01-Hive表的DDL操作--修改表
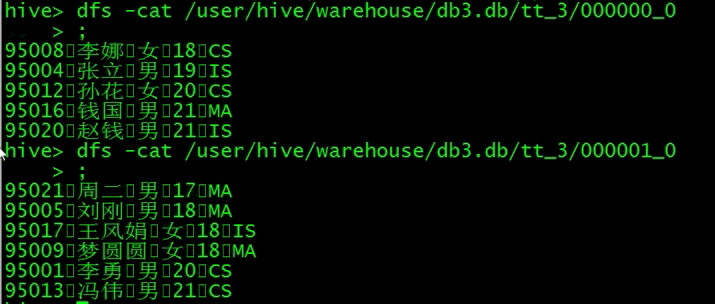
创建一个分区表并加载数据


查询数据

修改表

加载数据

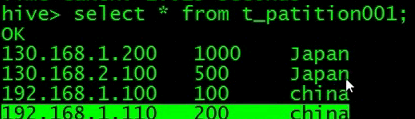
查询一下
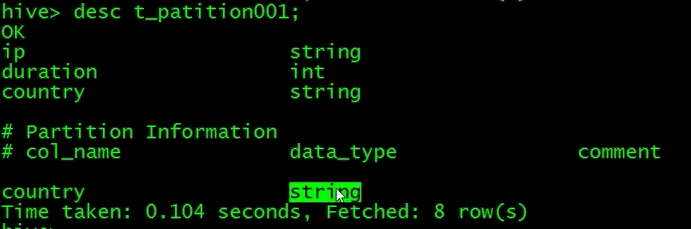
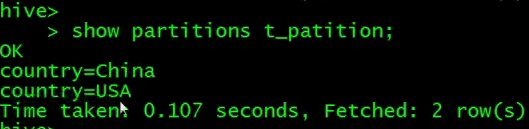
另外一个命令查询表的分区

如何删除一个分区呢

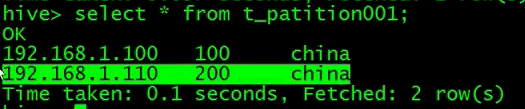
查询一个,分区被删除了
修改表名


查询改名的新表的数据
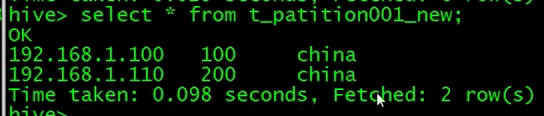
增加一列

查看表的结构,增加了一个字段
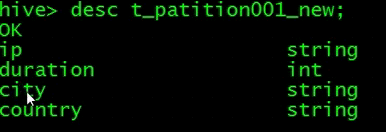
修改列

再来查看一下,除了分区列,其他所有列都被替换成了name
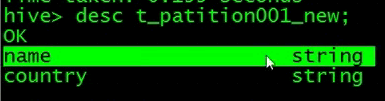
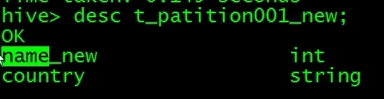
修改对应列

查看表结构,发现name字段改变了
02-Hive显示命令



查看分区
查看自带函数

查看详细表结构
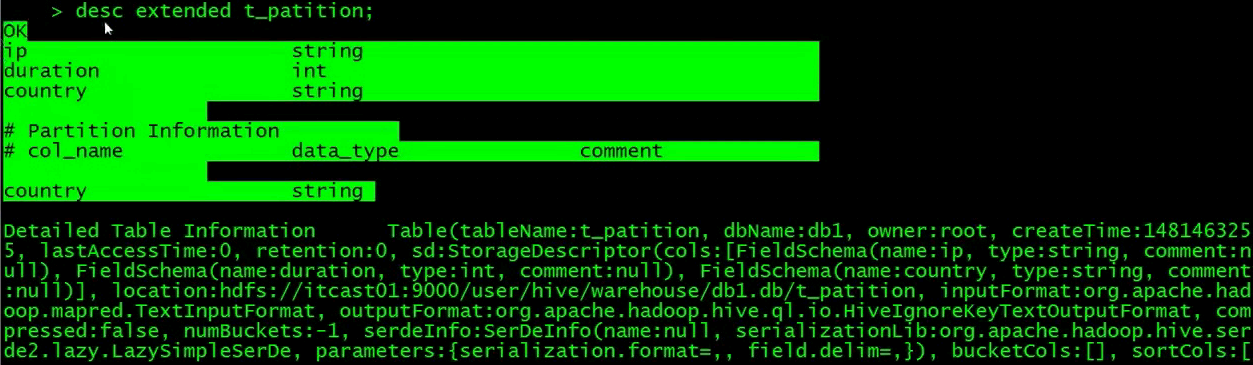
格式化查看表结构

可以在hive控制台输入linux命令
!clear 清屏
!ls
展现hdfs文件,与hdfs文件树进行交互


03-Hive的DML操作load
新建一个分区表

新建数据文件

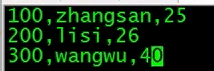
加载对应的数据,这里数据的路径可以是绝对路径,也可以是相对路径

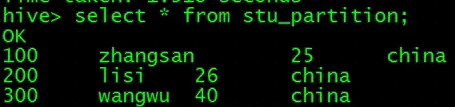
查看数据导入没有
再新建一个数据文件stu_partition1

上传到hdfs上面

查看hdfs上有没有这个文件

加载hdfs上的数据文件,不用加local了

再来查询下表数据,数据导入成功了
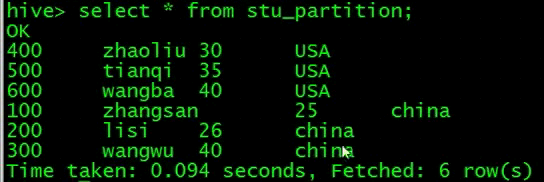
overwrite关键字,相当于覆盖

04-Hive的DDL操作insert
创建表,like关键字
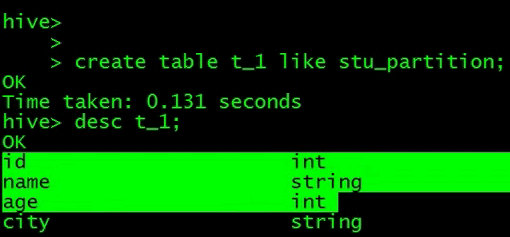
查出数据并导入对应表

查询数据
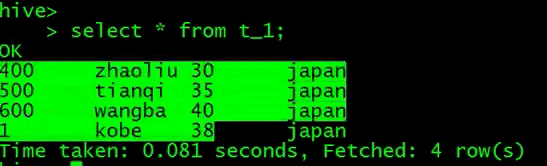
导入数据到本地目录,这里没有加local,所以导入到的是hdfs

查看hdfs上面对应的目录有没有数据

查询hdfs上导入的数据对不对

指明local,导入查询数据到本地

查看导入到本地的目录
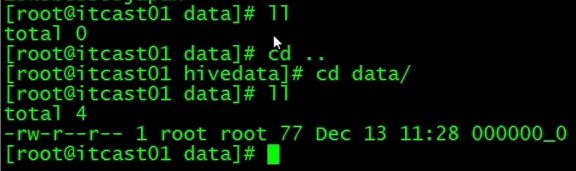
查看数据对不对
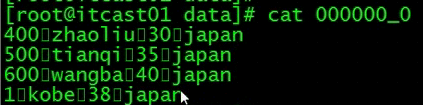
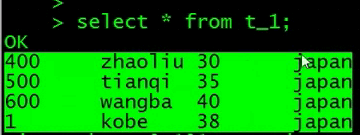
继续向这个表插入数据

此时报了一个错

需要执行这一句,自动分区模式

查询插入数据后的表数据
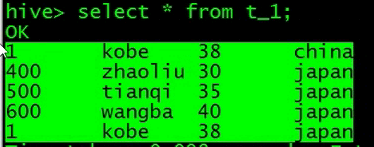
05-Hive的DDL操作-select语句

创建表,并制定数据目录,目录在hdfs根目录

查询hdfs上的数据

查询表数据


条件查询

分组查询

MapReduce结果

cluster by

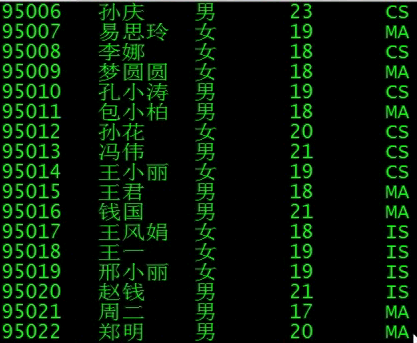
这跟select * 结果是一样的
设置task为4,才能看到结果

看一下最终的结果
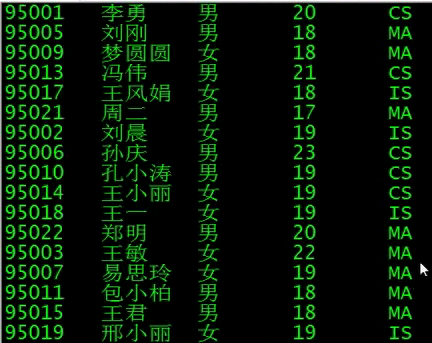
顺序不是依次递增的,说明多个task起作用了,通过no对4取模
distribute by

查看结果表结果,跟刚才的结果一模一样,因为cluster by = distribute by + sort by,后面by字段一样的时候
by的字段不一样结果就不同了
如果把上面那条命令后便替换成sort by age
查看hdfs上的表数据,发现是按照年龄排序的