jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
官方api:https://jsoup.org/
一、jsoup功能

简单的例子:抓取wiki的主页,解析成DOM
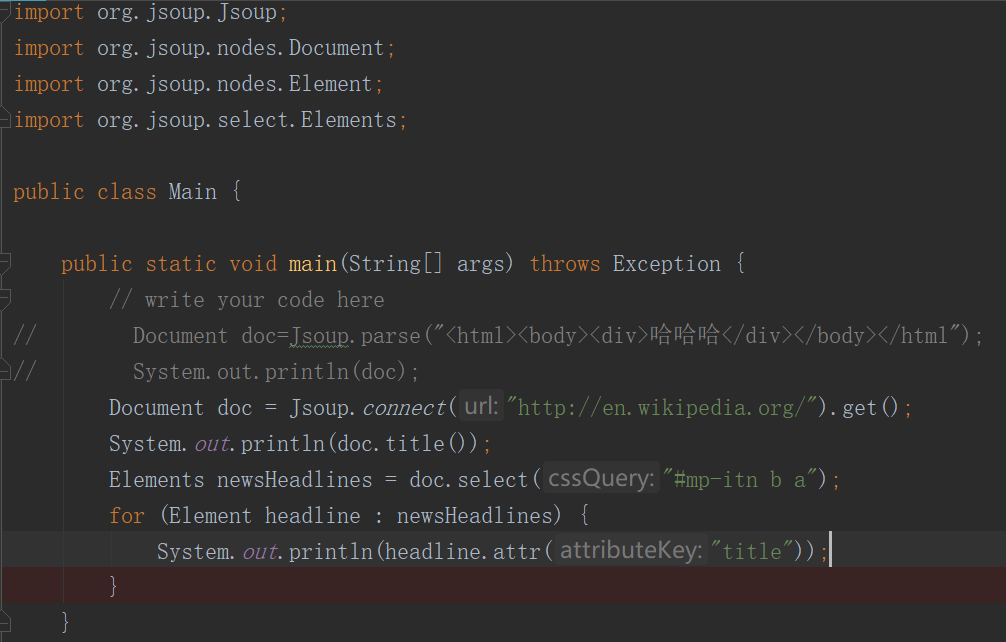

解析一个HTML字符串
目标可能是用户的一个html文件或网站的一个网页html.需要对其进行解析并抓取所需要的数据-------Jsoup.parse()
Jsoup.parse(String html)
Jsoup.parse(String html,String baseUri) 将输入的HTML解析为一个新的文档 (Document),参数 baseUri 是用来将相对 URL 转成绝对URL,并指定从哪个网站获取文档
只要解析的不是空字符串,就能返回一个结构合理的文档,其中包含(至少) 一个head和一个body元素。一旦拥有了一个Document,你就可以使用Document中适当的方法或它父类 Element和Node中的方法来取得相关数据。
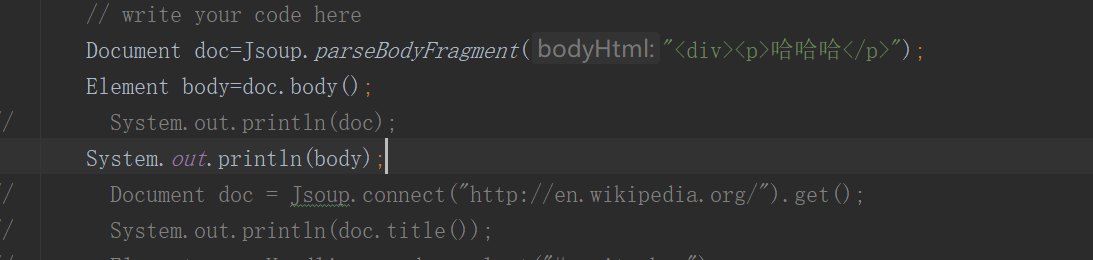
解析一个body片段
一个HTML片断 (比如. 一个 div 包含一对 p 标签; 一个不完整的HTML文档) 想对它进行解析。这个HTML片断可以是用户提交的一条评论或在一个CMS页面中编辑body部分------JSous.parseBodyFragment(String html)
parseBodyFragment 方法创建一个空壳的文档,并插入解析过的HTML到body元素中.
Document.body() 方法能够取得文档body元素的所有子元素,与 doc.getElementsByTag("body")相同。

从一个URL加载一个Document
需要从一个网站获取和解析一个HTML文档,并查找其中的相关数据------Jsoup.connect()
使用 Jsoup.connect(String url)方法:

connect(String url) 方法创建一个新的 Connection, 和get()方法一起取得和解析一个html文件
如果从该URL获取HTML时发生错误,便会抛出 IOException,应适当处理。这个方法只支持Web URLs (http和https 协议)
从一个文件加载document文档
Jsoup.parse(File in, String charsetName, String baseUri)