本文主要针对与我一样的小白想使用CUDA加速方法,而经过Visual Studio编译器对cuda代码反复试验与调整得到以下成果。
目前本文主要使用一维数组对CUDA的grid与block的组合尝试,已实现CUDA一维数组的计算,将其记录如下。
而我也将会在下篇继续使用多维数组使用CUDA计算。
本文可以帮助大家尽快上手CUDA实现简单代码编写,了解如何利用CUDA 线程实现每个元素处理(若为图片则是像素处理)。
本文结构:1.基本原理;2.一维数组代码;3.实现结果展示。
1.基本原理
原理引用博客为https://blog.csdn.net/tiao_god/article/details/107181883
CUDA会把线程分为Block和Grid:
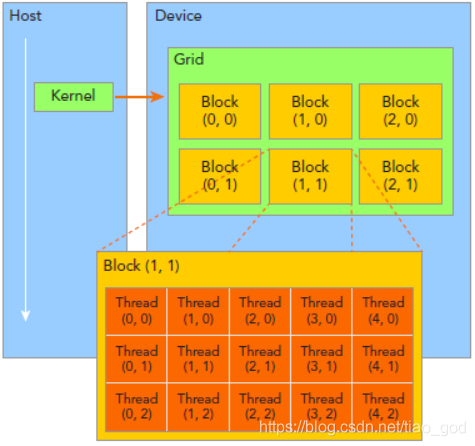
这里方便介绍我们用的都是二维的结构,其实Block和Grid也可以设置成三维的。
blockDim.x:Block的x方向的维度,这里是5,即每行5个线程。
blockDim.y:Block的y方向的维度,这里是3,即每列3个线程。
blockIdx.x:Block在x方向的位置,图中放大的Block是2,即为第2个。
blockIdx.y:Block在y向的位置,图中放大的Block是2,即为第2个。
注意blockIdx中的Idx是表示index的缩写,而不是表示x方向的ID。
在CUDA里计算线程索引一般都是:
const int X = blockIdx.x * blockDim.x + threadIdx.x;
const int Y = blockIdx.y * blockDim.y + threadIdx.y;
对应图中放大的区域的Thread(3,1):
计算式:X = 2*5+3 Y = 2*3+1
2.一维数组代码
// 一个维度的计算方法 __global__ void one_vector_add(float* a_device, float* b_device, float* c_device) { int tid = threadIdx.y+blockDim.x*threadIdx.x; c_device[tid] = a_device[tid] + b_device[tid]; } // 一维数组相加 void OneDim_add() { const int length = 4; // 数组长度为16 float a[length], b[length], c[length]; // host中的数组 // 变量初始化赋值 for (int i = 0; i < length; i++) { a[i] = i + 1; b[i] = a[i] * 10; } // 变量初始化打印 cout << "a=" << ' '; for (int i = 0; i < length; i++) { cout << a[i] << ' '; } cout << ' ' << "b=" << ' '; for (int i = 0; i < length; i++) { cout << b[i] << ' '; } //构造cuda指针变量并分配内存 float *a_device, *b_device, *c_device; // device中的数组 cudaSetDevice(0); // 设置cuda设备 cudaMalloc((void**)&a_device, length * sizeof(float)); cudaMalloc((void**)&b_device, length * sizeof(float)); cudaMalloc((void**)&c_device, length * sizeof(float)); // 将host数组的值拷贝给device数组 cudaMemcpy(a_device, a, length * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(b_device, b, length * sizeof(float), cudaMemcpyHostToDevice); cout << ' ' << "length:" << length << " 分配大小:" << length * sizeof(float) << endl; // 配置grid,block参数 dim3 grid(1, 1, 1), block(1,length , 1); // 设置grid block 参数 // 重点:调用kernel函数 one_vector_add <<<grid, block >>> (a_device, b_device, c_device); // 启动kernel // 将gpu上得到结果值返回host变量 cudaMemcpy(c, c_device, length * sizeof(float), cudaMemcpyDeviceToHost); // 将结果拷贝到host cout << ' ' << "c=" << ' '; for (int i = 0; i < length; i++) { cout << c[i] << ' '; } //打印cuda计算的值 } //block-thread 1D-3D __global__ void TwoBlock1Thread2Way1(float *c, const float *a, const float *b) { int i = threadIdx.x+threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y; //3d 也适用2D c[i] = b[i] + a[i]; } //block-thread 2D-3D __global__ void TwoBlock2Thread3Way1(float *c, const float *a, const float *b) { int thread2d = threadIdx.x + threadIdx.y*blockDim.x; int block2d = blockIdx.x+blockIdx.y*gridDim.x; // block是2D形式,但同样适用block为1D形式(blockIdx.x) int i = thread2d + (blockDim.x*blockDim.y)*block2d; c[i] = b[i] + a[i]; } void TwoDimway1_add() { //将二维矩阵化为一维数组,使用一维数组进行block分配 const int row = 4; const int col = 6; const int length = row*col; // 数组长度为16 float a[length], b[length], c[length]; // host中的数组 // 变量初始化赋值 for (int i = 0; i < length; i++) { a[i] = i + 1; b[i] = a[i] * 100; } // 变量初始化打印 cout << "变量a=" <<endl; for (int i = 0; i < row; i++) { for (int i = 0; i < col; i++) { cout<< ' ' << a[i] ; } cout << endl; } cout << "变量b=" << endl; for (int i = 0; i < row; i++) { for (int i = 0; i < col; i++) { cout << ' ' << b[i]; } cout << endl; } //构造cuda指针变量并分配内存 float *a_device, *b_device, *c_device; // device中的数组 cudaSetDevice(0); // 设置cuda设备 cudaMalloc((void**)&a_device, length * sizeof(float)); cudaMalloc((void**)&b_device, length * sizeof(float)); cudaMalloc((void**)&c_device, length * sizeof(float)); // 将host数组的值拷贝给device数组 cudaMemcpy(a_device, a, length * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(b_device, b, length * sizeof(float), cudaMemcpyHostToDevice); // 配置grid,block参数 //dim3 grid(1, 1, 1), block(row, col/2, col / 2); // 设置block为3D参数 //TwoBlock1Thread2Way1 <<<grid, block >>> (c_device,a_device, b_device ); // 重点:调用kernel函数 //dim3 grid(1, 1, 1), block(row, col , 1); // 设置block为2D参数 //TwoBlock1Thread2Way1 << <grid, block >> > (c_device, a_device, b_device);// 重点:调用kernel函数 dim3 grid(2, 1, 1), block(row/2, col, 1); // 设置block为2D参数 TwoBlock2Thread3Way1 << <grid, block >> > (c_device, a_device, b_device);// 重点:调用kernel函数 // 将gpu上得到结果值返回host变量 cudaMemcpy(c, c_device, length * sizeof(float), cudaMemcpyDeviceToHost); // 将结果拷贝到host cout << "计算结果 c=" << endl; for (int i = 0; i < row; i++) { for (int i = 0; i < col; i++) { cout << ' ' << c[i]; } cout << endl; } } int main() { cout << " 一维数组cuda计算结果: " << endl; OneDim_add(); //TwoDim_add(); cout << " 二维数组一维方式cuda计算结果: " << endl; TwoDimway1_add(); return 0; }
3.实现结果展示
采用加法运算,将其变量a与变量b位置元素一一对应相加结果:
