简易脑图:
JDBC简介
Java DataBase Connectivity
是Java程序访问数据库的标准接口。
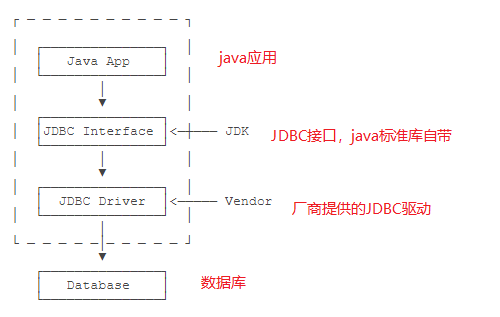
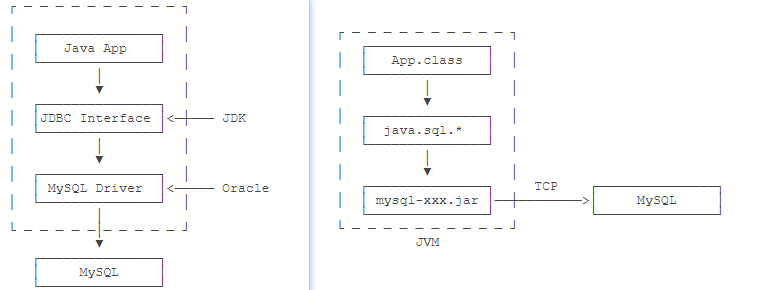
实际上,一个MySQL的JDBC的驱动就是一个jar包,它本身也是纯Java编写的。
我们自己编写的代码只需要引用Java标准库提供的java.sql包下面的相关接口,
由此再间接地通过MySQL驱动的jar包通过网络访问MySQL服务器,所有复杂的网络通讯都被封装到JDBC驱动中,
因此,Java程序本身只需要引入一个MySQL驱动的jar包就可以正常访问MySQL服务器:
使用JDBC的好处是:
- 各数据库厂商使用相同的接口,Java代码不需要针对不同数据库分别开发;
- Java程序编译期仅依赖java.sql包,不依赖具体数据库的jar包;
- 可随时替换底层数据库,访问数据库的Java代码基本不变。
1. JDBC查询-ps.executeQuery()
使用
PreparedStatement进行各种SELECT,然后处理结果集
1.1 添加Maven依赖
选择了MySQL作为数据库,所以我们首先得找一个MySQL的JDBC驱动。
所谓JDBC驱动,其实就是一个第三方jar包,我们直接添加一个Maven依赖就可以了:(根据自己的mysql版本)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
<scope>runtime</scope>
</dependency>
注意到这里添加依赖的scope是runtime,因为编译Java程序并不需要MySQL的这个jar包,只有在运行期才需要使用。
如果把runtime改成compile,虽然也能正常编译,但是在IDE里写程序的时候,会多出来一大堆类似com.mysql.jdbc.Connection这样的类,非常容易与Java标准库的JDBC接口混淆,所以坚决不要设置为compile。
1.2 创建数据库和表
有了驱动,我们还要确保MySQL在本机正常运行,并且还需要准备一点数据。这里我们用一个脚本创建数据库和表,然后插入一些数据:
-- 创建数据库learjdbc:
DROP DATABASE IF EXISTS learnjdbc;
CREATE DATABASE learnjdbc;
-- 创建登录用户learn/口令learnpassword
CREATE USER IF NOT EXISTS learn@'%' IDENTIFIED BY 'learnpassword';
GRANT ALL PRIVILEGES ON learnjdbc.* TO learn@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
-- 创建表students:
USE learnjdbc;
CREATE TABLE students (
id BIGINT AUTO_INCREMENT NOT NULL,
name VARCHAR(50) NOT NULL,
gender TINYINT(1) NOT NULL,
grade INT NOT NULL,
score INT NOT NULL,
PRIMARY KEY(id)
) Engine=INNODB DEFAULT CHARSET=UTF8;
-- 插入初始数据:
INSERT INTO students (name, gender, grade, score) VALUES ('小明', 1, 1, 88);
INSERT INTO students (name, gender, grade, score) VALUES ('小红', 1, 1, 95);
INSERT INTO students (name, gender, grade, score) VALUES ('小军', 0, 1, 93);
INSERT INTO students (name, gender, grade, score) VALUES ('小白', 0, 1, 100);
INSERT INTO students (name, gender, grade, score) VALUES ('小牛', 1, 2, 96);
INSERT INTO students (name, gender, grade, score) VALUES ('小兵', 1, 2, 99);
INSERT INTO students (name, gender, grade, score) VALUES ('小强', 0, 2, 86);
INSERT INTO students (name, gender, grade, score) VALUES ('小乔', 0, 2, 79);
INSERT INTO students (name, gender, grade, score) VALUES ('小青', 1, 3, 85);
INSERT INTO students (name, gender, grade, score) VALUES ('小王', 1, 3, 90);
INSERT INTO students (name, gender, grade, score) VALUES ('小林', 0, 3, 91);
INSERT INTO students (name, gender, grade, score) VALUES ('小贝', 0, 3, 77);
1.3 JDBC连接
使用JDBC时,我们先了解什么是Connection。
Connection代表一个JDBC连接,它相当于Java程序到数据库的连接(通常是TCP连接)。
打开一个Connection时,需要准备URL、用户名和口令,才能成功连接到数据库。
URL是由数据库厂商指定的格式,例如,MySQL的URL是:
jdbc:mysql://<hostname>:<port>/<db>?key1=value1&key2=value2
假设数据库运行在本机localhost,端口使用标准的3306,数据库名称是learnjdbc,那么URL如下:
jdbc:mysql://localhost:3306/learnjdbc?useSSL=false&characterEncoding=utf8
后面的两个参数表示不使用SSL加密,使用UTF-8作为字符编码(注意MySQL的UTF-8是utf8)。
获取数据库连接
要获取数据库连接,使用如下代码:
// JDBC连接的URL, 不同数据库有不同的格式:
String JDBC_URL = "jdbc:mysql://localhost:3306/test";
String JDBC_USER = "root";
String JDBC_PASSWORD = "password";
// 获取连接:
Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD);
// TODO: 访问数据库...
// 关闭连接:
conn.close();
核心代码是DriverManager提供的静态方法getConnection()。
DriverManager会自动扫描classpath,找到所有的JDBC驱动,然后根据我们传入的URL自动挑选一个合适的驱动。
因为JDBC连接是一种昂贵的资源,所以使用后要及时释放。
使用try (resource)来自动释放JDBC连接是一个好方法:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
...
}
关于try的写法:[深入理解 Java try-with-resource ]([http://www.kissyu.org/2016/10/06/深入理解Java try-with-resource/](http://www.kissyu.org/2016/10/06/深入理解Java try-with-resource/)) 或者 掘金
JDBC查询
获取到JDBC连接后,下一步我们就可以查询数据库了。查询数据库分以下几步:
- 通过
Connection提供的createStatement()方法创建一个Statement对象,用于执行一个查询; - 执行
Statement对象提供的executeQuery("SELECT * FROM students")并传入SQL语句,执行查询并获得返回的结果集,使用ResultSet来引用这个结果集; - 反复调用
ResultSet的next()方法并读取每一行结果。
完整查询代码如下:(有SQL注入的隐患)
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (Statement stmt = conn.createStatement()) {
try (ResultSet rs = stmt.executeQuery("SELECT id, grade, name, gender FROM students WHERE gender=1")) {
while (rs.next()) {
long id = rs.getLong(1); // 注意:索引从1开始
long grade = rs.getLong(2);
String name = rs.getString(3);
int gender = rs.getInt(4);
}
}
}
}
注意要点:
-
Statment和ResultSet都是需要关闭的资源,因此嵌套使用try (resource)确保及时关闭; -
rs.next()用于判断是否有下一行记录,如果有,将自动把当前行移动到下一行(一开始获得ResultSet时当前行不是第一行); -
ResultSet获取列时,索引从1开始而不是0; -
必须根据
SELECT的列的对应位置来调用getLong(1),getString(2)这些方法,否则对应位置的数据类型不对,将报错。
SQL注入
由于执行的sql语句通常是 通过拼接字符串得到的,如
stmt.executeQuery("SELECT * FROM user WHERE login='" + name + "' AND pass='" + pass + "'");
其中的name和pass是通过网页输入后得到
在执行statement的 executQuery() 方法的时候,可能被传入精心构造的 字符串,造成SQL注入攻击
解决办法:
使用PreparedStatement
使用PreparedStatement可以完全避免SQL注入的问题,
因为PreparedStatement始终使用?作为占位符,并且把数据连同SQL本身传给数据库,这样可以保证每次传给数据库的SQL语句是相同的,只是占位符的数据不同,还能高效利用数据库本身对查询的缓存。
上述登录SQL如果用PreparedStatement可以改写如下:
User login(String name, String pass) {
...
String sql = "SELECT * FROM user WHERE login=? AND pass=?";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setObject(1, name);
ps.setObject(2, pass);
...
}
所以,PreparedStatement比Statement更安全,而且更快。
使用Java对数据库进行操作时,必须使用PreparedStatement,严禁任何通过参数拼字符串的代码!
改写上述查询:
我们把上面使用Statement的代码改为使用PreparedStatement:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement("SELECT id, grade, name, gender FROM students WHERE gender=? AND grade=?")) {
ps.setObject(1, "M"); // 注意:索引从1开始
ps.setObject(2, 3);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
long id = rs.getLong("id");
long grade = rs.getLong("grade");
String name = rs.getString("name");
String gender = rs.getString("gender");
}
}
}
}
使用PreparedStatement和Statement稍有不同,
必须首先调用setObject()设置每个占位符?的值,最后获取的仍然是ResultSet对象。
另外注意到从结果集读取列时,使用String类型的列名比索引要易读,而且不易出错。
关于聚合查询结果的读取:
注意到JDBC查询的返回值总是ResultSet,即使我们写这样的聚合查询SELECT SUM(score) FROM ...,也需要按结果集读取:
ResultSet rs = ...
if (rs.next()) {
double sum = rs.getDouble(1);
}
数据类型的对应
使用JDBC的时候,我们需要在Java数据类型和SQL数据类型之间进行转换。JDBC在java.sql.Types定义了一组常量来表示如何映射SQL数据类型,但是平时我们使用的类型通常也就以下几种:
| SQL数据类型 | Java数据类型 |
|---|---|
| BIT, BOOL | boolean |
| INTEGER | int |
| BIGINT | long |
| REAL | float |
| FLOAT, DOUBLE | double |
| CHAR, VARCHAR | String |
| DECIMAL | BigDecimal |
| DATE | java.sql.Date, LocalDate |
| TIME | java.sql.Time, LocalTime |
注意:只有最新的JDBC驱动才支持LocalDate和LocalTime。
2. JDBC更新-ps.executeUpdate()
使用JDBC执行
INSERT、UPDATE和DELETE都可视为更新操作;更新操作使用
PreparedStatement的executeUpdate()进行,返回受影响的行数。
2.1 插入:INSERT
插入操作是INSERT,即插入一条新记录。
通过JDBC进行插入,本质上也是用PreparedStatement执行一条SQL语句,不过最后执行的不是executeQuery(),而是executeUpdate()。示例代码如下:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement(
"INSERT INTO students (id, grade, name, gender) VALUES (?,?,?,?)")) {
ps.setObject(1, 999); // 注意:索引从1开始
ps.setObject(2, 1); // grade
ps.setObject(3, "Bob"); // name
ps.setObject(4, "M"); // gender
int n = ps.executeUpdate(); // 1
}
}
设置参数与查询是一样的,有几个?占位符就必须设置对应的参数。虽然Statement也可以执行插入操作,但我们仍然要严格遵循绝不能手动拼SQL字符串的原则,以避免安全漏洞。
当成功执行executeUpdate()后,返回值是int,表示插入的记录数量。此处总是1,因为只插入了一条记录。
2.2 插入并获取主键
如果数据库的表设置了自增主键,那么在执行INSERT语句时,并不需要指定主键,数据库会自动分配主键。对于使用自增主键的程序,有个额外的步骤,就是如何获取插入后的自增主键的值。
要获取自增主键,不能先插入,再查询。因为两条SQL执行期间可能有别的程序也插入了同一个表。获取自增主键的正确写法是在创建PreparedStatement的时候,指定一个RETURN_GENERATED_KEYS标志位,表示JDBC驱动必须返回插入的自增主键。示例代码如下:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement(
"INSERT INTO students (grade, name, gender) VALUES (?,?,?)",
Statement.RETURN_GENERATED_KEYS)) {
ps.setObject(1, 1); // grade
ps.setObject(2, "Bob"); // name
ps.setObject(3, "M"); // gender
int n = ps.executeUpdate(); // 1
try (ResultSet rs = ps.getGeneratedKeys()) {
if (rs.next()) {
long id = rs.getLong(1); // 注意:索引从1开始
}
}
}
}
观察上述代码,有两点注意事项:
- 调用
prepareStatement()时,第二个参数必须传入常量Statement.RETURN_GENERATED_KEYS,否则JDBC驱动不会返回自增主键; - 执行
executeUpdate()方法后,必须调用getGeneratedKeys()获取一个ResultSet对象,这个对象包含了数据库自动生成的主键的值,读取该对象的每一行来获取自增主键的值。
如果一次插入多条记录,那么这个ResultSet对象就会有多行返回值。如果插入时有多列自增,那么ResultSet对象的每一行都会对应多个自增值(自增列不一定必须是主键)。
2.3 更新: UPDATE
更新操作是UPDATE语句,它可以一次更新若干列的记录。更新操作和插入操作在JDBC代码的层面上实际上没有区别,除了SQL语句不同:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement("UPDATE students SET name=? WHERE id=?")) {
ps.setObject(1, "Bob"); // 注意:索引从1开始
ps.setObject(2, 999);
int n = ps.executeUpdate(); // 返回更新的行数
}
}
executeUpdate()返回数据库实际更新的行数。返回结果可能是正数,也可能是0(表示没有任何记录更新)。
2.4 删除:DELETE
删除操作是DELETE语句,它可以一次删除若干列。和更新一样,除了SQL语句不同外,JDBC代码都是相同的:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement("DELETE FROM students WHERE id=?")) {
ps.setObject(1, 999); // 注意:索引从1开始
int n = ps.executeUpdate(); // 删除的行数
}
}
3. JDBC事务
数据库事务具有ACID特性:
- Atomicity:原子性
- Consistency:一致性
- Isolation:隔离性
- Durability:持久性
SQL标准定义了4种隔离级别,分别对应可能出现的数据不一致的情况:
| Isolation Level | 脏读(Dirty Read) | 不可重复读(Non Repeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| Read Uncommitted | Yes | Yes | Yes |
| Read Committed | - | Yes | Yes |
| Repeatable Read | - | - | Yes |
| Serializable | - | - | - |
详细的关于 事务 的知识,查看 SQL 对应内容
事务代码
要在JDBC中执行事务,本质上就是如何把多条SQL包裹在一个数据库事务中执行。我们来看JDBC的事务代码:
Connection conn = openConnection();
try {
// 关闭自动提交:
conn.setAutoCommit(false);
// 执行多条SQL语句:
insert(); update(); delete();
// 提交事务:
conn.commit();
} catch (SQLException e) {
// 回滚事务:
conn.rollback();
} finally {
conn.setAutoCommit(true);
conn.close();
}
其中,开启事务的关键代码是conn.setAutoCommit(false),表示关闭自动提交。
提交事务的代码在执行完指定的若干条SQL语句后,调用conn.commit()。
要注意事务不是总能成功,如果事务提交失败,会抛出SQL异常(也可能在执行SQL语句的时候就抛出了),此时我们必须捕获并调用conn.rollback()回滚事务。
最后,在finally中通过conn.setAutoCommit(true)把Connection对象的状态恢复到初始值。
实际上,默认情况下,我们获取到Connection连接后,总是处于“自动提交”模式,也就是每执行一条SQL都是作为事务自动执行的,这也是为什么前面几节我们的更新操作总能成功的原因:因为默认有这种“隐式事务”。只要关闭了Connection的autoCommit,那么就可以在一个事务中执行多条语句,事务以commit()方法结束。
设定事务隔离级别
如果要设定事务的隔离级别,可以使用如下代码:
// 设定隔离级别为READ COMMITTED:
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
如果没有调用上述方法,那么会使用数据库的默认隔离级别。MySQL的默认隔离级别是REPEATABLE READ。
例子:插入一个学生成绩记录
static void insertStudents(String name, boolean gender, int grade, int score) throws SQLException {
try (Connection conn = DriverManager.getConnection(jdbcUrl, jdbcUsername, jdbcPassword)) {
boolean isAutoCommit = conn.getAutoCommit();
conn.setAutoCommit(false); // 关闭自动提交事务
try (PreparedStatement ps = conn
.prepareStatement("INSERT INTO students (name, gender, grade, score) VALUES (?, ?, ?, ?)")) {
ps.setString(1, name);
ps.setBoolean(2, gender);
ps.setInt(3, grade);
ps.setInt(4, score);
int n = ps.executeUpdate();
System.out.println(n + " inserted.");
}
if (score > 100) {
conn.rollback();
System.out.println("rollback.");
} else {
conn.commit();
System.out.println("commit.");
}
conn.setAutoCommit(isAutoCommit); // 恢复AutoCommit设置
}
}
4 JDBC Batch
在JDBC代码中,我们可以利用SQL数据库的这一特性,把同一个SQL但参数不同的若干次操作合并为一个batch执行。我们以批量插入为例,示例代码如下:
try (PreparedStatement ps = conn.prepareStatement("INSERT INTO students (name, gender, grade, score) VALUES (?, ?, ?, ?)")) {
// 对同一个PreparedStatement反复设置参数并调用addBatch():
for (String name : names) {
ps.setString(1, name);
ps.setBoolean(2, gender);
ps.setInt(3, grade);
ps.setInt(4, score);
ps.addBatch(); // 添加到batch
}
// 执行batch:
int[] ns = ps.executeBatch();
for (int n : ns) {
System.out.println(n + " inserted."); // batch中每个SQL执行的结果数量
}
}
执行batch和执行一个SQL不同点在于,需要对同一个PreparedStatement反复设置参数并调用addBatch(),这样就相当于给一个SQL加上了多组参数,相当于变成了“多行”SQL。
第二个不同点是调用的不是executeUpdate(),而是executeBatch(),因为我们设置了多组参数,相应地,返回结果也是多个int值,因此返回类型是int[],循环int[]数组即可获取每组参数执行后影响的结果数量。
例子
批量插入学生记录
static void batchInsertStudents(List<String> names, boolean gender, int grade, int score) throws SQLException {
try (Connection conn = DriverManager.getConnection(jdbcUrl, jdbcUsername, jdbcPassword)) {
boolean isAutoCommit = conn.getAutoCommit();
conn.setAutoCommit(false); // 关闭自动提交事务
try (PreparedStatement ps = conn
.prepareStatement("INSERT INTO students (name, gender, grade, score) VALUES (?, ?, ?, ?)")) {
for (String name : names) {
ps.setString(1, name);
ps.setBoolean(2, gender);
ps.setInt(3, grade);
ps.setInt(4, score);
ps.addBatch(); // 添加到batch
}
int[] ns = ps.executeBatch(); // 执行batch
for (int n : ns) {
System.out.println(n + " inserted."); // batch中每个SQL执行的结果数量
}
}
conn.commit();
conn.setAutoCommit(isAutoCommit); // 恢复AutoCommit设置
}
}
5. JDBC连接池
在执行JDBC的增删改查的操作时,如果每一次操作都来一次打开连接,操作,关闭连接,那么创建和销毁JDBC连接的开销就太大了。为了避免频繁地创建和销毁JDBC连接,我们可以通过连接池(Connection Pool)复用已经创建好的连接。
JDBC连接池有一个标准的接口javax.sql.DataSource,注意这个类位于Java标准库中,但仅仅是接口。要使用JDBC连接池,我们必须选择一个JDBC连接池的实现。
常用的JDBC连接池
- HikariCP
- C3P0
- BoneCP
- Druid
目前使用最广泛的是HikariCP。我们以HikariCP为例,要使用JDBC连接池,先添加HikariCP的依赖如下:
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>2.7.1</version>
</dependency>
创建连接池实例
紧接着,我们需要创建一个DataSource实例,这个实例就是
连接池:
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/test");
config.setUsername("root");
config.setPassword("password");
config.addDataSourceProperty("connectionTimeout", "1000"); // 连接超时:1秒
config.addDataSourceProperty("idleTimeout", "60000"); // 空闲超时:60秒
config.addDataSourceProperty("maximumPoolSize", "10"); // 最大连接数:10
DataSource ds = new HikariDataSource(config);
注意创建DataSource也是一个非常昂贵的操作,所以通常DataSource实例总是作为一个全局变量存储,并贯穿整个应用程序的生命周期。
使用连接池
有了连接池以后,我们如何使用它呢?和前面的代码类似,只是获取Connection时,把DriverManage.getConnection()改为ds.getConnection():
try (Connection conn = ds.getConnection()) { // 在此获取连接
...
} // 在此“关闭”连接
通过连接池获取连接时,并不需要指定JDBC的相关URL、用户名、口令等信息,因为这些信息已经存储在连接池内部了(创建HikariDataSource时传入的HikariConfig持有这些信息)。一开始,连接池内部并没有连接,所以,第一次调用ds.getConnection(),会迫使连接池内部先创建一个Connection,再返回给客户端使用。当我们调用conn.close()方法时(在try(resource){...}结束处),不是真正“关闭”连接,而是释放到连接池中,以便下次获取连接时能直接返回。
因此,连接池内部维护了若干个Connection实例,如果调用ds.getConnection(),就选择一个空闲连接,并标记它为“正在使用”然后返回,如果对Connection调用close(),那么就把连接再次标记为“空闲”从而等待下次调用。这样一来,我们就通过连接池维护了少量连接,但可以频繁地执行大量的SQL语句。
通常连接池提供了大量的参数可以配置,例如,维护的最小、最大活动连接数,指定一个连接在空闲一段时间后自动关闭等,需要根据应用程序的负载合理地配置这些参数。此外,大多数连接池都提供了详细的实时状态以便进行监控。