SQL规范与性能
说明:仅针对mysql 5.5.21 +
innodb存储引擎
文档版本: v1.0
一. 索引的优缺点
(1)、优点:加快查询速度
(2)、缺点:增加DML的维护成本
#从下图可以看出,增加5个索引后,插入同样的数据量时间由0.02s->0.04s,
增加了插入的时间;

二. innodb索引特点与原理&explain
2.1 innodb索引特点
(1)、组合索引最左侧原则(一般情况:最左侧索引列须存在于where条件中)
(2)、聚簇索引与辅助索引关联: 每个普通索引(辅助索引,有些称为二级索引)的索引列后会自动添加主键列键值)
#箭头方向代表:根据辅助索引列的后面自动添加的主键值访问主键索引(聚集索引),再通过聚焦索引的值来访问对应的行;

(3)、包含键值且键值按大小排序存放,如以下2列组合索引值的存放顺序:a->b->c, 同时为a类的后面列值也是按序排序:1->2
('a',1),('a',2),('b',1),('b',2),('b',3),('c',1),('c',2)
2.2 explain查看执行计划
 主要讲述type类型(如下表性能从左到右,由低向高)
主要讲述type类型(如下表性能从左到右,由低向高)
ALL | index | range | ref | eq_ref | const,system | NULL |
ALL: 全表扫描 ,index: 索引全扫描 ,range: 索引范围扫描 ,ref: 使用非唯一索引或唯一索引前缀扫描 ,eq_ref: 使用主键或唯一索引扫描 ,const,system: 查询结果最多有一行匹配 ,NULL: 不用访问表或索引直接得出结果;
三.创建索引列的选择判断
#对于表上的哪些列需要创建索引,哪些不适合创建索引:
(1)、根据日常查询SQL的需求,where条件中包含哪些列,综合考虑;
(2)、根据结果集以及列的基数判断;
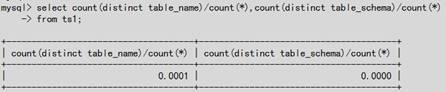
#如下图,考虑table_name值’EVENTS’,table_schema值’test’所占的结果集大小,可以看出数据量很大;

#如下图,可看出此两列的选择率(基数)很差,不适合建索引;
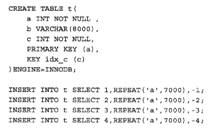
四. 索引规范与性能
#ts1,ts2的表行数

4.1 join连接方式代替子查询
#如下在等逻辑的修改下,嵌套子查询较慢(2.02s),这是当前mysql的一个不足;
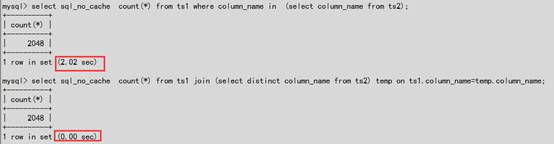
4.2索引在外嵌套层(派生表)失效
#在逻辑的条件下:尽量将过滤条件置,以减少后续的结果集数量和使用上索引;


#从下图可看到时当将索引列放置于外层时(temp外)将不能使用上索引;等价修改放置里层后可使用上索引,执行时间从1.86s->0.00s

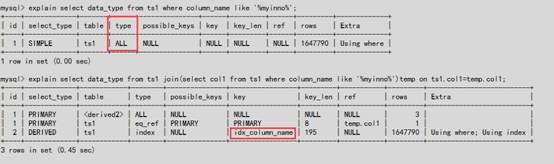
4.3 like如何利用索引
4.3.1 放置于”%”前

4.3.2 通过idx_column_name索引后的主键的关系来匹配使用索引,相对于全表扫描执行的时间上从1.43->0.61s
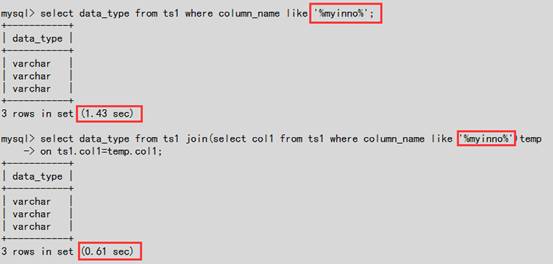
#从执行计划可以看出改写后的SQL使用上索引idx_column_name
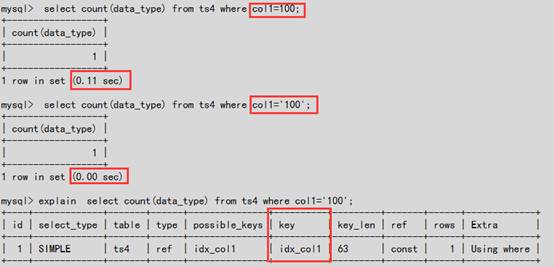
4.4字符类型隐性转换导致索引失效
#其中表ts4.col1列的类型为varchar

#从下图看出当数值100加上单引后可使用上索引(idx_col1),执行时间上也由0.11s->0.00s
4.5勿对索引列修饰(比如:对列计算,对列使用函数等)
4.5.1 对索引列的算术运算使用索引失效

#从下图可看出,=左边计算的表达式等价移到右边后可使用上索引

4.5.2 #索引列加上函数后导致索引失效
#其中列ts5.create_time为datetime类型
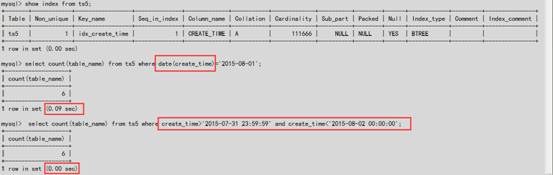
#经过等价的改写后可使用上索引idx_create_time

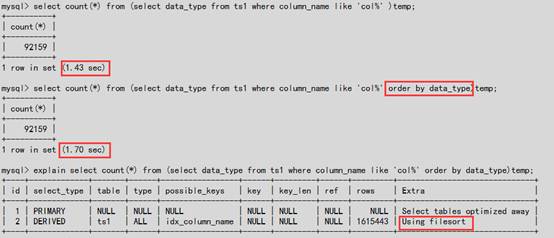
4.6去除不必要的order by,group by
#如下图对于统计总数的查询没有必要在派生表temp内使用order by;额外的排序使用SQL执行时间从1.43s->1.70s
#从下图中看出对于group by 的结果默认会进行排序,如果结果无排序要求可考虑加入order by null来取消排序;

4.7去除不必要的外嵌套层
#如下图:对于等逻辑的写法尽量不要加入嵌套层,执行的时间从0.03s->52.95s

#从下图执行计划看出:没有嵌套层的语句优化器选择采用索引的方式,而有嵌套层的则采用全表扫描;

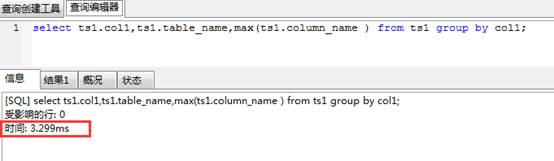
4.8减少不必要的自连接
#如下图:在使用自连接的时候,对于等逻辑的改写可考虑采用mysql的group by用法来消除不必要的自连接;执行时间上由8.569s->3.299s

4.9利用索引避免排序(order by )

#如上图:
第1条: where条件的索引列与order by为两个独立的索引引起filesort;
第2条: where条件的索引顺序读取已排好序的数据;
第3条: 虽然table_name上建有索引,但优化器认为全表扫描更快而产生filesort(type=ALL);
第4条:优化器认为直接从索引列上读取已排序好的数据更快;
#新增组合索引idx_name_schema


第5条:对于组合索引idx_name_schema,where条件与order by 的索引列都是已排好序的;
第6条:where条件与order by的索引列数据未排好序,主要由table_schema的”>”引起;
第7条:虽然order by后的索引列变为”desc”,但where条件=配合一起取出的数据是有序的,只是逆排序,避免了filesort;

第8条:table_name上有独立的索引,且该索引会自动加上主键列值,因而避免filesort;
第9条:对于主键列的访问,结果仅为1条,因而不存在排序;
第10条:由于order by 的两索引列不同的排序方式引起了数据的无序而产生的filesort;
4.10 where条件中or如何使用索引
#对于含有or的where条件列都应为索引列,否则将出现全表扫描;

#增加table_name的索引列后,与or相关的索引列都使用上了索引(index_merge);

4.11使用前缀索引与覆盖索引
4.11.1前缀索引: 对于较长列blob,longtext,varchar(n),可以截取前x位的字符来减少索引的大小(具体x的大小可多次通过统计总数来确定一个合适的值);
#如下图原来table_name列的分组数量和总分组数;截取前10个字符后此列值的分组数量(具体可抽样检查)和总分组数的变化(100 rows->87rows)


4.11.2覆盖索引: 避免了回表,由扫描表转化为扫描索引而使性能提高

第1条:优化器自动选择一索引列进行全索引扫描(索引比表小);
第2条:索引idx_name_schema上已包含所有的table_name值,优化器选择全索引扫描;
第3条: 索引列table_schema上含有主键列上的值因而避免了回表;
第4条:table_name与where条件的索引列table_schema没有关联,需要回表取值;
4.12使用索引最左侧特性

对于上图:
第1条:刚好与组合索引idx_name_schema匹配;
第2条:table_name为非最左侧索引而产生了全表扫描;
第3条:最左侧列匹配%后放在后面可以使用上索引与第一句类似;
第4条:最左侧索引由于两个%失效而产生了全表扫描;

对于上图(含有3列的组合索引):
第1条与第2条:同为存在最左侧索引列table_schema,因而可使用上索引;
第3条:由于table_name为非最左侧索引导致索引失效;
五.注意事项
脚本提交时,需用 utf-8 编码保存,脚本文件名不要有中文。