每次提到贝叶斯这三个字,心中的仰慕之情油然而生。感觉贝叶斯推断是众多机器学习算法的基础(尤其是统计学习)。一个很简单的公式应用到非常复杂和广泛的领域,真是一件了不起的事情。
贝叶斯公式
再讲贝叶斯公式之前,首先回顾一下概率的知识。若 A、B 是两个事件,我们用P(A)表示事件A发生的概率,P(B)表示事件B发生的概率。若果A和B相互独立,那么我们有P(AB)=P(A)P(B);如果A、B不独立,我们有P(AB)=P(B)P(A|B)。
贝叶斯公式为
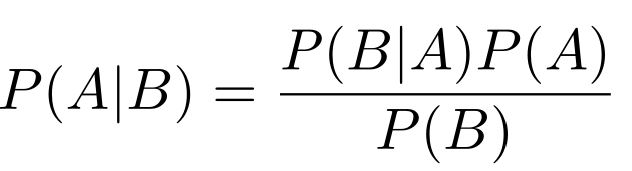
证明起来也是比较简单的(根据条件概率公式直接得到)
![]()
贝叶斯公式的强大之处是他建立了P(A|B)和P(B|A)的桥梁,在很多情况下,我们可能难以计算P(A|B),那么通过贝叶斯公式,有效地转化为其他的概率的计算,这种思想是非常重要的,感觉也是贝叶斯的精髓所在。记得大学的时候我的概率统计老师经常讲“结果已知,原因未知,就用贝叶斯公式”。当时只是为了便与考试,没有深入理解这句话的含义。在监督学习中,我们已知一组样本的特征X,需要对类别Y进行推断,也就是计算Y=t的概率。但是Y是未知的,也就是我们需要计算P(Y=t|X),那么我们可以利用贝叶斯公式求出
![]()
这里:
P(X|Y=t):可以直接统计training sample得到,当然对于离散和连续的情况都要进行相应的处理。
P(Y=t):就是training sample 中类别t出现的概率
P(X) :根据全概率公式得到,对于分类的任务来说,P(X)是一个常数,往往可以不参与计算(相当于一个标准化的操作)
朴素贝叶斯分类器(从一个例子开始)
Andrew Ng大神在他的CS 229 note举了这样一个例子:考虑一个邮件分类问题,假设我们想要构造这样一个分类器,它能够根据邮件中出现的单词决定这是否是一封垃圾邮件。首先我们建立一个字典,一种可能的字典构建方案为设计一个数组(当然数组可能不是最佳的设计方案),这个字典为

那么如何建立feature X呢,我们这样建立,对于一封邮件,如果包含字典中的单词i,那么就在X的相应位置设为1.例如,一封邮件包含bag和food两个单词,那么它的feature为
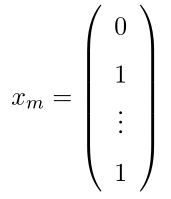
那么,我们的训练集为如下,其中yi代表类别标签
![]()
一个很强的假设:条件独立
在贝叶斯公式中,我们需要计算P(X|Y)=P(x1,x2,...xm | Y),根据多项式分布(http://zhangxw.gotoip1.com/ZCL/part2/C11g.htm),我们的模型有2m 种输出。也就是我们需要2m 个参数计算贝叶斯公式,模型太复杂,因此引出条件独立的概念:在给定类别Y的情况下,xi 和 xj 的出现是独立的,在这个例子中就是说在一封邮件中,假设我们已经认为这封邮件是垃圾邮件(条件),那么单词buy和food的出现是独立的。乍一看这个假设可能没有很大的问题,但也是这个模型最大的弱点。有一种情况比方说我们的经常把 have lunch一起使用,显然这两个单词是不独立的,假设独立性必然存在一定的问题。但是为了简化计算,我们引入了这个条件独立,这就是为什么我们叫朴素贝叶斯。
有了条件独立的概念,P(X|Y)的计算为
![]()
![]()
这样计算就非常简单咯。
举个数据挖掘课上的例子来进行解释
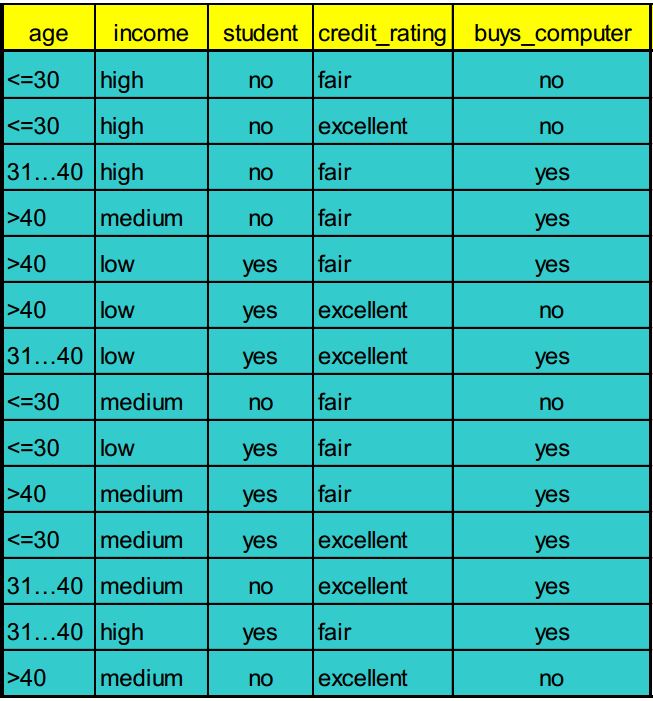
最后一列buys_computer代表了数据的类别,X属性为age, income, student和credit_rating四个。
来了一个新的样本<age,income,student,credit_rating>=<20, medium,yes,fair>,我们利用贝叶斯公式计算是否buys_computer
第一步:上贝叶斯公式
![]()
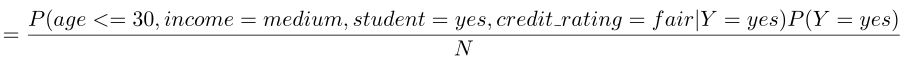
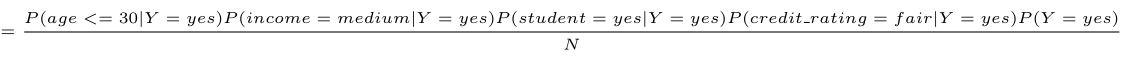
第二步:计算各个量
P(age<=30|Y=yes)=2/9
P(income=medium|Y=yes)=4/9
P(student=yes|Y=yes)=6/9
P(credit_rating=fair|Y=yes)=6/9
P(Y=yes)=9/14
同理可以得到
P(age<=30|Y=no)=3/5
P(income=medium|Y=no)=2/5
P(student=yes|Y=no)=1/5
P(credit_rating=fair|Y=no)=2/5
P(Y=no)=5/14
第三步:计算后验概率
![]()
=2/9*4/9*6/9*6/9*(9/14)/N=0.028/N
![]()
=3/5*2/5*1/5*2/5*(5/14)/N=0.007/N
第四步:决策
一般使用最大后验概率原则计算,对于这个问题我们可以给出P(Y=yes|X)的概率较大,因此预测筒子是buys_computer。
拉普拉斯平滑
考虑如下的情况:假设在某个训练数据D上,类buys_computer包含1000个元组,其中0个元组income=low,990个元组income=medium,10个元组income=high。这些事件的概率分别为0,0.990,0.010。对于一个新的测试数据,如果income=low,因为我们的训练集合上P(income=low)=0,所以带入贝叶斯公式以后。该样本属于yes和no的概率均为0,那么就出现了不可分的情况,这就引入了拉普拉斯平滑。
具体操作为:如果出现元组概率为0的情况,那么在每一种可能的类别中的概率分别加一个比较小的数字,避免出现0的情况,比如我们可以将1加入low,medium和high的元组,这样元组总数为1003,low为1,medium为991,high为11。这样就避免了0概率值的出现,并且对概率的影响不大。
原创文章,转载请注明出处,谢谢!