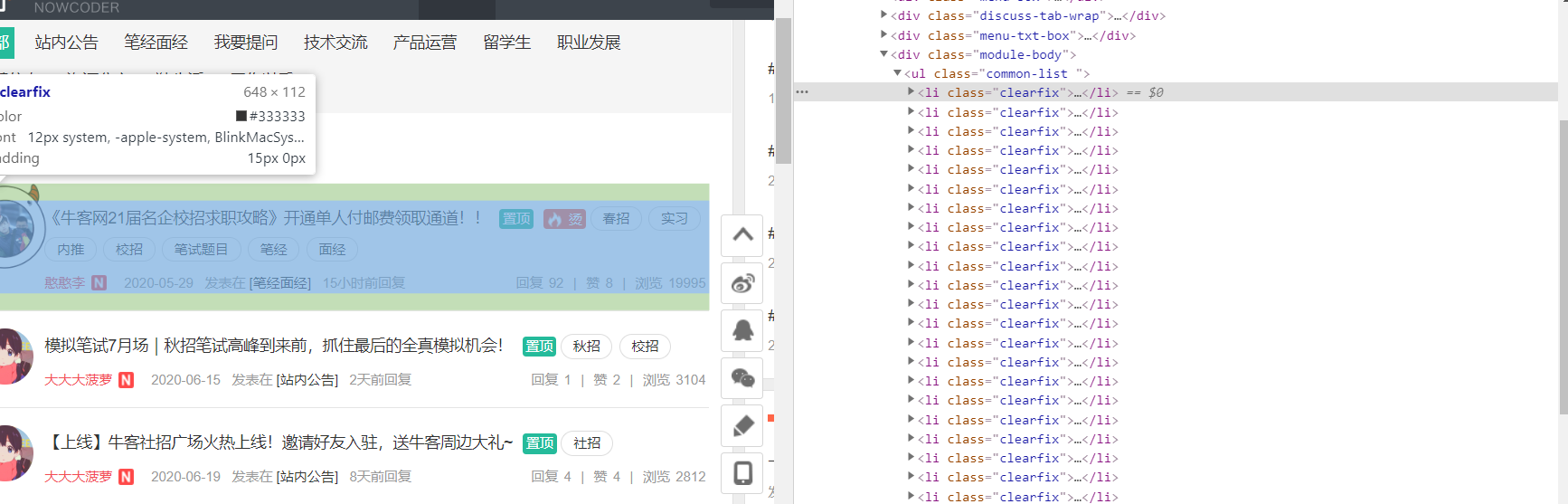
不难看出每一条帖子都在li标签下,因此我们应该首先定位到ul标签下的所有li标签,再对每一个li标签作遍历,然后再提取想要的信息。
3. 定位帖子的标题
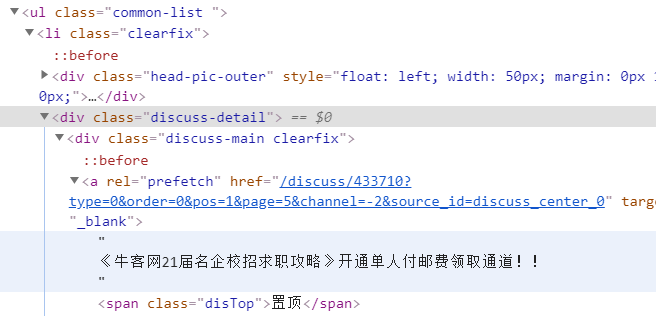
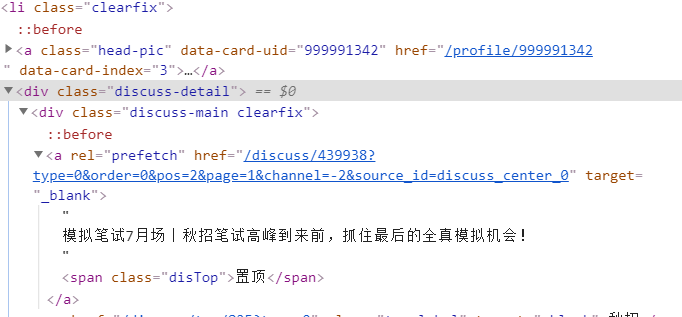
一般来说标题所在的位置应该都是固定的,并且是通用的,但牛客网的标题的位置有两种,所以在做标签定位时要做两种。
4 . 获取帖子的点赞量,浏览量,回帖数等信息。
如果获取的信息当前页面都可以找到,如
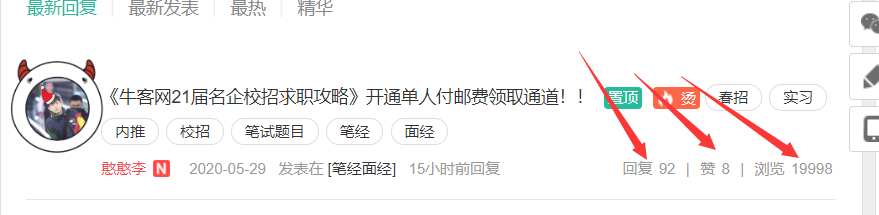
直接进行标签定位即可。
5. 获取所有页面的帖子信息
我们已经获取了当前页面的帖子信息后,还不够,我们的目标是获取所有的页面的信息。
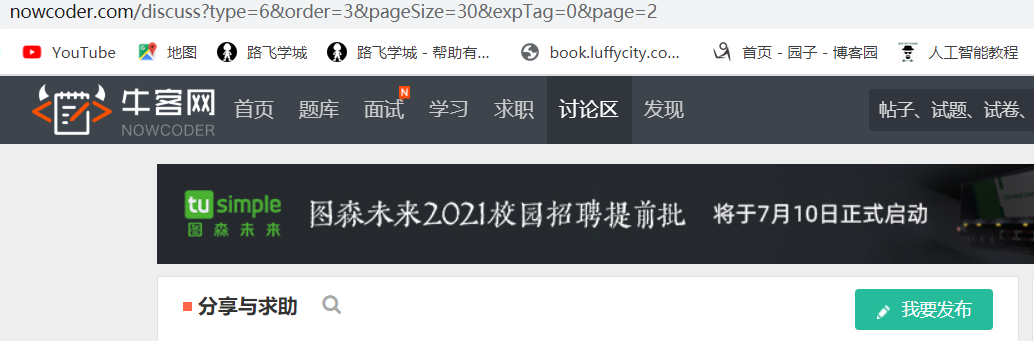
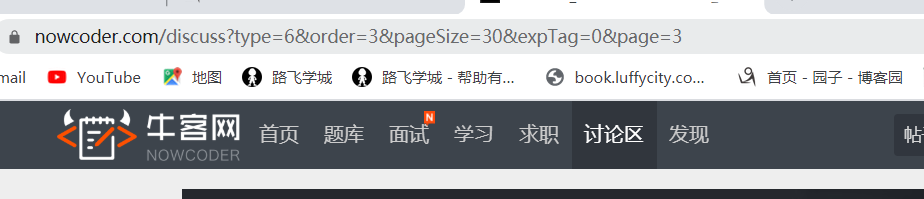
从这两张图中,可以看出不同的页面所改变的只是page=?的参数,因此如果想遍历所有的页面,就只需要对page后的参数进行循环赋值。
6.获取所有模块的所有页面的帖子信息
我们再扩大范围,我们获取所有模块的所有帖子的信息。

我们再来观察一下不同的模块会有什么不同
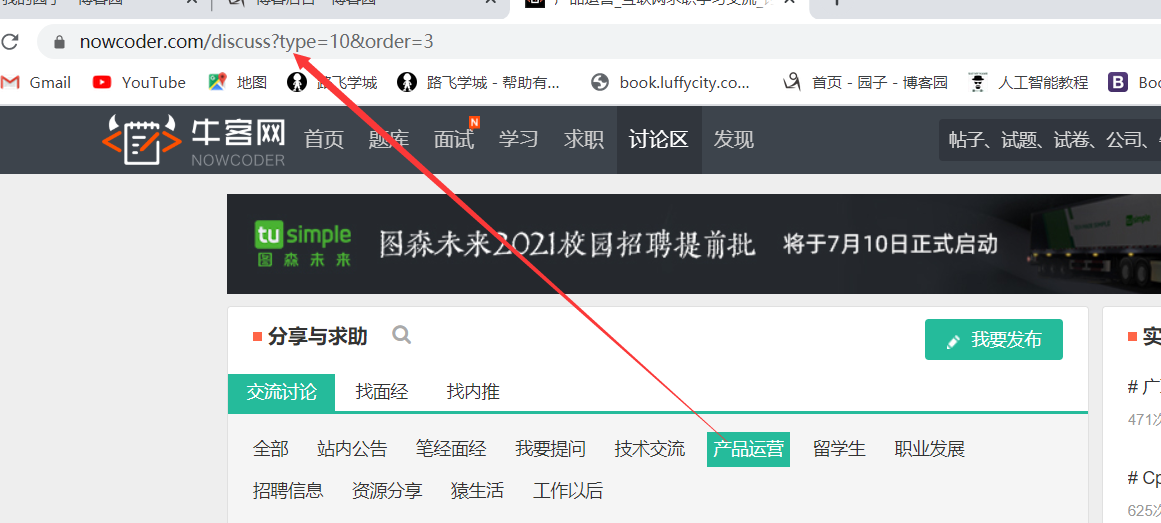
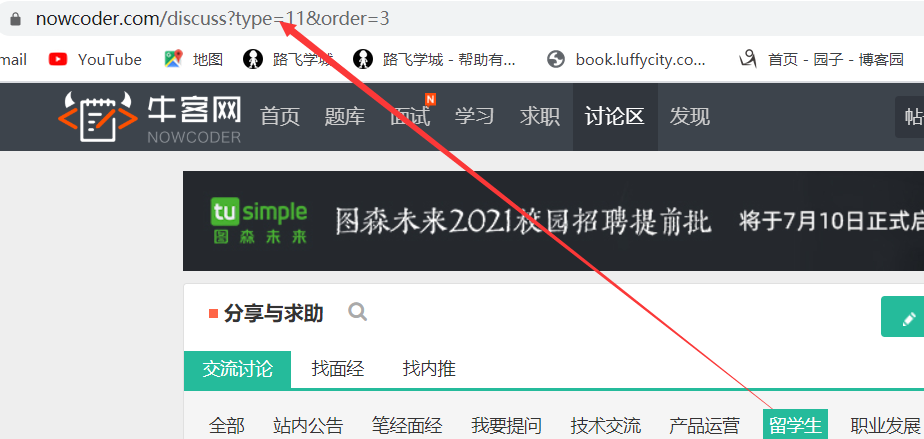
不难发现,不同的模块在url中不同的部分体现在type上,因此只需要对type参数进行循环赋值我们就可以拿到所有模块的信息。
7.还有哪些发现
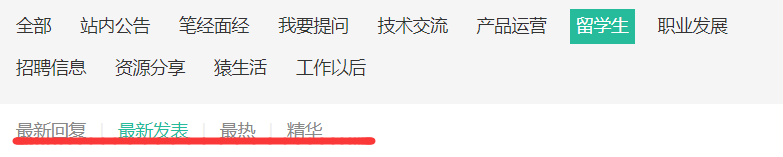
我们可以每一个模块下都有这几个部分,那么如何爬取这几个栏目下的帖子信息呢?我们再来观察。
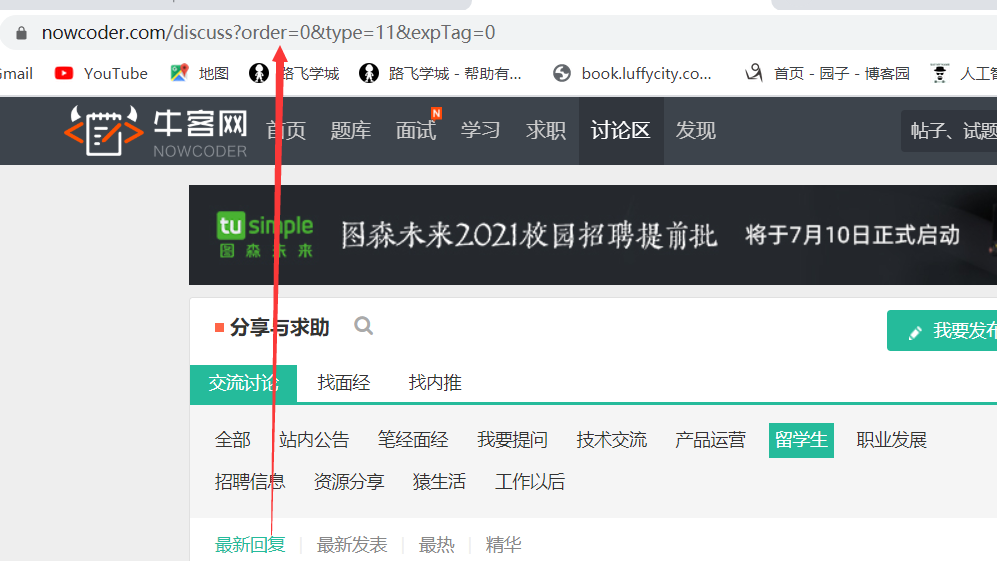
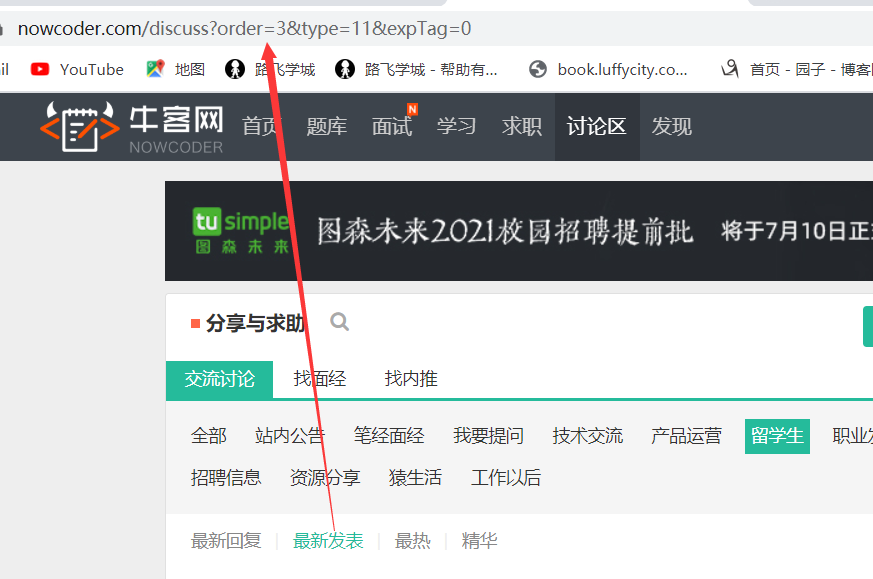
似乎只是order不一样。
8 总结:通过对牛客网的探索,我们知道只要通过page、type、order的参数的改变就可以拿到不同的帖子信息,page对应页码,type对应模块,order对应模块下四个小版块。
9 代码编写
import requests from lxml import etree from multiprocessing.dummy import Pool def parse(dic): """请求并解析数据""" # 得到目标url url = dic.get('url') # UA伪装 headers = dic.get('headers') # 得到文件句柄 f = dic.get('f') # 获取页面的源码数据 page_text = requests.get(url=url, headers=headers).text # 标签定位 tree = etree.HTML(page_text) # 定位到所有的li标签 li_list = tree.xpath('//div[@class="module-body"]/ul/li') # 获取模块的名称 有些模块名不在一个地方 try: model_name = tree.xpath('//div[@class="discuss-tab-wrap"]/a[@class="discuss-tab selected"]/text() ')[0] except IndexError: model_name = tree.xpath('/html/body/div[1]/div[2]/div[2]/div/div[2]/ul/li[2]/a/text()')[0] # 遍历每一个帖子 for li in li_list: try: title = li.xpath('./div/div[1]/a[1]/text() | ./div[2]/div[1]/a/text() ')[0] # 标题 num = li.xpath('./div/div[2]/div[2]/span[5]/span/text()')[0] # 浏览量 up = li.xpath('./div/div[2]/div[2]/span[3]/span/text()')[0] # 点赞量 content_num = li.xpath('./ div / div[2] / div[2] / span[1] / span/text()')[0] # 回帖数 # 以不同方式写入文件 看你想要什么 f.write(title + ' 浏览量' + str(num) + ' 点赞量' + str(up) + ' 评论数' + str(content_num)) # f.write(title+model_name) # f.write(title) except IndexError: continue if __name__ == '__main__': # 所要爬取的目标网址 url = 'https://www.nowcoder.com/discuss?type=0&order=0' # UA伪装 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' } # 创建要写入的目标文件 with open('c.txt', 'w', encoding='utf-8') as f: pool = Pool(10) page_num = 1 urls = [] # 遍历所有的模块 for i in range(13): # 每一次遍历新模块时,从第一页开始 page_num = 1 # 遍历所有的页面 while page_num <= 100: new_url = 'https://www.nowcoder.com/discuss?type=%s&order=4&pageSize=30&expTag=0&page=%s' url = format(new_url % (i, page_num)) print(url) # 线程池就是这么玩的 传入字典 固定格式 dic = { 'url': url, 'headers': headers, 'f': f # 文件句柄 } urls.append(dic) # 每一次循环页码+1 page_num += 1 # 将urls中的每个元素 传给parse函数执行 pool.map(parse, urls) # 关闭线程池 pool.close() # 等待主进程结束 pool.join()
10 获取高频词汇 生成词云图
这里你只需要改变几个参数,就可以生成所需的词云图。
import re # 正则表达式库 import collections # 词频统计库 import numpy as np # numpy数据处理库 import jieba # 结巴分词 import wordcloud # 词云展示库 from PIL import Image # 图像处理库 import matplotlib.pyplot as plt # 图像展示库 # 读取文件 fn = open('你的文件路径', 'rt', encoding='utf-8') # 打开文件 string_data = fn.read() # 读出整个文件 fn.close() # 关闭文件 # 文本预处理 pattern = re.compile(u' | |.|-|:|;|)|(|?|"') # 定义正则表达式匹配模式 string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除 print(string_data) # 导入自定义的词库 jieba.load_userdict('user_dict.txt') # 文本分词 seg_list_exact = jieba.cut(string_data, cut_all=False) # 精确模式分词 object_list = [] remove_words = [u'的', u',', u'和', u'是', u'随着', u'对于', u'对', u'等', u'能', u'都', u'。', u' ', u'、', u'中', u'在', u'了', u'通常', u'如果', u'我们', u'需要', u'吗', u'(',u'(',u')', u')', u'?', u'招银',u'什么',u'请问',u'我',u'去',u'?', u'有',u'批',u'啊',u'有人',u'有没有',u'呀',u'怎么',u'!',u'!', u'【',u'】',u'/',u'提前',u'全部',u'公告',u'内',u'推',u'求',u'+'] # 自定义去除词库 for word in seg_list_exact: # 循环读出每个分词 if word not in remove_words: # 如果不在去除词库中 object_list.append(word) # 分词追加到列表 # 词频统计 word_counts = collections.Counter(object_list) # 对分词做词频统计 word_counts_top10 = word_counts.most_common(10) # 获取前10最高频的词 print(word_counts_top10) # 输出检查 # 词频展示 mask = np.array(Image.open('a.jpg')) # 定义词频背景 wc = wordcloud.WordCloud( font_path='kumo.ttf', # 设置字体格式 mask=mask, # 设置背景图 max_words=200, # 最多显示词数 max_font_size=100 # 字体最大值 ) wc.generate_from_frequencies(word_counts) # 从字典生成词云 image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案 wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案 plt.imshow(wc) # 显示词云 plt.axis('off') # 关闭坐标轴 plt.show() # 显示图像
1.读取文件时,改变文件路径即可获得不同的词云图
2.如果你想有你的自定义词库,只需要自己创建一个txt文件,每一行单独写一个词。
然后在词云图的py文件中jieba.load_userdict('user_dict.txt') 即可。
3.去除词库,通过remove_words可以将词云图中你不想要的字符出去。
5.mask参数,就是你生成的词云图的背景,通过加载不同的图片,就可以生成不同的词云图。
效果图附上:两万五千多条数据生成的词云图

总结一下爬取过程中遇到的坑:
1. 帖子的定位,一开始会定位空的帖子,导致程序报错,经过筛查发现帖子的位置有两种,因此xpath要写两个表达式。
2. 爬取模块类别时,有的模块是会跳转到一个布局不同的新网页的,因此也要通过异常捕捉,使用不同的xpath表达式。