高斯判别分析(Gaussian discriminative analysis )是一个较为直观的模型,基本的假设是我们得到的数据是独立同分布的(IID),虽然在实际中这种假设很难达到,但有时候拥有了好的假设可以得到较好的结果。在Andrew Ng大神的CS229 Lecture notes中有一个例子:假设我们要对大象和狗分类,回归模型和感知机模型是在两类数据之间找到一个decision boundary,通过这个decision boundary来区分大象和狗。高斯判别分析提供了另外一种思路:首先我们观察大象,对大象建立一个模型来描述他的特点;在观察狗,并建立相应的模型来描述狗。当一个新的狗或者象过来时,我们首先带入象模型和狗模型,最后决定新来的的动物的类别。
这是一种软分类的思路,所谓软分类就是我们对一个样本决定它的类别时有一个可信度的概念,比方说当数据位于decision boundary附近的时候,我们将数据硬分为0或者1类(在这里是象和狗类)有时是不合理的,因为这是类别的不确定性更大。软分类的思路在高斯混合模型(GMM)中也有体现(Anil K. Jain在08年在TPAMI发了一篇文章是关于如何利用GMM来分类,小菜今年才想到这个思路,只能follow人家了)。我感觉这一点是高斯判别分析相对于其他模型的优越之处。
以下是干货
我们处理的数据往往是多维的,因此高斯分布也应该是多维的。一维的正态分布为
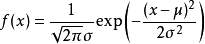
那么,n维正态分布表示为
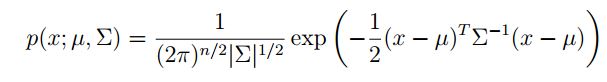
这里;后边的表示参数,该式表示以μ为均值,Σ为协方差的n维正态分布。
将n为高斯模型应用到监督学习中,假设输入数据为x,类别为y(0或者1),那么对应二类的分类问题有
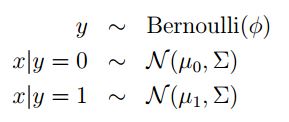
这就是经典的高斯判别分析模型,更为直观化的表述为
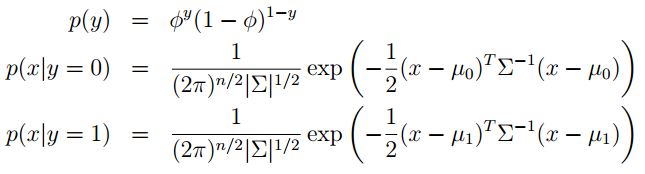
p(y)是满足伯努利概型(就是独立实验),第二个式子指的是当类别为y=0是,x的分布为一个高斯分布,第三个式子与第二个式子。上式中有四个参数(两个高斯分布用了同一个方差),实际上感觉5个的话更精确。
剩下的问题就是如何对这些参数进行估计了,用极大似然估计的观点本人没有做出来(才疏学浅),可以用下面直观地思路求解:每个数据的类别已经知道了,并且每一组别的数据分布都是高斯的,我们可以直接用高斯分布的参数估计来求解4(或者5)个参数。我们知道高斯分布的均值的估计就是数据的均值,那么
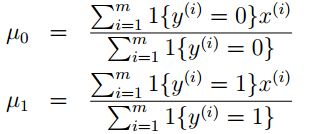
如果两个高斯分布用一个Σ,那么
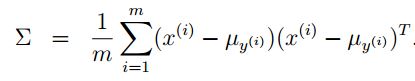
否则,可以单独求取每个类别的方差,还有一个参数Φ,直接统计点的个数得到
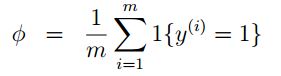
这就是GDA的思路和实现方式,看起来这个模型还是一个较为naive的模型,此模型只能应用于监督学习中,并且数据的分部必须大致是高斯分布的,对于一些奇怪的形状,可能并没有好的分类结果。
上面提到,高斯判别分析是一个软分类器,这就直接体现在数据与类别的分布(或者中心)的“亲近”程度上,至于怎么做,相信都有不同的见解。最主要的是这种基于数据density的方式的思路是很有创新性的。
以下是实现结果
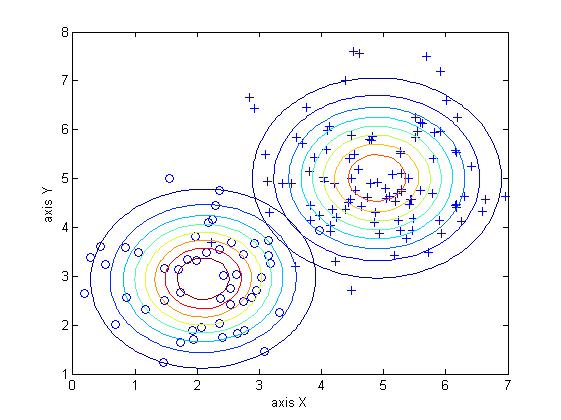
下面给出用MATLAB实现的高判别分析的代码
1 clc,clear
2 mu1 = [2 3];
3 SIGMA1 = [1 0; 0 1];
4 n1=2;
5 m1=50;
6 r1 = mvnrnd(mu1,SIGMA1,m1);
7
8 mu2 = [5 5];
9 SIGMA2 = [1 0; 0 1];
10 n2=2;
11 m2=100;
12 r2 = mvnrnd(mu2,SIGMA2,m2);
13
14 x=[r1;r2];
15 y=[zeros(m1,1);ones(m2,1)];
16
17 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
18 % plot the datas
19 figure
20 pos = find(y);
21 neg = find(y == 0);
22 plot(x(pos, 1), x(pos, 2), '+')
23 hold on
24 plot(x(neg, 1), x(neg, 2), 'o')
25 hold on
26 xlabel('axis X')
27 ylabel('axis Y')
28
29
30 %%%%%%%%%%%%%%%%%%%
31 sigma1 = cov(x(neg,:));
32 sigma2 = cov(x(pos,:));
33 mu1=mean(x(neg,:));
34 mu2=mean(x(pos,:));
35
36 [x1 y1]=meshgrid(linspace(0,10,100)',linspace(0,10,100)');
37
38
39 X1=[x1(:) y1(:)];
40 z1=mvnpdf(X1,mu1,sigma1);
41 contour(x1,y1,reshape(z1,100,100),8);
42 hold on;
43
44 z2=mvnpdf(X1,mu2,sigma2);
45 contour(x1,y1,reshape(z2,100,100),8);
46 hold off;
原创文章,转载请注明出处,谢谢!