AdaBoost在我看理论课程的时候,以分类为例子来讲解的,谁知道sklearn里面基本上都有classifier和regressor两种。这个倒是我没想到的!!!
from sklearn.ensemble import AdaBoostRegressor

参数介绍:
base_estimator : object, optional (default=DecisionTreeRegressor)。基估计器,理论上可以选择任何回归器,但是这个地方需要支持样本加权重,as well as proper classes_ and n_classes_ attributes.(这个地方不过会翻译)。常用的是CART回归树和神经网络,默认CART回归树,即AdaBoostRegressor默认使用CART回归树DecisionTreeRegressor。
n_estimators : integer, optional (default=50)。基估计器的个数。
learning_rate : float, optional (default=1.)。即每个弱学习器的权重缩减系数νν,在原理篇的正则化章节我们也讲到了,加上了正则化项,我们的强学习器的迭代公式为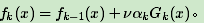
ν的取值范围为0<ν≤1。对于同样的训练集拟合效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的ν开始调参,默认是1。
loss : {‘linear’, ‘square’, ‘exponential’}, optional (default=’linear’)。Adaboost.R2算法需要用到。有线性‘linear’, 平方‘square’和指数 ‘exponential’三种选择, 默认是线性,一般使用线性就足够了,除非你怀疑这个参数导致拟合程度不好。这个值的意义,它对应了我们对第k个弱分类器的中第i个样本的误差的处理,即:
如果是线性误差,则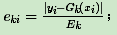
如果是平方误差,则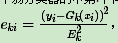
如果是指数误差,则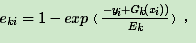
,Ek为训练集上的最大误差Ek=max|yi−Gk(xi)|i=1,2...m
random_state : int, RandomState instance or None, optional (default=None)
属性介绍:
estimators_ : list of classifiers
estimator_weights_ : array of floats
estimator_errors_ : array of floats
feature_importances_ : array of shape = [n_features]
方法介绍:

from sklearn.ensemble import AdaBoostClassifier

参数介绍:
base_estimator : object, optional (default=DecisionTreeClassifier)。基估计器,理论上可以选择任何分类器,但是这个地方需要支持样本加权重,as well as proper classes_ and n_classes_ attributes.(这个地方不过会翻译)。常用的是CART决策树和神经网络,默认CART决策树,即AdaBoostClassifier默认使用CART决策树DecisionTreeClassifier。
n_estimators : integer, optional (default=50)。基估计器的个数。
learning_rate : float, optional (default=1.)。通过这个参数缩减每个分类器的贡献,learning_rate和n_estimators 两个参数之间存在权衡。
algorithm : {‘SAMME’, ‘SAMME.R’}, optional (default=’SAMME.R’)。如果'SAMME.R'则使用SAMME.R (Real Boosting) 算法。 base_estimator必须支持类概率的计算。 如果'SAMME'则使用SAMME (discrete boosting) 算法。 SAMME.R算法通常收敛速度高于SAMME,通过较少的升压迭代实现较低的测试误差。(老哥们有好的翻译理解记得评论下!)
如果我们选择的AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba。
两者的主要区别是弱学习器权重的度量,SAMME使用了和我们的原理篇里二元分类Adaboost算法的扩展,即用对样本集分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值也是SAMME.R。我们一般使用默认的SAMME.R就够了,但是要注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。SAMME算法则没有这个限制。
random_state : int, RandomState instance or None, optional (default=None)。如果int,random_state是随机数生成器使用的种子; 如果RandomState的实例,random_state是随机数生成器; 如果None,则随机数生成器是由np.random使用的RandomState实例。
属性介绍:
estimators_ : list of classifiers 子估计器
classes_ : array of shape = [n_classes] 类别的标签信息
n_classes_ : int 类别的数量
estimator_weights_ : array of floats 每个基估计器的权重
estimator_errors_ : array of floats 每个基估计器的错误率
feature_importances_ : array of shape = [n_features] 如果基估计器支持的话
“具体调参”参考博客
调参还是分为两部分:AdaBoost框架调参和弱分类器的调参。
框架参数调节:
框架参数就是值上述介绍的那些需要动态调节观察效果的参数。
弱分类器参数调节:
这里我们仅仅讨论默认的决策树弱学习器的参数。即CART分类树DecisionTreeClassifier和CART回归树DecisionTreeRegressor。