用到的训练数据集:sklearn数据集
可视化工具:tensorboard,这儿记录了loss值(预测值与真实值的差值),通过loss值可以判断训练的结果与真实数据是否吻合
过拟合:训练过程中为了追求完美而导致问题
过拟合的情况:蓝线为实际情况,在误差为10的区间,他能够表示每条数据。
橙线为训练情况,为了追求0误差,他将每条数据都关联起来,但是如果新增一些点(+),他就不能去表示新增的点了

训练得到的值和实际测试得到的值相比,训练得到的loss更小,但它与实际不合,并不是loss值越小就越好
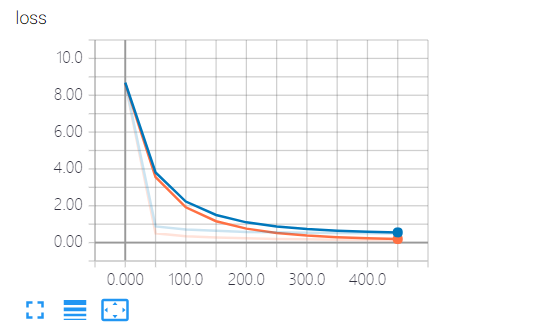

drop处理过拟合后:

代码:
import tensorflow as tf from sklearn.datasets import load_digits from sklearn.cross_validation import train_test_split from sklearn.preprocessing import LabelBinarizer # load data digits = load_digits() X = digits.data y = digits.target y = LabelBinarizer().fit_transform(y) # 转换格式 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) def add_layer(inputs, in_size, out_size, layer_name, active_function=None): """ :param inputs: :param in_size: 行 :param out_size: 列 , [行, 列] =矩阵 :param active_function: :return: """ with tf.name_scope('layer'): with tf.name_scope('weights'): W = tf.Variable(tf.random_normal([in_size, out_size]), name='W') # with tf.name_scope('bias'): b = tf.Variable(tf.zeros([1, out_size]) + 0.1) # b是一行数据,对应out_size列个数据 with tf.name_scope('Wx_plus_b'): Wx_plus_b = tf.matmul(inputs, W) + b Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob=keep_prob) if active_function is None: outputs = Wx_plus_b else: outputs = active_function(Wx_plus_b) tf.summary.histogram(layer_name + '/outputs', outputs) # 1.2.记录outputs值,数据直方图 return outputs # define placeholder for inputs to network keep_prob = tf.placeholder(tf.float32) # 不被dropout的数量 xs = tf.placeholder(tf.float32, [None, 64]) # 8*8 ys = tf.placeholder(tf.float32, [None, 10]) # add output layer l1 = add_layer(xs, 64, 50, 'l1', active_function=tf.nn.tanh) prediction = add_layer(l1, 50, 10, 'l2', active_function=tf.nn.softmax) # the loss between prediction and really cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1])) tf.summary.scalar('loss', cross_entropy) # 字符串类型的标量张量,包含一个Summaryprotobuf 1.1记录标量(展示到直方图中 1.2 ) # training train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.Session() merged = tf.summary.merge_all() # 2.把所有summary节点整合在一起,只需run一次,这儿只有cross_entropy sess.run(tf.initialize_all_variables()) train_writer = tf.summary.FileWriter('log/train', sess.graph) # 3.写入 test_writer = tf.summary.FileWriter('log/test', sess.graph) # cmd cd到log目录下,启动 tensorboard --logdir=log # start training for i in range(500): sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5}) # keep_prob训练时保留50%, 当这儿为1时,代表不drop任何数据,(没处理过拟合问题) if i % 50 == 0: # 4. record loss train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1}) # tensorboard记录保留100%的数据 test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1}) train_writer.add_summary(train_result, i) test_writer.add_summary(test_result, i) print("Record Finished !!!")