布隆过滤器
谭文涛 2021-12-24
假如你在程序员的面试中碰到如下问题,你该如何回答:
1、 比如中国现在接种第3针加强针新冠疫苗的人数已超过10亿,怎样快速判断出一位持有中国身份证的居民没有接种第3针疫苗?
2、 因为你和领导喜欢公司同一个妹子,你的领导想辞退你,但你平时的工作和考勤表现都无可挑剔。于是他给你一台内存是2G的笔记本电脑和A,B两个文件,每个文件各存放50亿条URL,每条URL占用64字节,让你找出A,B文件所有共同的URL,你咋办?
3、 之前被你领导排挤走的程序员非常气愤,于是写了个程序大批量频繁调用公司的http接口目的是攻击公司的数据库。虽然公司用了redis缓存,但由于他之前在公司干过,他的接口入参全都是缓存中不存在的,全都击穿了redis去访问数据库,领导眼看数据库每天都蹦,正好把锅甩给你,让你解决这个redis被击穿的问题,你咋处理?
其实上面三个问题的解答办法都是同一种,那就是“布隆过滤器”——BloomFilter
。下面我们来揭开他的神秘面纱
1、什么事布隆过滤器
布隆过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个很长的二进制向量和一系列随机映射函数组成,布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难,但是没有识别错误的情形(即如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
2、布隆过滤器的基本原理
如果想判断一个元素是不是在一个集合里,一般是将集合中所有元素保存起来,然后通过比较确定。链表、树、哈希表等数据结构都是这种思路。但是随着集合元素的增加需要的存储空间越大,检索速度也越慢。
应该蛮多人会说用 HashMap 吧,确实可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高。还比如说你的数据集存储在远程服务器上,本地服务接受输入,而数据集非常大不可能一次性读进内存构建 HashMap 的时候,也会存在问题。
接下来让我们看看“布隆过滤器”是怎么解决这个问题的:
布隆过滤器是一个 bit 向量或者说 bit 数组(超长超长,记住一定要足够长),长这样:

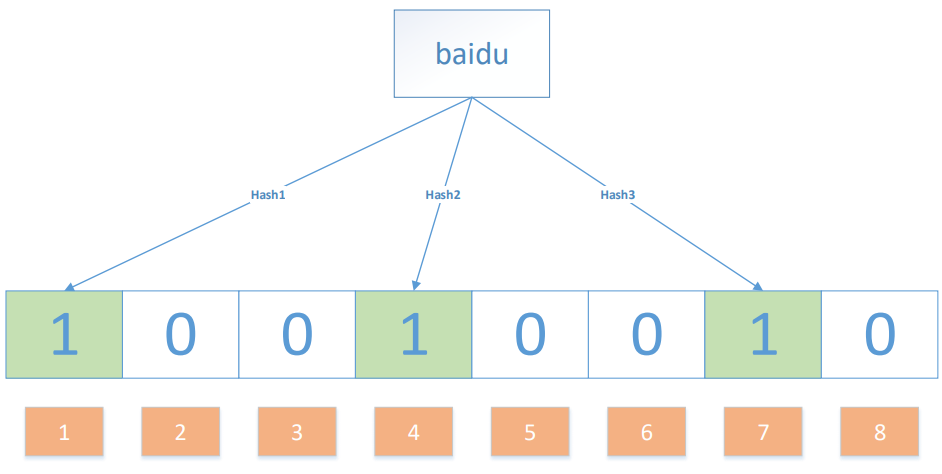
我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:

值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。
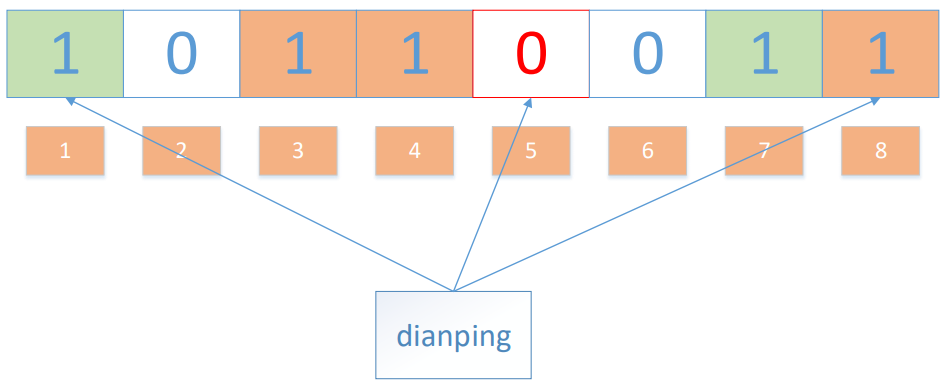
而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
为什么我上面说布隆过滤器的bit数组要足够长?
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
布隆过滤器的算法总结:
1.初始化时,需要一个长度为n比特的数组,每个比特位初始化为0;
2. 然后需要准备k个hash函数,每个函数可以把key散列成为1个整数;
3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把bit数组中对应的比特位置为1;
4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果有比特位是0,则该key一定不在集合中。
3、布隆过滤器的典型应用
布隆在海量数据查询中以优异的空间效率和低误判率有非常广泛的应用,其中包括但不限于:
(1)检查单词拼写正确性
(2)检测海量名单嫌疑人
(3)垃圾邮件过滤
(4)搜索爬虫URL去重
(5)缓存穿透过滤
世界上著名各大科技公司使用布隆过滤器的实际案例:
Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数。
Squid 网页代理缓存服务器在 cache digests 中使用了也布隆过滤器。
Venti 文档存储系统也采用布隆过滤器来检测先前存储的数据。
SPIN 模型检测器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间。
Google Chrome浏览器使用了布隆过滤器加速安全浏览服务。
4、结语
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。