1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
源代码:
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np import matplotlib.image as img import sys #读取一张图片,观察图片存放数据特点 china=load_sample_image('china.jpg') plt.imshow(china) plt.show() #根据图片的分辨率,可适当降低分辨率 image=china[::3,::3]#降低分辨率 x=image.reshape(-1,3)#生成行数未知,列数为3 print(china.shape,image.shape,x.shape) plt.imshow(image) plt.show() #再用k均值聚类算法,将图片中所有的颜色值做聚类。 n_colors=64 #(256,256,256) model=KMeans(n_colors) label=model.fit_predict(x)#每个点颜色分类,0-63 colors=model.cluster_centers_#二维(64,3) new_image=colors[label].reshape(image.shape)#然后用聚类中心的颜色代替原来的颜色值。 new_image=new_image.astype(np.uint8) plt.imshow(new_image)#形成新的图片 plt.show() #观察原始图片与新图片所占用内存的大小。 sys.getsizeof(china) sys.getsizeof(new_image) #将原始图片与新图片保存成文件,观察文件的大小。 img.imsave('C:/Users/Administrator/Desktop/大三下学期/机器学习/4.16/china.jpg',china) img.imsave('C:/Users/Administrator/Desktop/大三下学期/机器学习/4.16/new_china.jpg',new_image)
结果:
原始图片
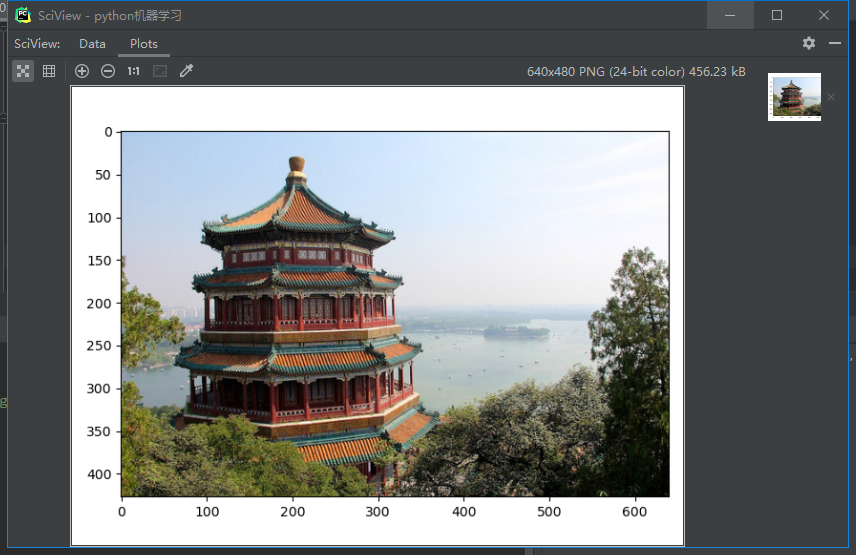
降低分辨率的图片
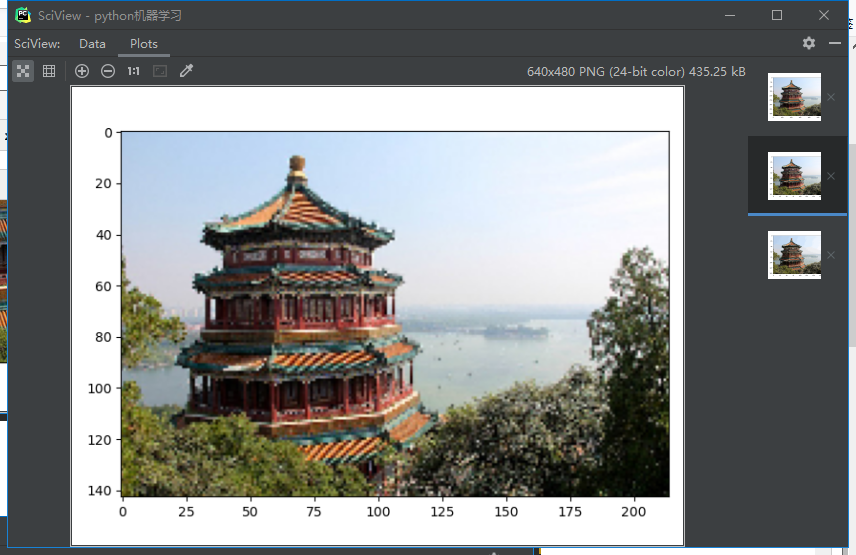
新图片
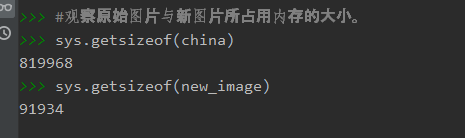
查看前后两个图片的大小

2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
案例:根据给定的天气状况判定是否去打网球
源代码:
from sklearn.cluster import KMeans import numpy as np from sklearn.model_selection import train_test_split X = np.array([['Sunny', 'Hot', 'High', 'Weak'], ['Sunny', 'Hot', 'High', 'Strong'], ['Overcast', 'Hot', 'High', 'Weak'], ['Rain', 'Mild', 'High', 'Weak'], ['Rain', 'Cool', 'Normal', 'Weak'], ['Rain', 'Cool', 'Normal', 'Strong'], ['Overcast', 'Cool', 'Normal', 'Strong'], ['Sunny', 'Mild', 'High', 'Weak'], ['Sunny', 'Cool', 'Normal', 'Weak'], ['Rain', 'Mild', 'Normal', 'Weak'], ['Sunny', 'Mild', 'Normal', 'Strong'], ['Overcast', 'Mild', 'High', 'Strong'], ['Overcast', 'Hot', 'Normal', 'Weak'], ['Rain', 'Mild', 'High', 'Strong']]) Y = np.array(['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No']) x_ = np.array([['Sunny', 'Cool', 'High', 'Strong']]) #对数据进行处理 X[X == 'Sunny'] = 1 X[X == 'Overcast'] = 2 X[X == 'Rain'] = 3 X[X == 'Hot'] = 1 X[X == 'Mild'] = 2 X[X == 'Cool'] = 3 X[X == 'High'] = 1 X[X == 'Normal'] = 2 X[X == 'Weak'] = 1 X[X == 'Strong'] = 2 Y[Y == 'No'] = 1 Y[Y == 'Yes'] = 2 x_ [x_ == 'Sunny'] = 1 x_ [x_ == 'Overcast'] = 2 x_ [x_ == 'Rain'] = 3 x_ [x_ == 'Hot'] = 1 x_ [x_ == 'Mild'] = 2 x_ [x_ == 'Cool'] = 3 x_ [x_ == 'High'] = 1 x_ [x_ == 'Normal'] = 2 x_ [x_ == 'Weak'] = 1 x_ [x_ == 'Strong'] = 2 X = [[int(x), int(y), int(z), int(v)] for x, y, z, v in X] Y = list(map(int, Y)) x_ = [[int(x), int(y), int(z), int(v)] for x, y, z, v in x_] x_tr,x_te,y_tr,y_te=train_test_split(X, Y, test_size=0.2)#切割 k_model=KMeans(n_clusters=3) k_model.fit(x_tr,y_tr) y_pre=k_model.predict(x_) if y_pre==2: y_pre = 'Yes' elif y_pre==1: y_pre = 'No' print('k均值算法的预测值:', y_pre)
结果: