创建scrapy项目
命令:scrapy startproject dirctory_name

可以发现在tm_spider目录下创建了一个文件夹:spider_402,文件夹结构如下
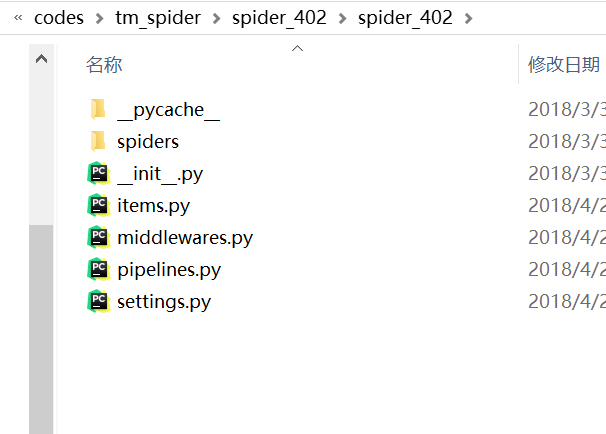

定义一个spiders爬虫class(类) ,该class是scrap.Spider的subclass(子类)。 在这个sipders class里面,要定义初始的request,需要进行爬虫的URL以及解析该URL网页获取数据。

1 import scrapy 2 3 4 class QuotesSpider(scrapy.Spider): 5 name = "quotes" #标识爬虫,在项目里面是唯一的, 6 7 #start_requests:返回Spider将开始抓取的请求的迭代,随后的请求将从这些初始请求中连续生成 8 def start_requests(self): 9 urls = [ 10 'http://quotes.toscrape.com/page/1/', 11 'http://quotes.toscrape.com/page/2/', 12 ] 13 for url in urls: 14 yield scrapy.Request(url=url, callback=self.parse) 15 16 def parse(self, response): 17 page = response.url.split("/")[-2] 18 filename = 'quotes-%s.html' % page 19 with open(filename, 'wb') as f: 20 f.write(response.body) 21 self.log('Saved file %s' % filename)

在项目的根目录下执行命令 scrapy crawl quotes
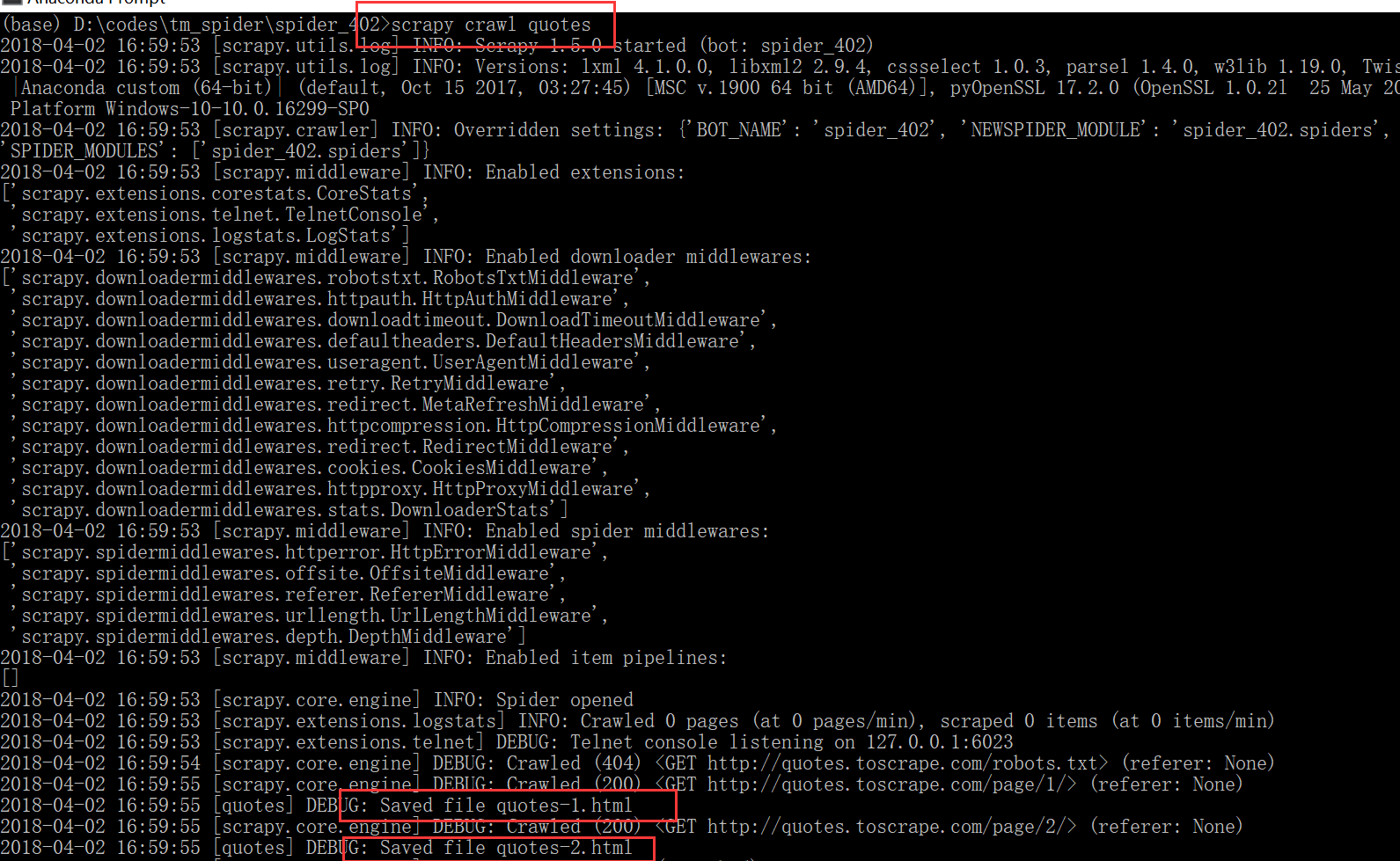

用scrapy的shell命令抓取网页
scrapy shell "http://quotes.toscrape.com/page/1/"

使用response对象的css关键字选择元素,它的返回值是选择器的列表。


::text取到title标签的文字内容
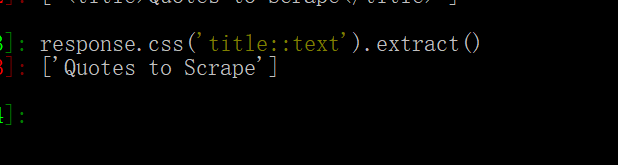
如果不带::text,就会把标签元素一起拿下来

extract()函数返回的是一个list类型的数据,如果要去第一个元素,可以用extract_first()