What is machine learning?
并没有广泛认可的定义来准确定义机器学习。以下定义均为译文,若以后有时间,将补充原英文......
定义1、来自Arthur Samuel(上世纪50年代、西洋棋程序)
在进行特定编程的情况下给予计算机学习能力的领域。
定义2、来自Tom Mitchell(卡内基梅隆大学)
一个好的学习问题定义如下:一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,
当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。
机器学习分类
- 监督学习(Supervised Learning)
- 常见算法:逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)
- 无监督学习(Unsupervised Learning)
- 常见算法:Apriori算法以及k-Means算法。
- 强化学习(Reinforcement Learning)
- 常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
- 半监督学习(Semi-supervised Learning)
- 图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)
- 深度学习(Deep Learning)
监督学习(Supervised Learning)
在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。
监督学习的分类:
- 回归(Regression)
- 分类(Classification)
在回归问题中,我们会预测一个连续值。也就是说我们试图将输入变量和输出用一个连续函数对应起来;而在分类问题中,我们会预测一个离散值,我们试图将输入变量与离散的类别对应起来。
监督学习举例:
回归问题:
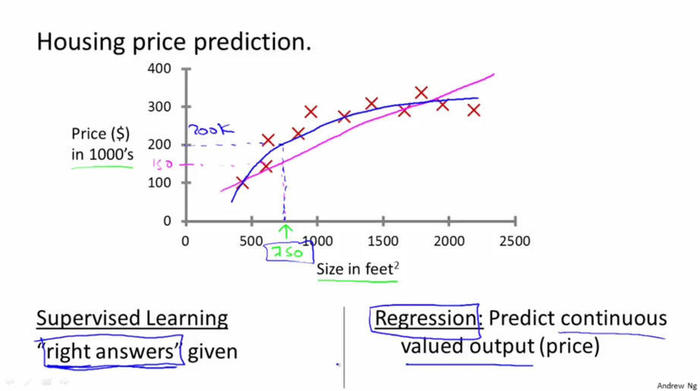
分类问题:
给定医学数据,通过肿瘤的大小来预测该肿瘤是恶性瘤还是良性瘤(课程中给的是乳腺癌的例子),这就是一个分类问题,它的输出是0或者1两个离散的值。(0代表良性,1代表恶性)。
分类问题的输出可以多于两个,比如在该例子中可以有{0,1,2,3}四种输出,分别对应{良性, 第一类肿瘤, 第二类肿瘤, 第三类肿瘤}。
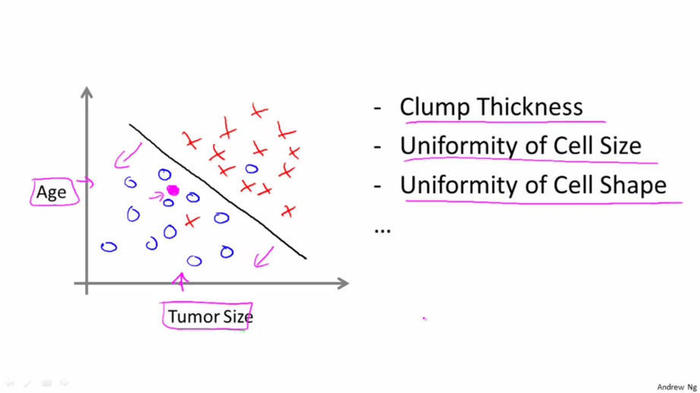
下图中上下两个图只是两种画法。第一个是有两个轴,Y轴表示是否是恶性瘤,X轴表示瘤的大小; 第二个是只用一个轴,但是用了不同的标记,用O表示良性瘤,X表示恶性瘤。

在这个例子中特征只有一个,那就是瘤的大小。 有时候也有两个或者多个特征, 例如下图, 有“年龄”和“肿瘤大小”两个特征。(还可以有其他许多特征,如下图右侧所示)
无监督学习(Unsupervised Learning)
在无监督学习中,我们基本上不知道结果会是什么样子,但我们可以通过聚类的方式从数据中提取一个特殊的结构。在无监督学习中给定的数据是和监督学习中给定的数据是不一样的。在无监督学习中给定的数据没有任何标签或者说只有同一种标签。如下图所示:
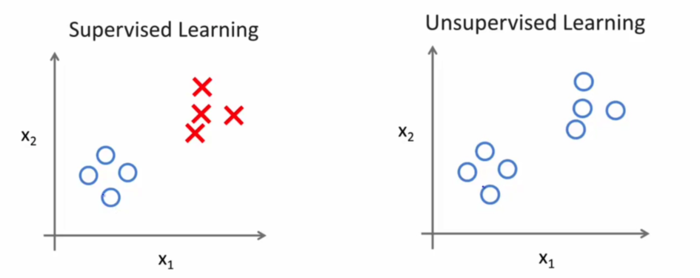
如下图所示,在无监督学习中,我们只是给定了一组数据,我们的目标是发现这组数据中的特殊结构。例如我们使用无监督学习算法会将这组数据分成两个不同的簇,,这样的算法就叫聚类算法。
无监督学习举例:
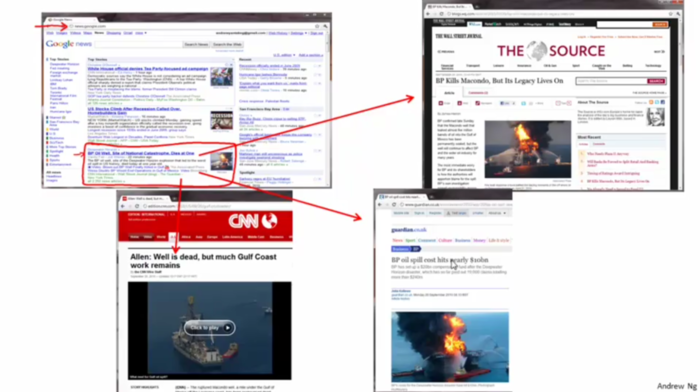
例1、新闻分类
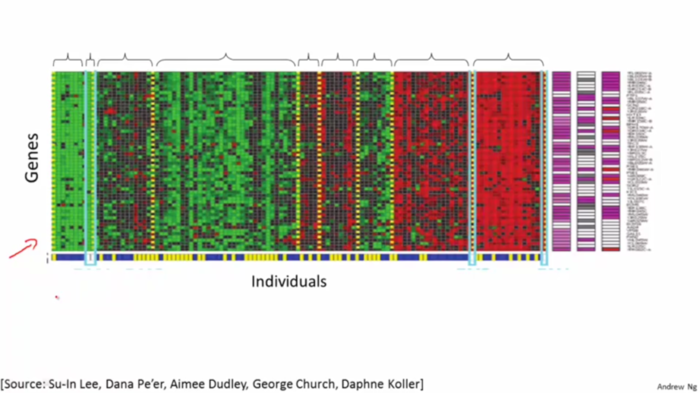
例2、根据给定基因将人群分类
如图是DNA数据,对于一组不同的人我们测量他们DNA中对于一个特定基因的表达程度。然后根据测量结果可以用聚类算法将他们分成不同的类型。这就是一种无监督学习, 因为我们只是给定了一些数据,而并不知道哪些是第一种类型的人,哪些是第二种类型的人等等。
半监督学习(Semi-supervised Learning):
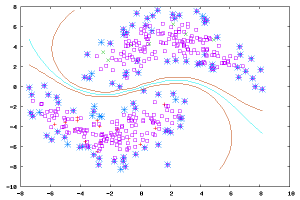
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
强化学习(Reinforcement Learning)
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
遗传算法(GENETIC ALGORITHIM):
和强化学期类似, 淘汰弱者、试着生存的原则,通过这种淘汰机制去选择最优的设计或模型
深度学习(Deep Learning):
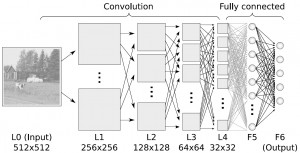
深度学习算法是对人工神经网络的发展。 在近期赢得了很多关注, 特别是百度也开始发力深度学习后, 更是在国内引起了很多关注。 在计算能力变得日益廉价的今天,深度学习试图建立大得多也复杂得多的神经网络。很多深度学习的算法是半监督式学习算法,用来处理存在少量未标识数据的大数据集。常见的深度学习算法包括:受限波尔兹曼机(Restricted Boltzmann Machine, RBN), Deep Belief Networks(DBN),卷积网络(Convolutional Network), 堆栈式自动编码器(Stacked Auto-encoders)。
总结:
有数据和标签的监督学习、只有数据没有标签的非监督学习、结合了监督学习和非监督学习的半监督学习(少量有标签、大量无标签)、从经验中总结提升的强化学习(机器人投篮)、有着适者生存不适者被淘汰准则的遗传算法、对人工神经网络的发展的深度学习。
在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。 在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。 而强化学习更多的应用在机器人控制及其他需要进行系统控制的领域。
参考课程地址:Supervised Learning & Unsupervised Learning
https://www.bilibili.com/video/av9912938/index_8.html#page=1