在处理深度学习分类问题时,会用到一些评价指标,如accuracy(准确率)等。刚开始接触时会感觉有点多有点绕,不太好理解。本文写出我的理解,同时以语音唤醒(唤醒词识别)来举例,希望能加深理解这些指标。
1,TP / FP / TN / FN
下表表示为一个二分类的混淆矩阵(多分类同理,把不属于当前类的都认为是负例),表中的四个参数均用两个字母表示,第一个字母表示判断结果正确与否(正确用T(True),错误用F(False),第二个字母表示判定结果(正例用P(Positive),负例用N(Negative))。四个参数的具体意思如下:
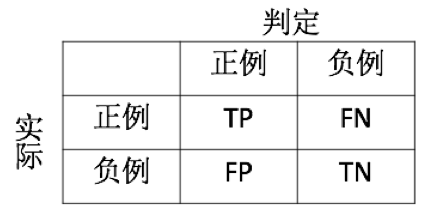
TP (True Positive):表示实际为正例,判定也为正例的次数,即表示判定为正例且判定正确的次数。
FP (False Positive): 表示实际为负例,却判定为正例的次数,即表示判定为正例但判断错误的次数。
TN (True Negative):表示实际为负例,判定也为负例的次数,即表示判定为负例且判定正确的次数。
FN (False Negative): 表示实际为正例,却判定为负例的次数,即表示判定为负例但判断错误的次数。
为了帮助理解,我以智能音箱中的语音唤醒(假设唤醒词为“芝麻开门”)来举例。这里正例就是唤醒词“芝麻开门”,负例就是除了“芝麻开门”之外的其他词,即非唤醒词,如“阿里巴巴”。设定评估时说唤醒词和非唤醒词各100次,TP就表示说了“芝麻开门”且被识别的次数(假设98次),FN就表示说了“芝麻开门”却没被识别(判定成负例)的次数(假设2次),FP就表示说了非唤醒词却被识别(判定成正例)的次数(假设1次),TN就表示说了非唤醒词且没被识别的次数(假设99次)。
2,accuracy / precision / recall
accuracy是准确率,表示判定正确的次数与所有判定次数的比例。判定正确的次数是(TP+TN),所有判定的次数是(TP + TN + FP +FN),所以

在语音唤醒例子中,TP = 98,TN = 99,FP = 1, FN = 2, 所以accuracy = (98 + 99) / (98 + 99 + 1 + 2) = 98.5%,即准确率为 98.5%。
precision是精确率,表示正确判定为正例的次数与所有判定为正例的次数的比例。正确判定为正例的次数是TP,所有判定为正例的次数是(TP + FP),所以

在语音唤醒例子中,TP = 98, FP = 1, 所以precision = 98 / (98 + 1) = 99%,即精确率为 99%。
recall是召回率,表示正确判定为正例的次数与所有实际为正例的次数的比例。正确判定为正例的次数是TP,所有实际为正例的次数是(TP + FN),所以
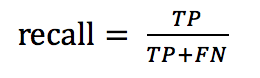
在语音唤醒例子中,TP = 98, FN = 2, 所以recall = 98 / (98 + 2) = 98%,即召回率为 98%。在语音唤醒场景下,召回率也叫唤醒率,表示说了多少次唤醒词被唤醒次数的比例。
1, FAR / FRR
FAR (False Acceptance Rate)是错误接受率,也叫误识率,表示错误判定为正例的次数与所有实际为负例的次数的比例。错误判定为正例的次数是FP,所有实际为负例的次数是(FP + TN),所以
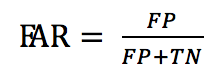
在语音唤醒例子中,FP = 1, TN = 99, 所以FAR = 1 / (99 + 1) = 1%,即错误接受率为 1%。在语音唤醒场景下,错误接受率也叫误唤醒率,表示说了多少次非唤醒词却被唤醒次数的比例。
FRR (False Rejection Rate)是错误拒绝率,也叫拒识率,表示错误判定为负例的次数与所有实际为正例的次数的比例。错误判定为负例的次数是FN,所有实际为正例的次数是(TP + FN),所以

在语音唤醒例子中,FN = 2, TP = 98, 所以FRR = 2/ (2 + 98) = 2%,即错误拒绝率为 2%。在语音唤醒场景下,错误拒绝率也叫不唤醒率,表示说了多少次唤醒词却没被唤醒次数的比例。
2, ROC曲线 / EER
ROC(receiver operating characteristic curve)曲线是“受试者工作特征”曲线,是一种已经被广泛接受的系统评价指标,它反映了识别算法在不同阈值上,FRR(拒识率)和FAR(误识率)的平衡关系。ROC曲线中横坐标是FRR(拒识率),纵坐标是FAR(误识率),等错误率(EER Equal-Error Rate)是拒识率和误识率的一个平衡点,等错误率能够取到的值越低,表示算法的性能越好。
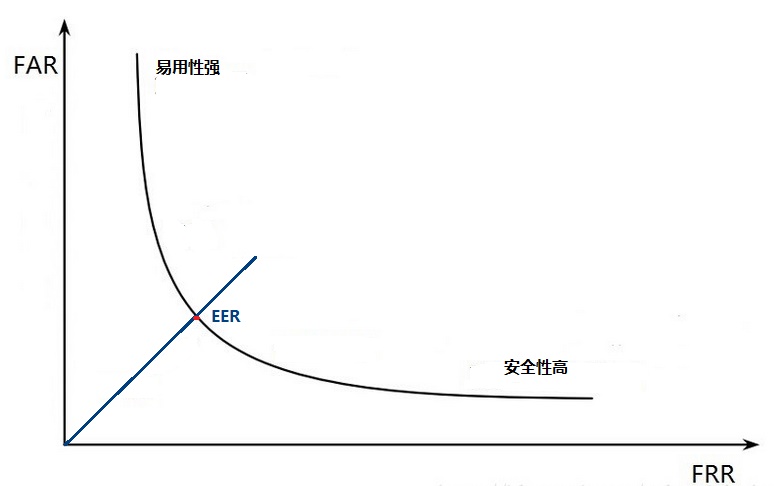
上图是ROC曲线的示意图,我从语音唤醒的场景来解释。从上图看出FRR低/FAR高时,即拒识率低、误识率高时,智能音箱很容易被唤醒,即很好用。FRR高/FAR低时,即拒识率高、误识率低时,智能音箱不容易被唤醒,即不太方便用,但是很难误唤醒,安全性很高。真正使用时要找到一个FAR和FRR的平衡点(EER),也就是不那么难唤醒,方便使用,同时也不会有高的误唤醒,保证安全。