什么是线程池
在 Java 中,如果每个请求到达就创建一个新线程,创建和销毁线程花费的时间和消耗的系统资源都相当大,甚至可能要比在处理实际的用户请求的时间和资源要多的多。如果在一个 Jvm 里创建太多的线程,可能会使系统由于过度消耗内存或“切换过度”而导致系
统资源不足。
为了解决这个问题,就有了线程池的概念,线程池的核心逻辑是提前创建好若干个线程放在一个容器中。如果有任务需要处理,则将任务直接分配给线程池中的线程来执行就行,任务处理完以后这个线程不会被销毁,而是等待后续分配任务。同时通过线程池来重复管理线程还可以避免创建大量线程增加开销。
线程池的优势
合理的使用线程池,可以带来一些好处
1. 降低创建线程和销毁线程的性能开销
2. 提高响应速度,当有新任务需要执行是不需要等待线程创建就可以立马执行
3. 合理的设置线程池大小可以避免因为线程数超过硬件资源瓶颈带来的问题
Java 中提供的线程池 API
相信有很多同学或多或少都接触过线程池,也可能自己也研究过线程池的原理。但是要想合理的使用线程池,那么势必要对线程池的原理有比较深的理解。
线程池的使用
要了解一个技术,我们仍然是从使用开始。JDK 为我们提供了几种不同的线程池实现。我们先来通过一个简单的案例来引入线程池的基本使用。
在 Java 中怎么创建线程池呢?下面这段代码演示了创建三个固定线程数的线程池。
public class Test implements Runnable {
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
static ExecutorService service = Executors.newFixedThreadPool(3);
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
service.execute(new Test());
}
service.shutdown();
}
}
Java 中提供的线程池 Api
为了方便大家对于线程池的使用,在 Executors 里面提供了几个线程池的工厂方法,这样,很多新手就不需要了解太多关于 ThreadPoolExecutor 的知识了,他们只需要直接使用Executors 的工厂方法,
就可以使用线程池:
newFixedThreadPool:该方法返回一个固定数量的线程池,线程数不变,当有一个任务提交时,若线程池中空闲,则立即执行,若没有,则会被暂缓在一个任务队列中,等待有空闲的线程去执行。
newSingleThreadExecutor: 创建一个线程的线程池,若空闲则执行,若没有空闲线程则暂缓在任务队列中。
newCachedThreadPool:返回一个可根据实际情况调整线程个数的线程池,不限制最大线程数量,若用空闲的线程则执行任务,若无任务则不创建线程。并且每一个空闲线程会在 60 秒后自动回收
newScheduledThreadPool: 创建一个可以指定线程的数量的线程池,但是这个线程池还带有延迟和周期性执行任务的功能,类似定时器。
ThreadpoolExecutor
上面提到的四种线程池的构建,都是基于 ThreadpoolExecutor 来构建的,小伙伴们打起精神来了,接下来将一起了解一下面试官最喜欢问到的一道面试题“请简单说下你知道的线程池和ThreadPoolThread 有哪些构造参数”
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
ThreadpoolExecutor 有多个重载的构造方法,我们可以基于它最完整的构造方法来分析先来解释一下每个参数的作用,稍后我们在分析源码的过程中再来详细了解参数的意义。
public ThreadPoolExecutor(int corePoolSize, //核心线程数量 int maximumPoolSize, //最大线程数 long keepAliveTime, //超时时间,超出核心线程数量以外的线程空余存活时间 TimeUnit unit, //存活时间单位 BlockingQueue<Runnable> workQueue, //保存执行任务的队列 ThreadFactory threadFactory,//创建新线程使用的工厂 RejectedExecutionHandler handler //当任务无法执行的时候的处理方式)
线程池里的线程的初始化与其他线程一样,但是在完成任务以后,该线程不会自行销毁,而是以挂起的状态返回到线程池。直到应用程序再次向线程池发出请求时,线程池里挂起的线程就会再度激活执行任务。这样既节省了建立线程所造成的性能损耗,也可以让多个任务反复重用同一线程,从而在应用程序生存期内节约大量开销。
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
FixedThreadPool 的核心线程数和最大线程数都是指定值,也就是说当线程池中的线程数超过核心线程数后,任务都会被放到阻塞队列中。另外 keepAliveTime 为 0,也就是超出核心线程数量以外的线程空余存活时间而这里选用的阻塞队列是 LinkedBlockingQueue,使用的是默认容量 Integer.MAX_VALUE,相当于没有上限
这个线程池执行任务的流程如下:
1. 线程数少于核心线程数,也就是设置的线程数时,新建线程执行任务2. 线程数等于核心线程数后,将任务加入阻塞队列
3. 由于队列容量非常大,可以一直添加
4. 执行完任务的线程反复去队列中取任务执行
用途:FixedThreadPool 用于负载比较大的服务器,为了资源的合理利用,需要限制当前线程数量
newCachedThreadPool
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
CachedThreadPool 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程; 并且没有核心线程,非核心线程数无上限,但是每个空闲的时间只有 60 秒,超过后就会被回收。
它的执行流程如下:
1. 没有核心线程,直接向 SynchronousQueue 中提交任务
2. 如果有空闲线程,就去取出任务执行;如果没有空闲线程,就新建一个
3. 执行完任务的线程有 60 秒生存时间,如果在这个时间内可以接到新任务,就可以继续活下去,否则就被回收
newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
线程池的实现原理分析
线程池的基本使用我们都清楚了,接下来我们来了解一下线程池的实现原理。
ThreadPoolExecutor 是线程池的核心,提供了线程池的实现。ScheduledThreadPoolExecutor 继承了 ThreadPoolExecutor,并另外提供一些调度方法以支持定时和周期任务。Executers 是工具类,主要用来创建线程池对象
我们把一个任务提交给线程池去处理的时候,线程池的处理过程是什么样的呢?首先直接来看看定义
线程池原理分析(FixedThreadPool)
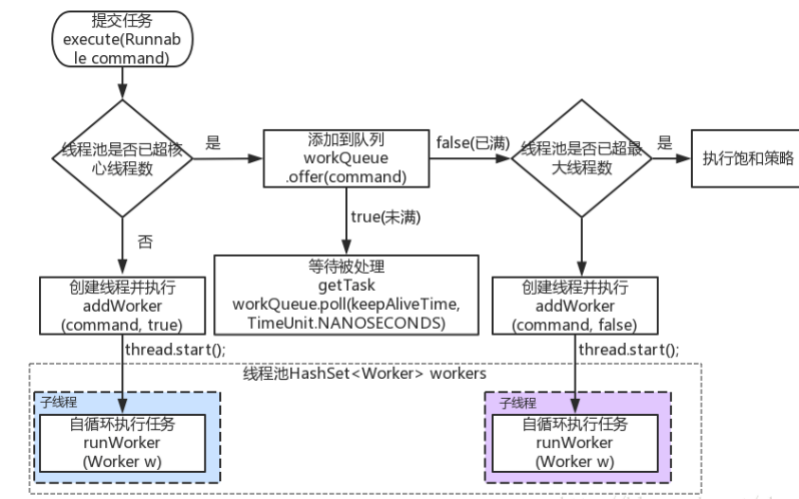
源码分析
execute
基于源码入口进行分析,先看 execute 方法:
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) {//1.当前池中线程比核心数少,新建一个线程执行任务 if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) {//2.核心池已满,但任务队列未满,添加到队列中 int recheck = ctl.get(); //任务成功添加到队列以后,再次检查是否需要添加新的线程,因为已存在的线程可能被销毁了 if (!isRunning(recheck) && remove(command)) reject(command);//如果线程池处于非运行状态,并且把当前的任务从任务队列中移除成功,则拒绝该任务 else if (workerCountOf(recheck) == 0)//如果之前的线程已被销毁完,新建一个线程 addWorker(null, false); } else if (!addWorker(command, false)) //3.核心池已满,队列已满,试着创建一个新线程 reject(command); //如果创建新线程失败了,说明线程池被关闭或者线程池完全满了,拒绝任务 }
addWorker
如果工作线程数小于核心线程数的话,会调用 addWorker,顾名思义,其实就是要创建一个工作线程。我们来看看源码的实现源码比较长,看起来比较唬人,其实就做了两件事。
1)调用循环 CAS 操作来将线程数加 1;
2)新建一个线程并启用。
拒绝策略
1、AbortPolicy:直接抛出异常,默认策略;
2、CallerRunsPolicy:用调用者所在的线程来执行任务;
3、DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
4、DiscardPolicy:直接丢弃任务;
当然也可以根据应用场景实现 RejectedExecutionHandler 接口,自定义饱和策略,如记录日志或持久化存储不能处理的任务