课程学习总结报告
一、课程心得体会
- 本次课程由两位老师分别授课
- 孟宁老师站在一个程序员的角度,高屋建瓴。从一个宏观的角度来讲述linux操作系统,使得我更好的把握linux的大体观。能更整体的学习linux
- 李春杰老师的讲述则更细节。注重linux操作系统更内核的实现方式。使得我对linux的使用更加熟悉。
- 两位老师结合授课的方式,既新颖又有效。
二、课程内容总结
以下为自己整理的复习笔记,为避免文章冗余,主要以目录形式展示


- 补充部分重要知识点
用户态切换到内核态的3种方式:
系统调用
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如前例中fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断。
异常
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
三、精简的Linux系统概念模型
从大体来看,linux系统模型可分为用户层、函数库层、系统调用层、内核层、硬件接口层
3.1 linux操作系统的两个分界线
- 对底层来说,与硬件交互,管理所有的硬件资源。
- 对上层来说,通过系统调用 为系统程序和应用程序提供一个良好的执行环境。
依据上述两个目的给出我认为的linux系统模型如下
3.2 linux系统概念模型
- 总结的精简的linux系统概念模型如下:
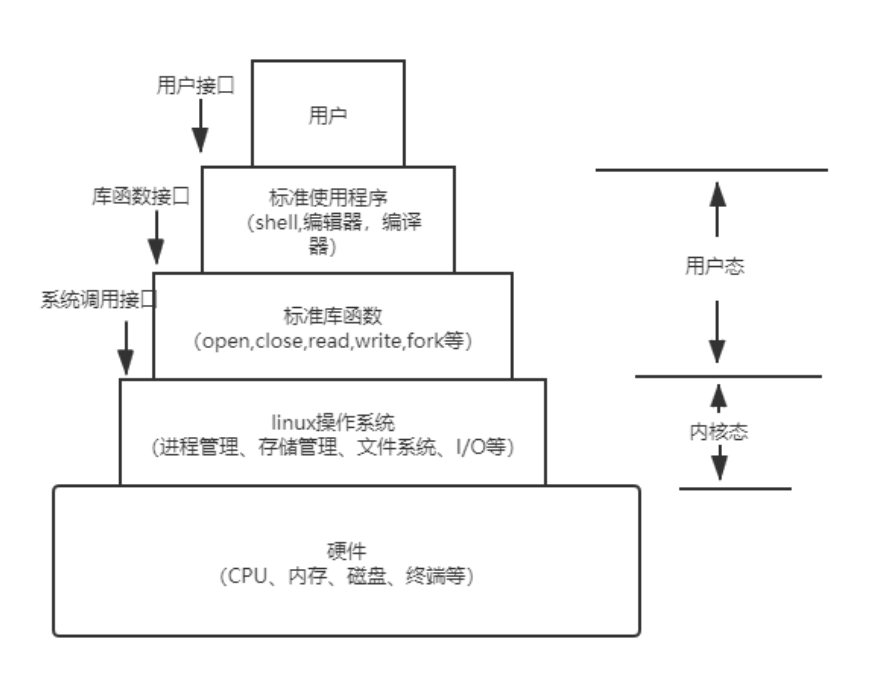
该模型逻辑上是可以运转的、自洽。
用户通过用户接口调用库函数。部分库函数需要通过库函数接口调用系统调用,从而从用户态陷入内核态。再通过具体的系统调用完成需要的具体功能。
在用户空间下执行,我们把此时运行得程序的这种状态成为用户态,而当这段程序执行在内核的空间执行时,这种状态称为内核态。
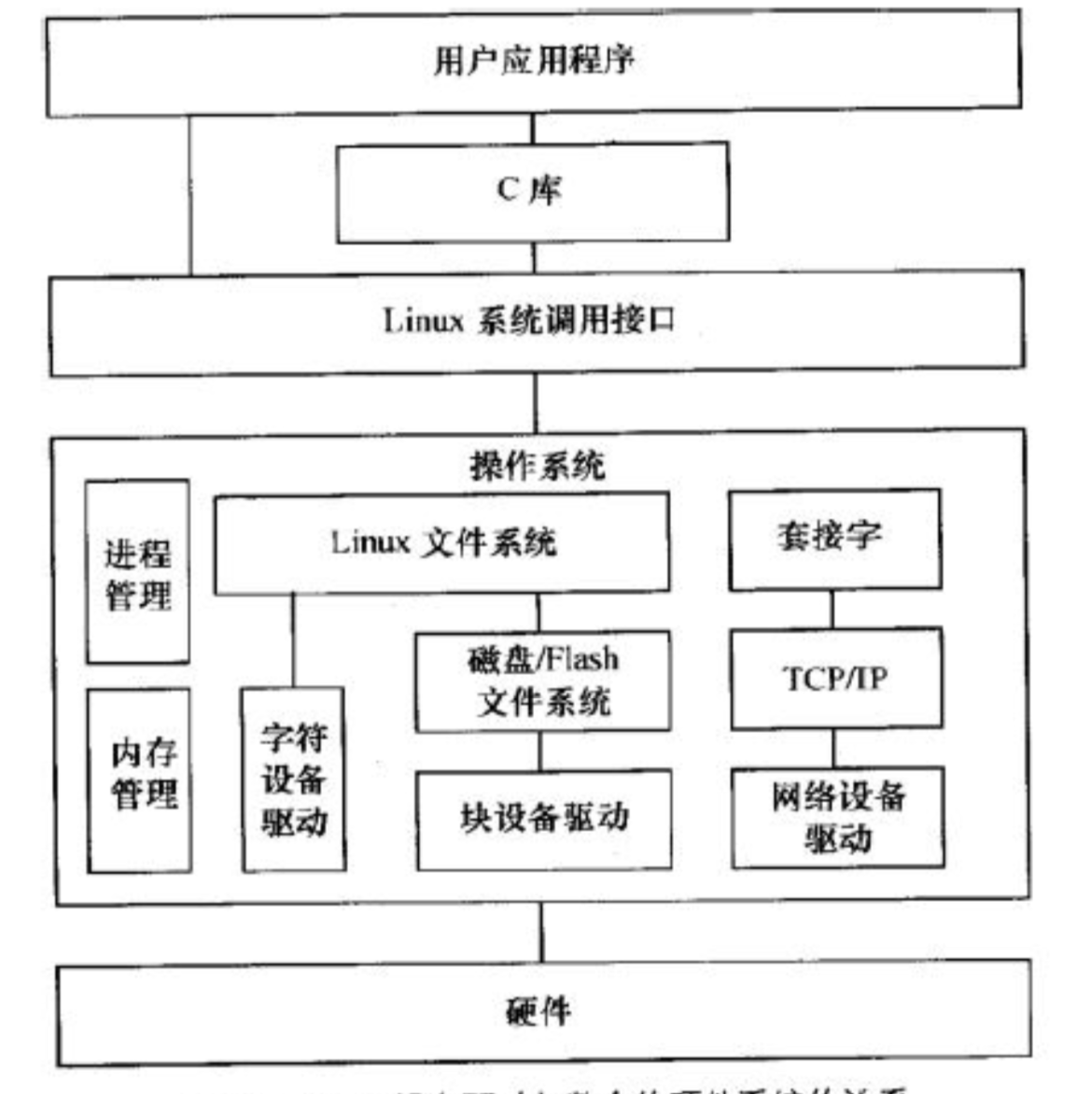
- linux设备与驱动系统概念模型
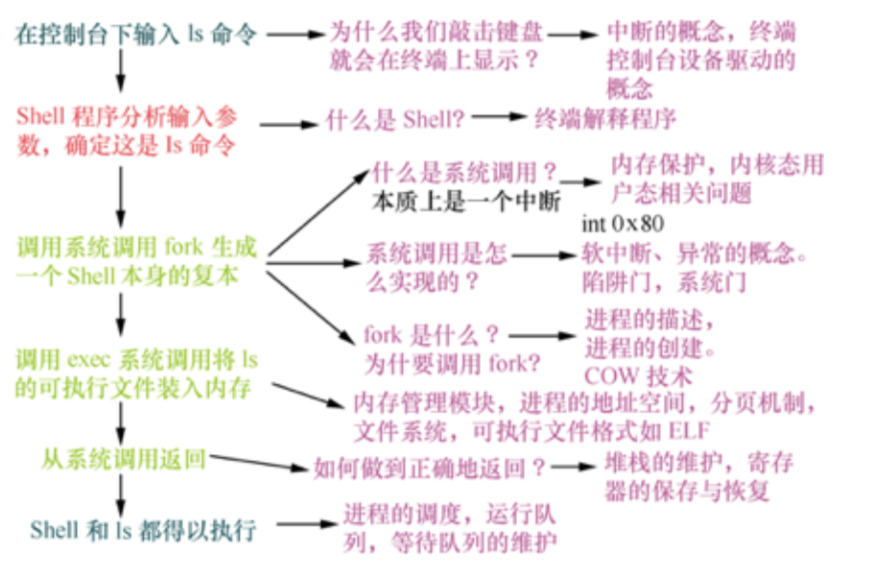
3.3 以ls为例验证模型
此例为孟老师课件中留下的问题,所以具体描述借鉴孟老师的PPT来辅助描述
- ls命令执行过程概览
-
当我们在控制台输入ls命令时,触发了中断。由中断处理程序响应。并在终端上显示。
-
中断处理后会唤醒阻塞中的终端解释程序shell。将shell 置于就绪态。
-
shell程序执行首先会执行系统调用fork生成一个shell本身的副本。系统调用的本质上是一个中断,会保存上下文。
-
在fork出来的子进程中调用exec系统调用,将ls的系统调用号传给调用程序。通过查询系统调用表,找到ls对应的可执行文件,并将该文件装入内存通过exec执行。
-
ls执行完后,会将放回值保存在eax寄存器中。通过将前期压栈保存的ebp、ip、esp及相关上下文恢复。能正确的返回。
-
在shell及ls的执行涉及进程的调度策略和调度算法,就绪队列的维护。在正确的调度后将返回值输出到外设设备。
-
模型结合:
- 用户输入ls命令。该命令是shell终端的一个命令即shell的一个方法可理解为调用shell的一个库函数。
- 该库函数的执行涉及到了系统调用的fork以及exec,交由系统来负责处理
- 系统在处理时需要用到文件系统的加载,将可执行文件加载至内存。同时涉及到进程调度。
- 在执行中使用到了外设硬件:键盘的输入和显示器的输出
通过文件读写来学习linux系统的运行过程
- 读文件流程
- 1.进程调用库函数向内核发起读文件请求;
- 2.内核通过检查进程的文件描述符定位到虚拟文件系统的已打开文件列表表项;
- 3.调用该文件可用的系统调用函数read();
- 4.read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode;
- 5.在inode中,通过文件内容偏移量计算出要读取的页;
- 6.通过inode找到文件对应的address_space;
- 在address_space中访问该文件的页缓存树,查找对应的页缓存结点:
- (1)如果页缓存命中,那么直接返回文件内容;
- (2)如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第6步查找页缓存;
- 写文件流程
- 1.进程调用库函数向内核发起写文件请求;
- 2.内核通过检查进程的文件描述符定位到虚拟文件系统的已打开文件列表表项;
- 3.调用该文件可用的系统调用函数write();
- 4.read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode;
- 5.在inode中,通过文件内容偏移量计算出要写入的页;
- 6.通过inode找到文件对应的address_space
- 7.在address_space中查询对应页的页缓存是否存在:
- 8.如果页缓存命中,直接把文件内容修改更新在页缓存的页中。写文件就结束了。这时候文件修改位于页缓存,并没有写回到磁盘文件中去;
- 9.如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页。此时缓存页命中,进行第6步。
- 10.一个页缓存中的页如果被修改,那么会被标记成脏页。脏页需要写回到磁盘中的文件块。有两种方式可以把脏页写回磁盘:
- (1)手动调用sync()或者fsync()系统调用把脏页写回
- (2)pdflush进程会定时把脏页写回到磁盘
- 同时注意,脏页不能被置换出内存,如果脏页正在被写回,那么会被设置写回标记,这时候该页就被上锁,其他写请求被阻塞直到锁释放