以下仅为了自己方便查看,绝大部分参考来源:莫烦Python,建议去看原博客
一、添加层 def add_layer()
定义 add_layer()函数
在 Tensorflow 里定义一个添加层的函数可以很容易的添加神经层,为之后的添加省下不少时间.
神经层里常见的参数通常有weights、biases和激励函数。
然后定义添加神经层的函数def add_layer(),它有四个参数:输入值、输入的大小、输出的大小和激励函数,我们设定默认的激励函数是None。
def add_layer(inputs, in_size, out_size, activation_function=None):
接下来,我们开始定义weights和biases。
因为在生成初始参数时,随机变量(normal distribution)会比全部为0要好很多,所以我们这里的weights为一个in_size行, out_size列的随机变量矩阵。在机器学习中,biases的推荐值不为0,所以我们这里是在0向量的基础上又加了0.1。
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)下面,我们定义Wx_plus_b, 即神经网络未激活的值。其中,tf.matmul()是矩阵的乘法。
Wx_plus_b = tf.matmul(inputs, Weights) + biases
当activation_function——激励函数为None时,输出就是当前的预测值——Wx_plus_b,不为None时,就把Wx_plus_b传到activation_function()函数中得到输出。
if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b)
最后,返回输出
return outputs
整体代码
def add_layer(inputs, in_size, out_size, activation_function=None): weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) Wx_plus_b = tf.matmul(inputs, weights) + biases if activation_function == None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs
二、建造神经网络
导入数据
构建所需的数据。 这里的x_data和y_data并不是严格的一元二次函数的关系,因为我们多加了一个noise,这样看起来会更像真实情况。
- np.linspace(-1,1,300, dtype=np.float32)
# 开始端-1,结束端1,且分割成300个数据,生成线段(在指定的间隔内返回均匀间隔的数字) - np.random.normal(loc=0, scale=1, size) 给出均值为loc,标准差为scale的高斯随机数(场).
- np.random.randn(size) 所谓标准正态分布(μ=0,σ=1μ=0,σ=1)
- np.square() 求平方
- np.arange(begin, end, step) 返回一个有终点和起点的固定步长的排列(一个参数时,参数值为终点,起点默认0,步长默认1)
- np.newaxis 作用就是在这一位置增加一个一维,这一位置指的是np.newaxis所在的位置(参考下面的链接)
参考链接:
np.newaxis numpy np.newaxis 的实用 关于np.newaxis的一点理解
x_data = np.linspace(-1,1,300, dtype=np.float32)[:, np.newaxis] # [:, np.newaxis]将(300,0)的数组,变成(300, 1) noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32) y_data = np.square(x_data) - 0.5 + noise
利用占位符定义我们所需的神经网络的输入。 tf.placeholder()就是代表占位符,这里的None代表无论输入有多少都可以,因为输入只有一个特征,所以这里是1。
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
接下来,我们就可以开始定义神经层了。 通常神经层都包括输入层、隐藏层和输出层。这里的输入层只有一个属性, 所以我们就只有一个输入;隐藏层我们可以自己假设,这里我们假设隐藏层有10个神经元; 输出层和输入层的结构是一样的,所以我们的输出层也是只有一层。 所以,我们构建的是——输入层1个、隐藏层10个、输出层1个的神经网络。
搭建网络
下面,我们开始定义隐藏层,利用之前的add_layer()函数,这里使用 Tensorflow 自带的激励函数tf.nn.relu。
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
接着,定义输出层。此时的输入就是隐藏层的输出——l1,输入有10层(隐藏层的输出层),输出有1层。
prediction = add_layer(l1, 10, 1, activation_function=None)
计算预测值prediction和真实值的误差,对二者差的平方求和再取平均。
-
reduction_indices=[1] 在tf.reduce_sum等函数中,有一个reduction_indices参数,表示函数的处理维度。 - 当为1时代表按行求和,当为0时代表按列求和;当没有reduction_indices这个参数,此时该参数取默认值None,将把input_tensor降到0维,也就是一个数
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
接下来,是很关键的一步,如何让机器学习提升它的准确率。tf.train.GradientDescentOptimizer()中的值通常都小于1,这里取的是0.1,代表以0.1的效率来最小化误差loss。
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
使用变量时,都要对它进行初始化,这是必不可少的。
# init = tf.initialize_all_variables() # tf 马上就要废弃这种写法 init = tf.global_variables_initializer() # 替换成这样就好
定义Session,并用 Session 来执行 init 初始化步骤。 (注意:在tensorflow中,只有session.run()才会执行我们定义的运算。)
sess = tf.Session()
sess.run(init)
训练
下面,让机器开始学习。
比如这里,我们让机器学习1000次。机器学习的内容是train_step, 用 Session 来 run 每一次 training 的数据,逐步提升神经网络的预测准确性。 (注意:当运算要用到placeholder时,就需要feed_dict这个字典来指定输入。)
for i in range(1000): # training sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
每50步我们输出一下机器学习的误差。
if i % 50 == 0: # to see the step improvement print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
全部代码
import numpy as np import tensorflow as tf def add_layer(inputs, in_size, out_size, activation_function=None): weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) Wx_plus_b = tf.matmul(inputs, weights) + biases if activation_function == None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs # 构建所需的数据。 这里的x_data和y_data并不是严格的一元二次函数的关系,因为我们多加了一个noise,这样看起来会更像真实情况。 x_data = np.linspace(-1,1,300,dtype=np.float32)[:,np.newaxis] #维度 noise = np.random.normal(0, 0.05,x_data.shape).astype(np.float32) y_data = np.square(x_data) - 0.5 + noise # 利用占位符定义我们所需的神经网络的输入。 tf.placeholder()就是代表占位符,这里的None代表无论输入有多少都可以,因为输入只有一个特征,所以这里是1 xs = tf.placeholder(tf.float32, [None, 1]) ys = tf.placeholder(tf.float32, [None, 1]) ''' 接下来,我们就可以开始定义神经层了。 通常神经层都包括输入层、隐藏层和输出层。这里的输入层只有一个属性, 所以我们就只有一个输入;隐藏层我们可以自己假设,这里我们假设隐藏层有10个神经元; 输出层和输入层的结构是一样的,所以我们的输出层也是只有一层。 所以,我们构建的是——输入层1个、隐藏层10个、输出层1个的神经网络。 ''' # 开始定义隐藏层,利用之前的add_layer()函数,这里使用 Tensorflow 自带的激励函数tf.nn.relu layer1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu) # 定义输出层。此时的输入就是隐藏层的输出——l1,输入有10层(隐藏层的输出层),输出有1层 prediction = add_layer(layer1, 10, 1, activation_function=None) # 计算预测值prediction和真实值的误差,对二者差的平方求和再取平均 loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) # 接下来,是很关键的一步,如何让机器学习提升它的准确率。tf.train.GradientDescentOptimizer()中的值通常都小于1,这里取的是0.1,代表以0.1的效率来最小化误差loss optimizer = tf.train.GradientDescentOptimizer(0.1) train_step = optimizer.minimize(loss) # 使用变量时,都要对它进行初始化,这是必不可少的 init = tf.global_variables_initializer() # 定义Session,并用 Session 来执行 init 初始化步骤。 (注意:在tensorflow中,只有session.run()才会执行我们定义的运算。) sess = tf.Session() sess.run(init) # 让机器学习1000次。机器学习的内容是train_step, 用 Session 来 run 每一次 training 的数据,逐步提升神经网络的预测准确性。 (注意:当运算要用到placeholder时,就需要feed_dict这个字典来指定输入。) for i in range(1000): sess.run(train_step, feed_dict={xs:x_data, ys:y_data}) # 每50步我们输出一下机器学习的误差。 if i % 50 ==0: print(sess.run(loss, feed_dict={xs:x_data, ys:y_data}))
三、结果可视化
matplotlib 可视化
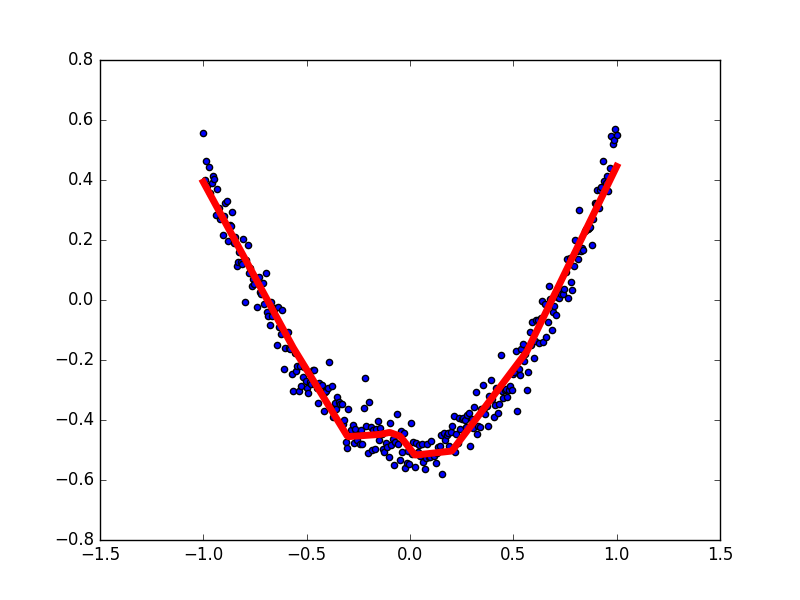
构建图形,用散点图描述真实数据之间的关系。 (注意:plt.ion()用于连续显示。)
-
plt.figure()定义一个图像窗口 -
plt.plot(x, y)plt.plot画(x,y)曲线 -
plt.show() 显示图像. -
fig.add_subplot(1,1,1) 将画布分割成1行1列,图像画在从左到右从上到下的第1块 fig.add_subplot(111) 参考链接:matplotlib.pyplot中add_subplot方法参数111的含义
-
ax.scatter() 绘制散点图 参考链接:Python中scatter函数参数详解
-
plt.ion() 使matplotlib的显示模式转换为交互(interactive)模式,可以展示动态图或多个窗口
import matplotlib.pylab as plt # plot the real data fig = plt.figure() #plt.figure() ax = fig.add_subplot(1,1,1) #将画布分割成1行1列,图像画在从左到右从上到下的第1块 fig.add_subplot(111) ax.scatter(x_data, y_data) # 绘制散点图 plt.ion() #使matplotlib的显示模式转换为交互(interactive)模式,可以展示动态图或多个窗口 plt.show() #显示图像.

接下来,我们来显示预测数据。
每隔50次训练刷新一次图形,用红色、宽度为5的线来显示我们的预测数据和输入之间的关系,并暂停0.1s。
- plt.plot(x,y,format_string,**kwargs) x轴数据,y轴数据,format_string控制曲线的格式字串
- format_string 由颜色字符,风格字符,和标记字符 参考链接
for i in range(1000): sess.run(train_step, feed_dict={xs:x_data, ys:y_data}) # 每50步我们输出一下机器学习的误差。 if i % 50 ==0: # print(sess.run(loss, feed_dict={xs:x_data, ys:y_data})) try: ax.lines.remove(lines[0]) #每一次循环都先将上一次生成的图像删除 except: pass prediction_value = sess.run(prediction, feed_dict={xs:x_data}) # plot the prediction' lines = ax.plot(x_data, prediction_value, 'r-', lw=5) # 'r-'代表红色实线 lw代表宽度 plt.pause(0.1) #暂停0.1s
完整代码:


import numpy as np import tensorflow as tf import matplotlib.pylab as plt def add_layer(inputs, in_size, out_size, activation_function=None): weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) Wx_plus_b = tf.matmul(inputs, weights) + biases if activation_function == None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs # 构建所需的数据。 这里的x_data和y_data并不是严格的一元二次函数的关系,因为我们多加了一个noise,这样看起来会更像真实情况。 x_data = np.linspace(-1,1,300,dtype=np.float32)[:,np.newaxis] #维度 noise = np.random.normal(0, 0.05,x_data.shape).astype(np.float32) y_data = np.square(x_data) - 0.5 + noise # 利用占位符定义我们所需的神经网络的输入。 tf.placeholder()就是代表占位符,这里的None代表无论输入有多少都可以,因为输入只有一个特征,所以这里是1 xs = tf.placeholder(tf.float32, [None, 1]) ys = tf.placeholder(tf.float32, [None, 1]) ''' 接下来,我们就可以开始定义神经层了。 通常神经层都包括输入层、隐藏层和输出层。这里的输入层只有一个属性, 所以我们就只有一个输入;隐藏层我们可以自己假设,这里我们假设隐藏层有10个神经元; 输出层和输入层的结构是一样的,所以我们的输出层也是只有一层。 所以,我们构建的是——输入层1个、隐藏层10个、输出层1个的神经网络。 ''' # 开始定义隐藏层,利用之前的add_layer()函数,这里使用 Tensorflow 自带的激励函数tf.nn.relu layer1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu) # 定义输出层。此时的输入就是隐藏层的输出——l1,输入有10层(隐藏层的输出层),输出有1层 prediction = add_layer(layer1, 10, 1, activation_function=None) # 计算预测值prediction和真实值的误差,对二者差的平方求和再取平均 loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) # 接下来,是很关键的一步,如何让机器学习提升它的准确率。tf.train.GradientDescentOptimizer()中的值通常都小于1,这里取的是0.1,代表以0.1的效率来最小化误差loss optimizer = tf.train.GradientDescentOptimizer(0.1) train_step = optimizer.minimize(loss) # 使用变量时,都要对它进行初始化,这是必不可少的 init = tf.global_variables_initializer() # 定义Session,并用 Session 来执行 init 初始化步骤。 (注意:在tensorflow中,只有session.run()才会执行我们定义的运算。) sess = tf.Session() sess.run(init) fig = plt.figure() #plt.figure() ax = fig.add_subplot(1,1,1) #将画布分割成1行1列,图像画在从左到右从上到下的第1块 fig.add_subplot(111) ax.scatter(x_data, y_data) # 绘制散点图 plt.ion() #使matplotlib的显示模式转换为交互(interactive)模式,可以展示动态图或多个窗口 plt.show() #显示图像. # 让机器学习1000次。机器学习的内容是train_step, 用 Session 来 run 每一次 training 的数据,逐步提升神经网络的预测准确性。 (注意:当运算要用到placeholder时,就需要feed_dict这个字典来指定输入。) for i in range(1000): sess.run(train_step, feed_dict={xs:x_data, ys:y_data}) # 每50步我们输出一下机器学习的误差。 if i % 50 ==0: # print(sess.run(loss, feed_dict={xs:x_data, ys:y_data})) try: ax.lines.remove(lines[0]) #每一次循环都先将上一次生成的图像删除 except: pass prediction_value = sess.run(prediction, feed_dict={xs:x_data}) # plot the prediction' lines = ax.plot(x_data, prediction_value, 'r-', lw=5) # 'r-'代表红色实线 lw代表宽度 plt.pause(0.1) #暂停0.1s
补充:
plt.ion()
python可视化库matplotlib的显示模式默认为阻塞(block)模式。什么是阻塞模式那?我的理解就是在plt.show()之后,程序会暂停到那儿,并不会继续执行下去。如果需要继续执行程序,就要关闭图片。那如何展示动态图或多个窗口呢?这就要使用plt.ion()这个函数,使matplotlib的显示模式转换为交互(interactive)模式。即使在脚本中遇到plt.show(),代码还是会继续执行。
python可视化库matplotlib有两种显示模式:
- 阻塞(block)模式
- 交互(interactive)模式
在Python Consol命令行中,默认是交互模式。而在python脚本中,matplotlib默认是阻塞模式。
在交互模式下:
plt.plot(x)或plt.imshow(x)是直接出图像,不需要plt.show()
如果在脚本中使用ion()命令开启了交互模式,没有使用ioff()关闭的话,则图像会一闪而过,并不会常留。要想防止这种情况,需要在plt.show()之前加上ioff()命令。
在阻塞模式下:
打开一个窗口以后必须关掉才能打开下一个新的窗口。这种情况下,默认是不能像Matlab一样同时开很多窗口进行对比的。
plt.plot(x)或plt.imshow(x)是直接出图像,需要plt.show()后才能显示图像
参考链接:https://blog.csdn.net/SZuoDao/article/details/52973621 https://blog.csdn.net/zbrwhut/article/details/80625702
四、加速神经网络训练 (Speed Up Training)
包括以下几种模式: 参考链接:莫烦python
- Stochastic Gradient Descent (SGD)
- Momentum
- AdaGrad
- RMSProp
- Adam
Stochastic Gradient Descent (SGD)

把这些数据拆分成小批小批的, 然后再分批不断放入 NN 中计算。
每次使用批数据, 虽然不能反映整体数据的情况, 不过却很大程度上加速了 NN 的训练过程, 而且也不会丢失太多准确率.
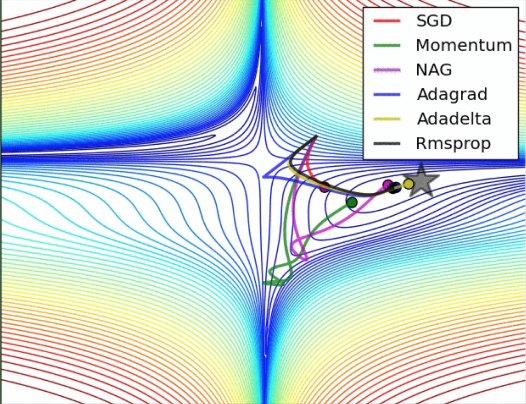
事实证明, SGD 并不是最快速的训练方法, 红色的线是 SGD, 但它到达学习目标的时间是在这些方法中最长的一种。
Momentum 更新方法
大多数其他途径是在更新神经网络参数那一步上动动手脚.
传统的参数 W 的更新是把原始的 W 累加上一个负的学习率(learning rate) 乘以校正值 (dx). 这种方法可能会让学习过程曲折无比, 看起来像 喝醉的人回家时, 摇摇晃晃走了很多弯路.
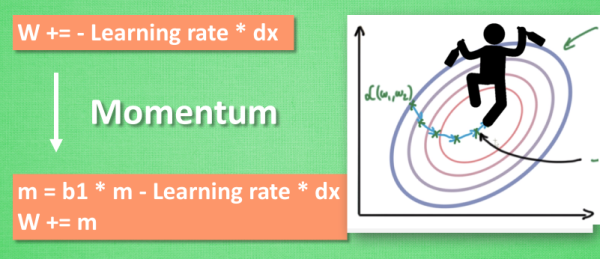
所以我们把这个人从平地上放到了一个斜坡上, 只要他往下坡的方向走一点点, 由于向下的惯性, 他不自觉地就一直往下走, 走的弯路也变少了. 这就是 Momentum 参数更新. 另外一种加速方法叫AdaGrad.
AdaGrad 更新方法
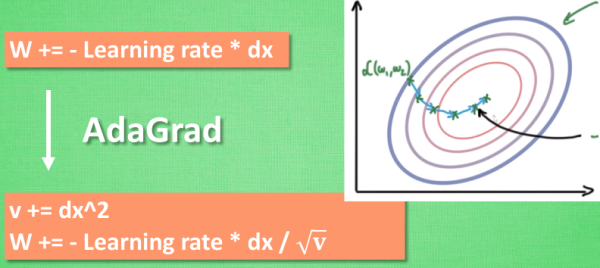
这种方法是在学习率上面动手脚, 使得每一个参数更新都会有自己与众不同的学习率, 他的作用和 momentum 类似, 不过不是给喝醉酒的人安排另一个下坡, 而是给他一双不好走路的鞋子, 使得他一摇晃着走路就脚疼, 鞋子成为了走弯路的阻力, 逼着他往前直着走. 他的数学形式是这样的.
RMSProp 更新方法
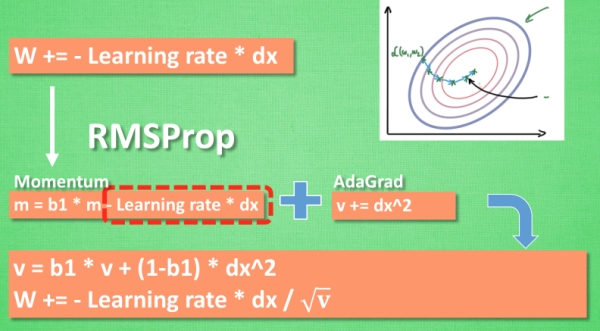
有了 momentum 的惯性原则 , 加上 adagrad 的对错误方向的阻力, 我们就能合并成这样. 让 RMSProp同时具备他们两种方法的优势. 不过似乎在 RMSProp 中少了些什么. 我们还没把 Momentum合并完全, RMSProp 还缺少了 momentum 中的 这一部分. 所以, 我们在 Adam 方法中补上了这种想法.
Adam 更新方法
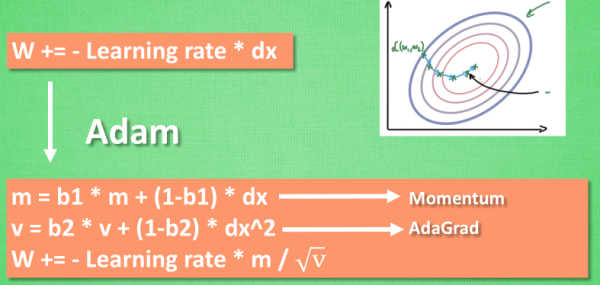
计算m 时有 momentum 下坡的属性, 计算 v 时有 adagrad 阻力的属性, 然后再更新参数时 把 m 和 V 都考虑进去.
五、优化器 optimizer
Tensorflow 中的优化器会有很多不同的种类。最基本, 也是最常用的一种就是GradientDescentOptimizer。
在Google搜索中输入“tensorflow optimizer”可以看到Tensorflow提供了7种优化器:链接

六、Tensorboard 可视化
(一)GRAPHS
搭建图纸
首先从 Input 开始:
with tf.name_scope()
# 分别为xs和ys指定一个名字,并把它们包含在一个大节点之中 # 使用with tf.name_scope('inputs')可以将xs和ys包含进来,形成一个大的图层,图层的名字就是with tf.name_scope()方法里的参数。 with tf.name_scope("inputs"): xs = tf.placeholder(tf.float32, [None, 1], name='x_in') ys = tf.placeholder(tf.float32, [None, 1], name='y_in')
编辑layer
def add_layer(inputs, in_size, out_size, activation_function=None): with tf.name_scope("layer"): with tf.name_scope("weights"): weights = tf.Variable(tf.random_normal([in_size, out_size]), name="W") with tf.name_scope("biases"): biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b') with tf.name_scope("Wx_plus_b"): Wx_plus_b = tf.add(tf.matmul(inputs, weights), biases) if activation_function == None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs
activation_function 的话,可以暂时忽略。因为当你自己选择用 tensorflow 中的激励函数(activation function)的时候,tensorflow会默认添加名称。
编辑loss部分:将with tf.name_scope()添加在loss上方,并为它起名为loss
with tf.name_scope("loss"): loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1]))
编辑train_step:
with tf.name_scope('train'): train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
使用 tf.summary.FileWriter() (tf.train.SummaryWriter() 这种方式已经在 tf >= 0.12 版本中摒弃) 将上面‘绘画’出的图保存到一个目录中,以方便后期在浏览器中可以浏览。 这个方法中的第二个参数需要使用sess.graph , 因此我们需要把这句话放在获取session的后面。 这里的graph是将前面定义的框架信息收集起来,然后放在logs/目录下面。
sess = tf.Session() writer = tf.summary.FileWriter("logs/", sess.graph)
命令:
tensorboard --logdir=logs # 或 tensorboard --logdir logs # logs可以用一个路径替换
若http://0.0.0.0:6006 网址打不开, 使用 http://localhost:6006,
报错: "tensorboard" is not recognized as an internal or external command...解决方法的关键就是需要激活TensorFlow. 管理员模式打开 Anaconda Prompt, 输入 activate tensorflow, 接着按照上面的流程执行 tensorboard 指令.
(二)HISTOGRAGMS 和 SCALARS
链接:https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/4-2-tensorboard2/
可视化训练过程
在 add_layer() 方法中添加一个参数 n_layer,用来标识层数, 并且用变量 layer_name代表其每层的名名称, 代码如下:
def add_layer( inputs , in_size, out_size, n_layer, activation_function=None): ## add one more layer and return the output of this layer layer_name='layer%s'%n_layer ## define a new var ## and so on ……
接下来,我们层中的Weights、biases、output设置变化图, tensorflow中提供了tf.histogram_summary()方法,用来绘制图片, 第一个参数是图表的名称, 第二个参数是图表要记录的变量
def add_layer(inputs , in_size, out_size,n_layer, activation_function=None): ## add one more layer and return the output of this layer layer_name='layer%s'%n_layer with tf.name_scope(layer_name): with tf.name_scope('weights'): Weights= tf.Variable(tf.random_normal([in_size, out_size]),name='W') # tf.histogram_summary(layer_name+'/weights',Weights) tf.summary.histogram(layer_name + '/weights', Weights) # tensorflow >= 0.12 with tf.name_scope('biases'): biases = tf.Variable(tf.zeros([1,out_size])+0.1, name='b') # tf.histogram_summary(layer_name+'/biase',biases) tf.summary.histogram(layer_name + '/biases', biases) # Tensorflow >= 0.12 with tf.name_scope('Wx_plus_b'): Wx_plus_b = tf.add(tf.matmul(inputs,Weights), biases) if activation_function is None: outputs=Wx_plus_b else: outputs= activation_function(Wx_plus_b) # tf.histogram_summary(layer_name+'/outputs',outputs) tf.summary.histogram(layer_name + '/outputs', outputs) # Tensorflow >= 0.12 return outputs
由于对addlayer 添加了一个参数, 所以修改之前调用addlayer()函数的地方. 对此处进行修改:
# add hidden layer l1= add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu) # add output layer prediction= add_layer(l1, 10, 1, n_layer=2, activation_function=None)
设置loss的变化图
Loss 的变化图和之前设置的方法略有不同. loss是在tesnorBorad 的event下面的, 这是由于我们使用的是tf.scalar_summary() 方法.
with tf.name_scope('loss'): loss= tf.reduce_mean(tf.reduce_sum( tf.square(ys- prediction), reduction_indices=[1])) # tf.scalar_summary('loss',loss) # tensorflow < 0.12 tf.summary.scalar('loss', loss) # tensorflow >= 0.12
所有训练图合并
tf.merge_all_summaries() 方法会对我们所有的 summaries 合并到一起. 因此在原有代码片段中添加:
sess= tf.Session() # merged= tf.merge_all_summaries() # tensorflow < 0.12 merged = tf.summary.merge_all() # tensorflow >= 0.12 # writer = tf.train.SummaryWriter('logs/', sess.graph) # tensorflow < 0.12 writer = tf.summary.FileWriter("logs/", sess.graph) # tensorflow >=0.12 # sess.run(tf.initialize_all_variables()) # tf.initialize_all_variables() # tf 马上就要废弃这种写法 sess.run(tf.global_variables_initializer()) # 替换成这样就好
训练数据
为了较为直观显示训练过程中每个参数的变化,每隔上50次就记录一次结果 , 同时我们也应注意, merged 也是需要run 才能发挥作用的,所以在for循环中写下:
for i in range(1000): sess.run(train_step, feed_dict={xs:x_data, ys:y_data}) if i%50 == 0: rs = sess.run(merged,feed_dict={xs:x_data,ys:y_data}) writer.add_summary(rs, i)