在代码执行的过程中,我们为了使完成相同功能的代码合在一起,避免代码的冗余,今天,就来谈谈关于方法的一些理解吧!
1.方法
(当在程序中需要重复使用某段逻辑或者功能,将这段逻辑提取出来形成一种新的形式 --- 方法)
1.1 定义格式
修饰符 返回值类型 方法名(参数列表){
方法体;
return 返回值;
}
练习:
1.哥德巴赫猜想:任何一个大于 6 的偶数都可以分解成两个质数之和。
16 = 3 + 13
16 = 5 + 11
输入大于等于 6 的偶数,然后输入它所有的分解形式
20 = 3 + 17
20 = 7 +13
思路:在这个过程中要重复执行的代码是判断质数
for(int i = 3; i < n; i++){
}
//判断一个数字 n 是否是一个质数
public static boolean isPrime(int n){
//判断是否符合范围
if(n < 2)
return false;
if(n == 2)
return true;
if(n % 2 == 0)
return false;
for(int i = 3; i <= n/2; i++){
if(n % i == 0)
return false;
}
return true;
}
public static void print(int n){
if(n % 2 != 0 || n < 6){
System.out.println("输入不合法");
}else{
for(int i = 3; i <= n/2; i++){
if(isPrime(i) && isPrime(n - i)){
System.out.println(n + "=" + i + "+" + (n - i));
}
}
}
}
2.亲密数:如果 A 的所有因子(含 1 而不含本身)之和等于 B,而且 B 的所有因子(含 1 而不含本身)之和等于 A ,A 和 B 就是一对亲密数
16:1+2+4+8 = 15
15:1+3+5 = 9
打印 5000 以内所有的亲密数
思路:需要重复执行的逻辑是获取一个数的所有因子之和
/**亲密数:如果 A 的所有因子(含 1 而不含本身)之和等于 B,而且 B 的所有因子(含 1 而不含本身)之和等于 A ,A 和 B 就是一对亲密数
16:1+2+4+8 = 15
15:1+3+5 = 9
打印 5000 以内所有的亲密数
思路:需要重复执行的逻辑是获取一个数的所有因子之和
*/
public class MethodDemo2{
public static void main(String[] args){
for(int a = 1; a <= 5000; a++){
int b = sumAllFact(a);
int i = sumAllFact(b);
if(i == a && a < b){
System.out.println(a+","+b);
}
}
}
//一个数的所有因子之和
public static int sumAllFact(int n){
int sum = 0;
for(int i = 1; i <= n/2; i++){
if(n % i == 0){
sum += i;
}
}
return sum;
}
}
1.2方法的重载
在同一个类中,存在了方法名一致而参数列表不同(参数个数不同或者是对应位置上的参数类型不同)的方法 --- 方法的重载 --- 依靠参数列表来区分调用的方法
方法在调用的时候会进行模糊匹配 --- 参数类型在没有最符合的情况下会自动提升,就会导致提升之后可能会有多个匹配
main(String[] args) args 可以换成任何的一个字符串
System.out.println();
Arrays.toString();
Arrays.sort();
1.3方法的传值
主函数在栈中占用一片空间,另一个方法也会再开辟一片空间(里面的参数在里面再占用一片空间,在里面进行值的改变)。但栈的特点是用完就释放,所以在主函数中打印值还是那个。
但是像传入一个地址的情况,值就会发生改变,因为传的是一个地址,改变的过程是在堆中,所以即便栈中的那个方法用完就释放了,但是值已经在堆中改变了。

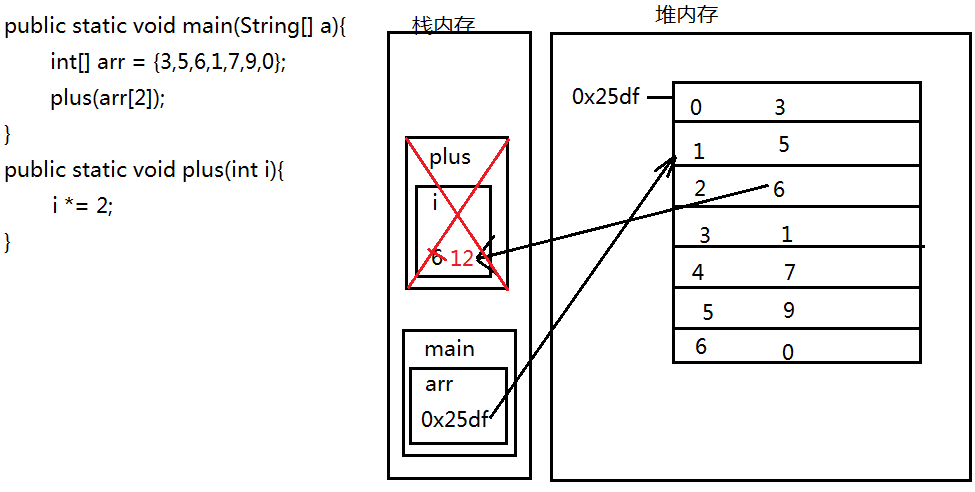
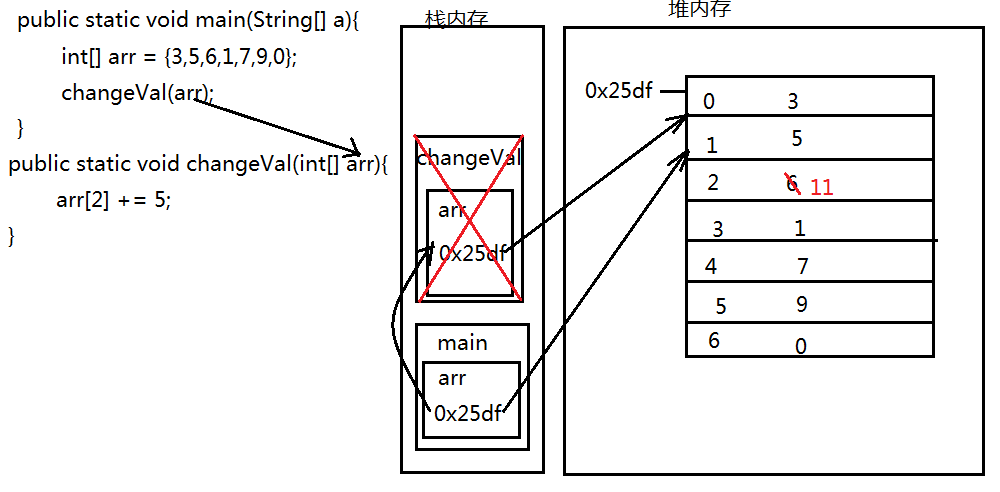
注意:
1.方法是在栈内存中执行
2.方法在传值的时候,基本类型传的实际值,数组传递的是地址
3.传递地址之后,如果地址没有发生改变,则代码执行影响原来的数组;如果地址发生了改变,则代码执行不影响原来的数组。
1.4方法的递归
展现形式:方法调用了自身
add(10) = 10 + add(9); --- 求前十项的和相当于第十项加上前 9 项的和
add(9) = 9 + add(8);
…
add(3) = 3 + add(2);
add(2) = 2 + add(1);
add(1) = 1;
练习:输入一个数字 n,求 n!
10 个阶梯,依次迈出 1 个或者 2 个阶梯,总共有多少种走法?
f(10) = f(9)+f(8)
f(9) = f(8) + f(7)
f(8) = f(7) + f(6)
…
f(3) = f(2) + f(1)
f(2) = 2
f(1) = 1
注意:在递归的时候,当执行次数过多会产生 StackOverflowError - 栈溢出错误
总结:在一些场景中,如果能确定这一项和前 n 项的关系,那么可以使用递归 --->逆推
/**10 个阶梯,依次迈出 1 个或者 2 个阶梯,总共有多少种走法?
*/
public static int step(int n){
if(n == 1)
return 1;
if(n == 2)
return 2;
return step(n - 1) + step(n - 2);
}
一些基本常识:
JAVESE 基本语法 面向对象 API(最容易翻车的部分) IDE --- 智能开发工具 Eclipse(日食) --- 免费、功能非常强大,基于插件(别人做好的,封装好的功能,就像小时候玩的游戏机插卡)、开源(开放源代码,官网找到源码,写出另一个,开源有的免费,有的收费)、绿色(以压缩包的形式,解压就能用) - SUN Kepler(开普勒,现在用的最古老的一个版本) -> Luna(月神,JDK1.8 不建议使用)-> Mars(火星,支持 JDK 的 5 个版本)->Neon(霓虹灯)->Oxygen(氧气,这是现在的最新版本,有很多的东西不是很稳定) Intelli J(社区版和专业版:提供了很多的定制,代码依赖管理,按年收费,)
2.面向对象
面向对象是一种思维方式,相对于面向过程而言的。(比如你吃过的东西,你去定义一下你吃的苹果,生活很常见的,定势思维,但是要描述很难)。
(吃下午茶,想吃蛋糕,得有这个蛋糕,要获取(一种,你自己做,一种你去买,准备材料,制作蛋糕,烘培蛋糕),每一个动作的执行者是你,很清楚着每一个步骤执行的细节,这就是面向过程)。然后不想做,想买,告诉糕点师(根据你想要的去制作材料,制作蛋糕,烘焙蛋糕),这个流程中执行者是糕点师,你在流程中起了一个发起者/主导者(你要看哪个糕点师做的好吃,这就是面向对象),不用管糕点师怎么去做,糕点师就是这个对象。
面向过程在流程中关注动作执行的每一个细节。 --- 自己动手做
面向对象重点找这个对象,只要找到了对象,那么这个对象所具有的功能就能够被使用 --- 找别人做(比如用的手机、电脑,要开机,就是有一个键(进行了面向对象的封装),不然你就要把电脑拆开,自己将线接上;还有去买洗衣机,他们的导购,就给你介绍这些,不然你得自己去了解这些资料。)
面向对象给我们带来了很多的好处,但不一定比面向过程好。(比如,你早上起床穿衣服,就是面向过程;而面向对象就像妃嫔,别人来穿,那样很有气场,但是效率低)--- 相对简单的事务建议使用面向过程,相对复杂的事务建议使用面向对象。
面向对象本身是基于面向过程的。
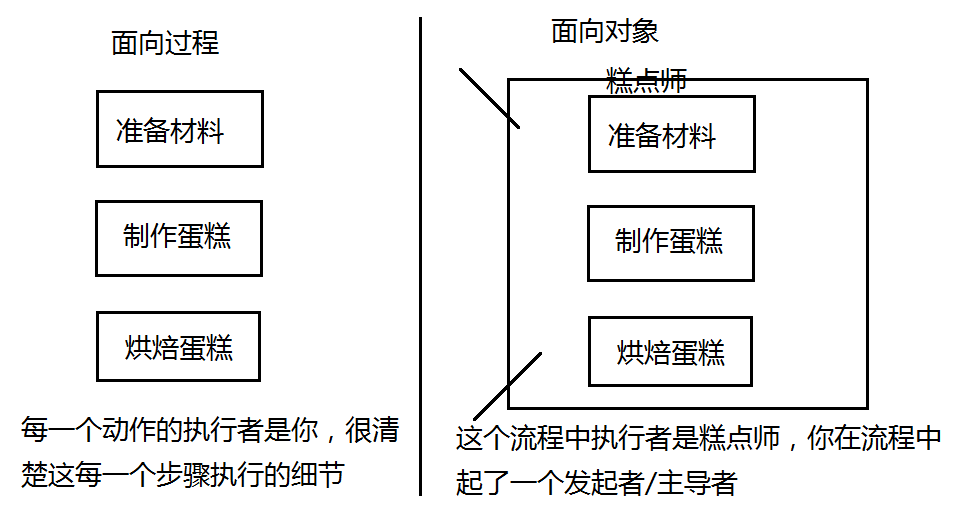
2.1类与对象的关系
根据一类对象进行抽取和总结,将这类对象的特征抽取成了属性,将这类对象的行为抽取成了方法,用类表示这一对象 -> 类是对象的抽取
(一个小人,姓名:翠花,性别:男,年龄:18,……,吃东西)(另一个小人,姓名:如花,性别:女,年龄:80,……,吃东西)
(第三个小人,姓名:如家,性别:男,年龄:40,……,吃东西)
人: class Person{ //代表人这一类对象
特征:姓名、性别、年龄… String name; 属性/成员变量
行为:吃东西 int age;
byte gender; //医学上有些双性人,facebook 和 推特上的性别有 50 多种,
//String 类型太占内存不用,0 表示男,1 表示女
public void eat( ){ }
}

2.2对象的内存存储
随着对象的创建,里面的属性也会跟着创建,并会自动赋值。
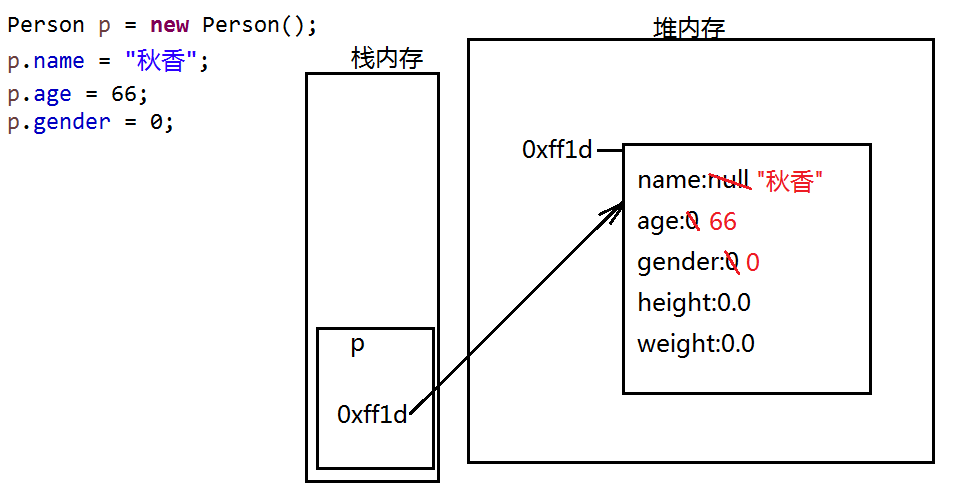
2.3成员变量和局部变量
1.定义位置:成员变量定义在类内方法外;局部变量是定义在方法或者语句里面
2.作用范围:成员变量作用在整个类内;局部变量是只能作用在定义它的方法或者语句中
3.内存位置:成员变量随着对象的创建而存在了堆内存中并且在堆内存中赋予了默认值;局部变量在栈内存中存储
4.生命周期:成员变量在对象创建的时候出现,在对象被回收的时候销毁;局部变量在方法或者语句执行的时候创建,方法或者语句执行完成之后就立即销毁。