作者 | 王明明,涛思数据软件工程师

小 T 导读:在计算机系统中,缓存是一种常用的技术,既有硬件缓存,比如我们经常听到的 CPU L2 高速缓存,也有软件缓存,比如很多系统里把 Redis 当做数据库的缓存。本文为根据 TDengine 线上 Meetup 第四期王明明的分享《TDengine 缓存技术解析》(视频)整理而成。
TDengine 是一款高性能的物联网大数据平台。为了高效处理时序数据,TDengine 中大量用到了缓存技术,自己实现了哈希表、缓存池等技术。今天我会为大家讲解 TDengine 中用到的这些缓存技术。
首先我会介绍一下什么是缓存,常用的缓存技术,最后重点分享 TDengine 中的相关技术,最好讲一下改进和优化的方向。下面我们正式开始。
什么是缓存?
凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存。
-
缓存最早是用来协调 CPU 和主内存之间的速度差异,进化出了目前的 L1/L2/L3 三层 CPU 内部的高速缓存;
-
在内存和硬盘之间也有 Cache,每次写磁盘时并没有立即刷到磁盘上,而是写入到磁盘缓存中,由操作系统负责 flush 到磁盘;
-
此外,硬盘与网络之间也有某种意义上的 Cache,比如 CDN 缓存,代理服务器的缓存等等。
缓存工作的原则主要是引用的局部性,包括空间局部性和时间局部性。
-
空间局部性是指 CPU 在某一时刻需要某个数据,那么很可能下一步就需要其附近的数据,例如加载读磁盘数据的时候,虽然只需要一部分数据,但是每次都加载一个块,那么当需要附近数据的时候就可以直接从内存获取,避免再读取磁盘。
-
时间局部性是指当某个数据被访问过一次之后,过不了多久时间就会被再一次访问。例如我们手机后台运行程序,会把最近打开的应用缓存在后台,很可能一会儿还会访问相同的应用,这种情况下直接将其从后台调到前台即可。
在使用缓存时要根据系统的架构、性能的要求以及要解决的问题选择合适的缓存位置,比如内存缓存、 磁盘缓存、分布式缓存等。
使用缓存有很多优点:
-
提高性能,将相应数据存储起来以避免数据的重复创建、处理和传输,可有效提高性能。
-
提高稳定性,同一个应用中,对同一数据、逻辑功能的多次请求是经常发生的。当请求量很大时,如果每次请求都进行处理,消耗的资源是很大的浪费,也同时造成系统的不稳定。
-
提高可用性,有时,提供数据信息的服务可能会意外停止,如果使用了缓存技术,可以在一定时间内仍正常提供对最终用户的支持,提高了系统的可用性。
缓存是有状态的,包括时间状态和空间状态。
-
时间状态:应用程序使用的永久数据; 只在进程周期内有效;和特定的用户会话有关; 处理某个消息的时间内有效。
-
空间状态:应用程序/进程/线程/单机/分布式/用户/角色。
使用缓存时需要考虑的问题:
-
安全性:线程安全/权限安全
-
序列化
-
缓存数据优化
-
提前加载/动态加载
-
过期策略:FIFO/LRU/LFU
-
管理:效率监控,大小限制
缓存一致性问题:
-
当使用分布式的缓存时,需要考虑多个缓存的一致性问题,防止由于不一致出现问题。
-
处理一致性问题时需要根据实际的应用场景兼顾 CAP 原则。根据问题的场景不同,一致性要求也不同,可以强一致性或者弱一致性(最终一致性)。
a. 比如银行转账场景需要强一致性,数据没统一之前,不允许用户进行操作,防止金额出错。
b. 大多数互联网产品为了保证可用性和分区容错性,通常采用弱一致性,比如不同地区的用户看到的同一个排行榜可能有非常短暂的不同,但数据同步成功后,排行榜就相同了,这个延迟通常在几十 ms,对于用户来说是可以接受的。
常用的缓存技术
-
使用硬件缓存 (CPU Cache)
-
使用本地内存缓存(双缓冲/环形缓冲/缓冲池)
-
使用内存映射文件 (mmap)
-
使用数据库缓存 (Redis/MySQL)
TDengine 中的缓存方案
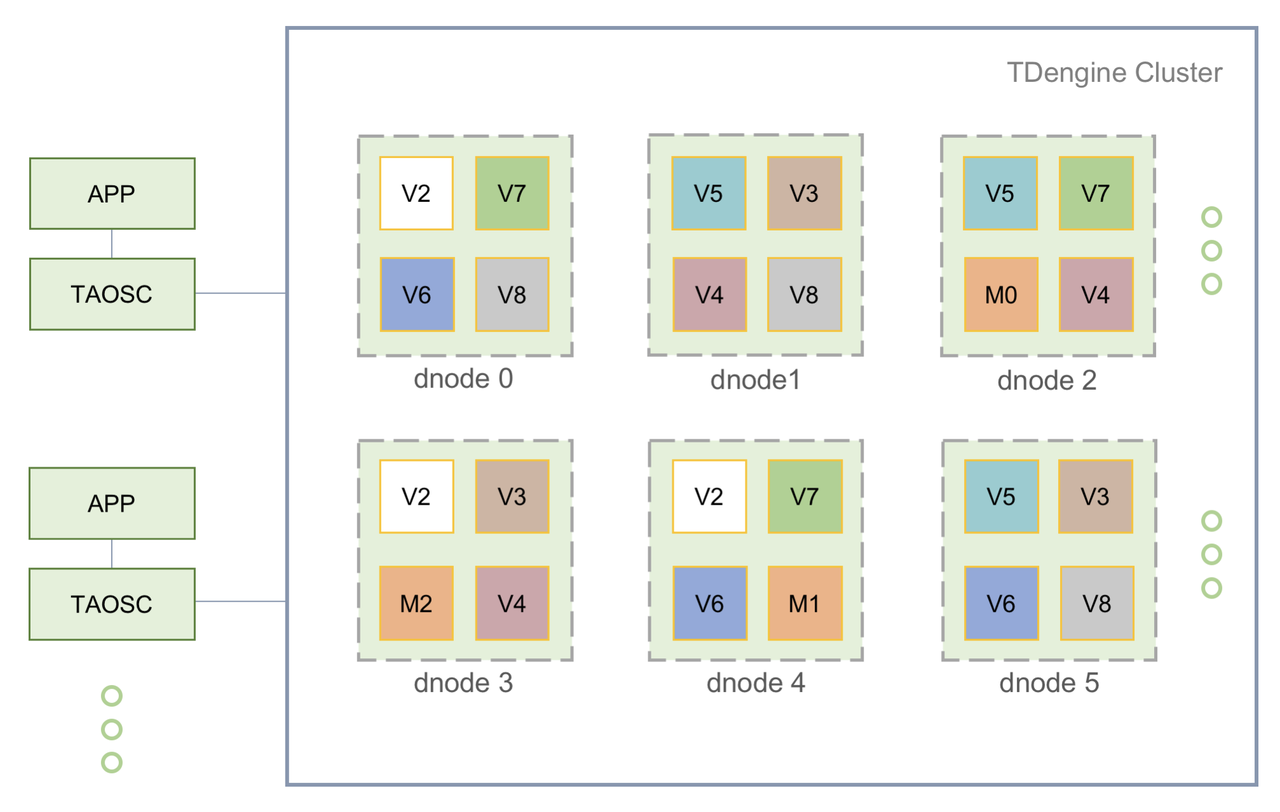
首先我们来复习一下 TDengine 的整体架构。
-
数据节点(dnode):服务进程,可以包括多个 vnode 和 mnode,查询数据时需要 dnode 的网络位置来获取数据。
-
虚拟节点(vnode):存储、查询的基本单位。多个 vnode 组成一个虚拟节点组(VGroup),分布在不同的机器上,起到备份的效果。同时 vnode 也便于水平扩展。
-
管理节点(mnode):存储数据库的元数据,起到管理集群的功能。
再来看一下 TDengine 的数据模型。
-
一个采集点一张表(时间戳作为主键,顺序存储)
-
一张表的数据在文件中以块的形式连续存放
-
文件中的数据块大小可配
-
采用 Block Range Index(BRIN)索引块数据
TDengine 中都有哪些数据需要缓存呢?
具体可以分为如下几类:
-
元数据 (table meta/stable vgroup)
-
连接数据 (rpc/http session)
-
查询缓存 (qinfo handle/ show info)
-
最新数据 (last 和 last_row)
-
时序数据 (buffer pool/ multilevel storage)
接下来我们就具体看一下 TDengine 中的缓存方案。
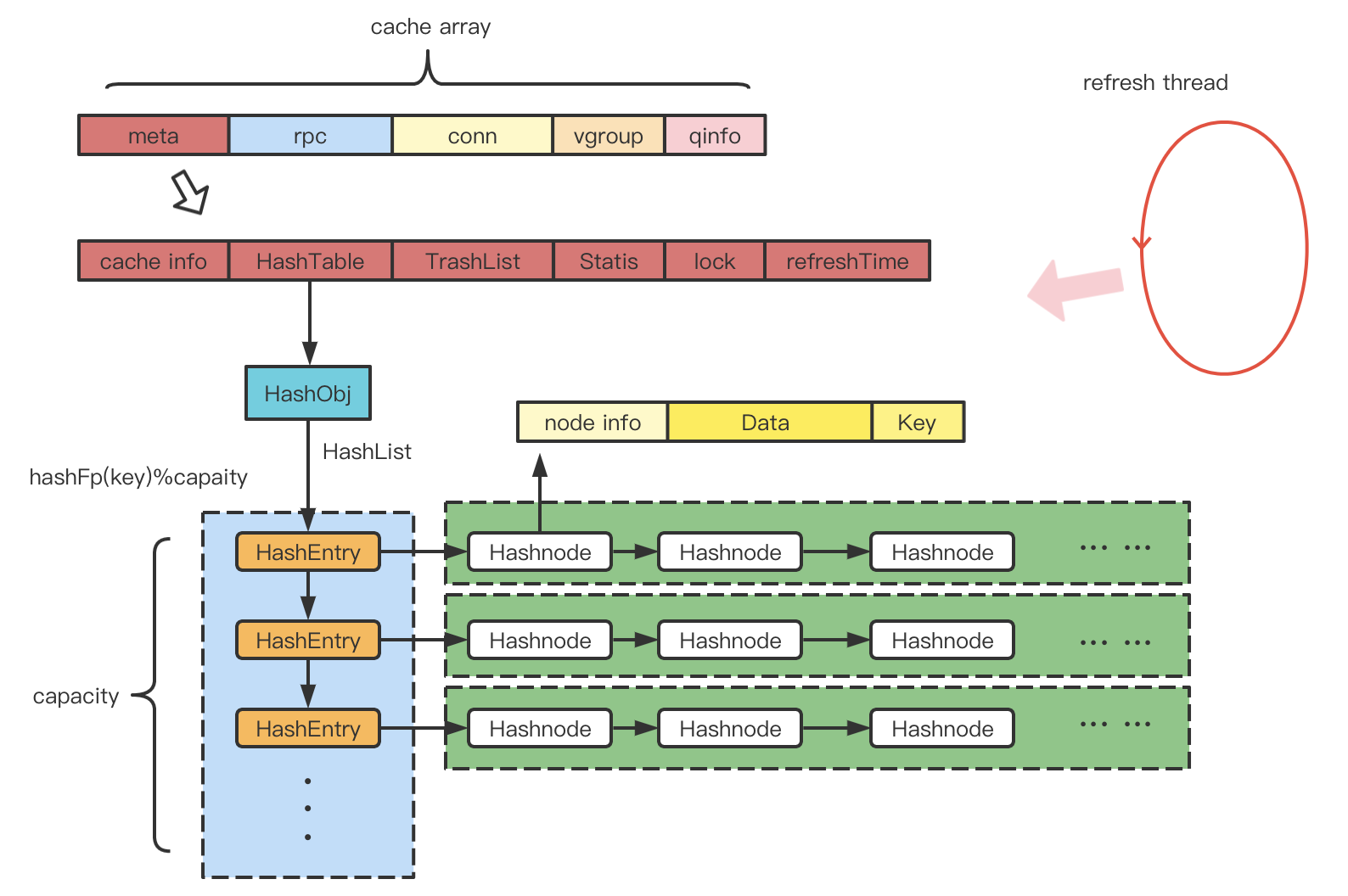
首先是通用的哈希缓存 (meta data/ rpcObj/ qinfo)。
-
哈希缓存,通过一个列表来管理,每个元素是一个缓存结构,里面包括缓存信息、 哈希表 、垃圾回收链表、统计信息、更新频率、锁等信息。此外,有一个刷新线程定时检测缓存列表中过期的数据,将其删除。
-
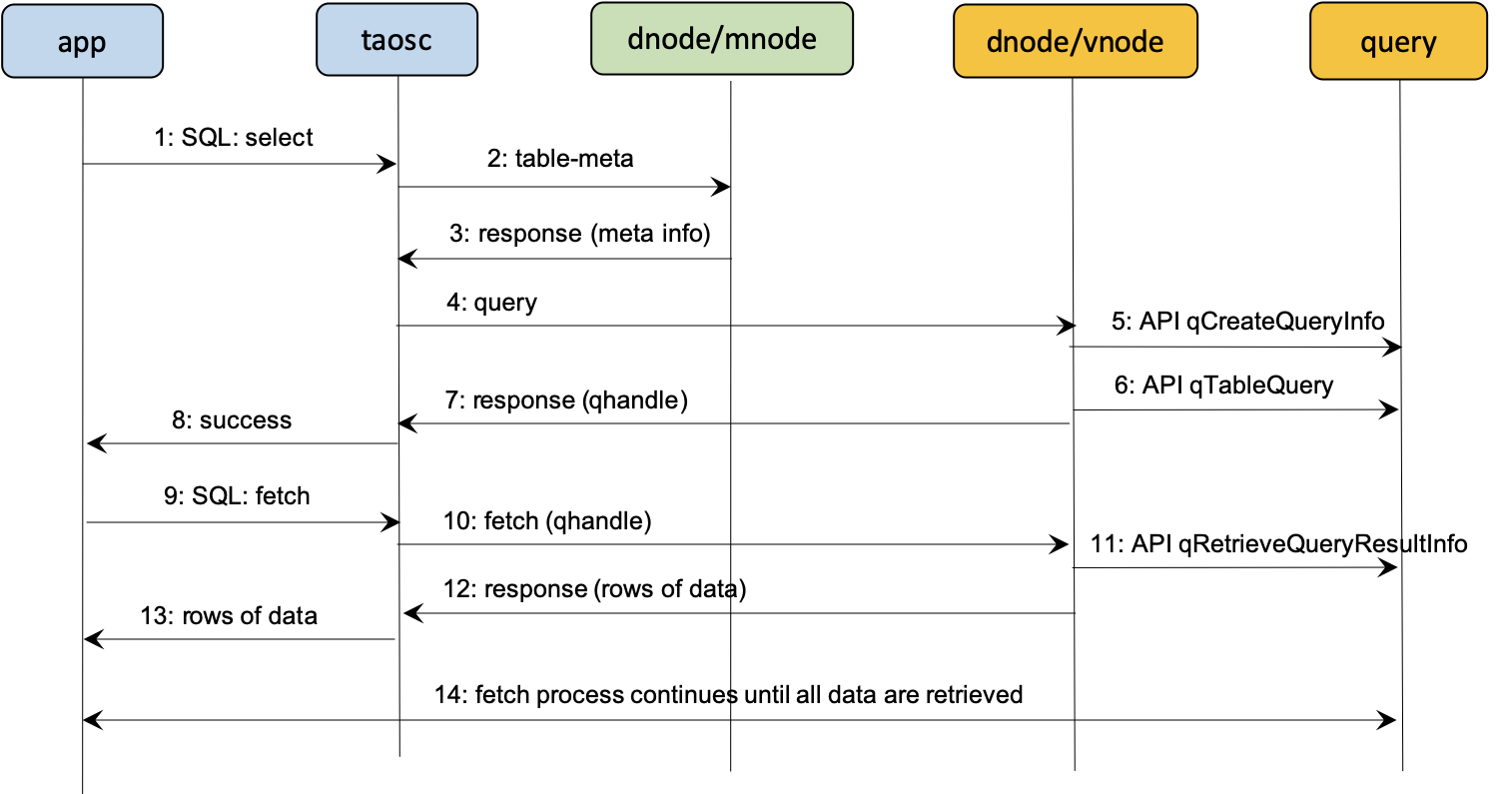
查询计划 id (query handle),query handle 是数据库查询时,server 先生产一个执行计划,返回给 client,然后 client 拿着这个计划 id,分多次去 server 取数据,直到数据查询完。这个缓存是消息时间范围,整个进程内有效的,不需要更新,使用完即释放。
-
元数据缓存(meta data), meta data 数据主要记录数据表的 scheme,所在的节点地址。通过客户端缓存 meta data 可以避免频繁的向 mnode 取数据。但是 meta 数据需要考虑更新一致性问题。通过版本号来控制。
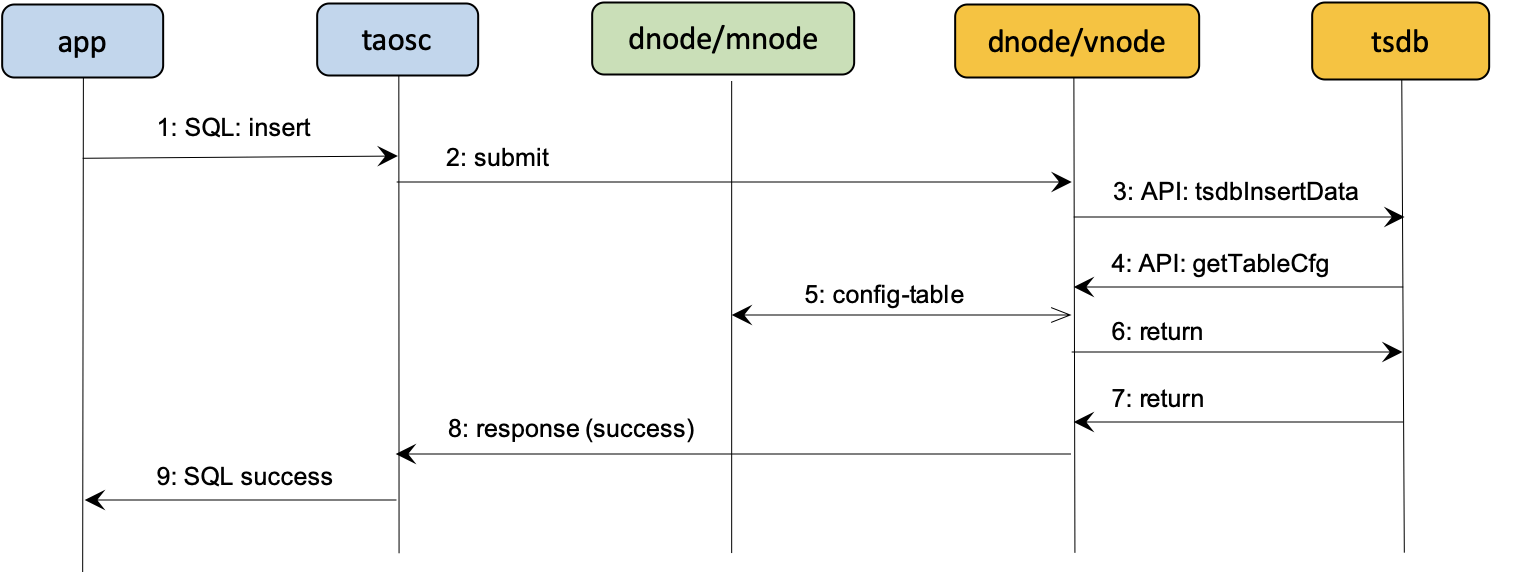
其次是 TSDB 内存块缓存 (double buffer/buffer pool)。
-
TDengine 提供双缓存/缓存池来优化数据写入查询的性能。预分配 16M*6 的 buffer pool,使用超过 1/3 容量落地,落地时 mem 转化为 imei(不可变更),负责写入磁盘。
-
直接将最近到达的数据保存在缓存中,可以更加快速地响应用户针对最近数据的查询分析,整体上提供更快的数据库查询响应能力。
-
TDengine 重启以后系统的缓存将被清空,之前缓存的数据均会被批量写入磁盘,之前缓存的数据不会重新加载到缓存中。
-
数据查询时首先通过 time range 定位数据所在的位置,因为 MEM 和 IMEM 中都记录有最新、最旧数据的时间戳。然后如果在 MEM 中,通过跳表来快速查询数据位置。在磁盘中,通过磁盘块文件索引查找数据,最后做结果融合返回。
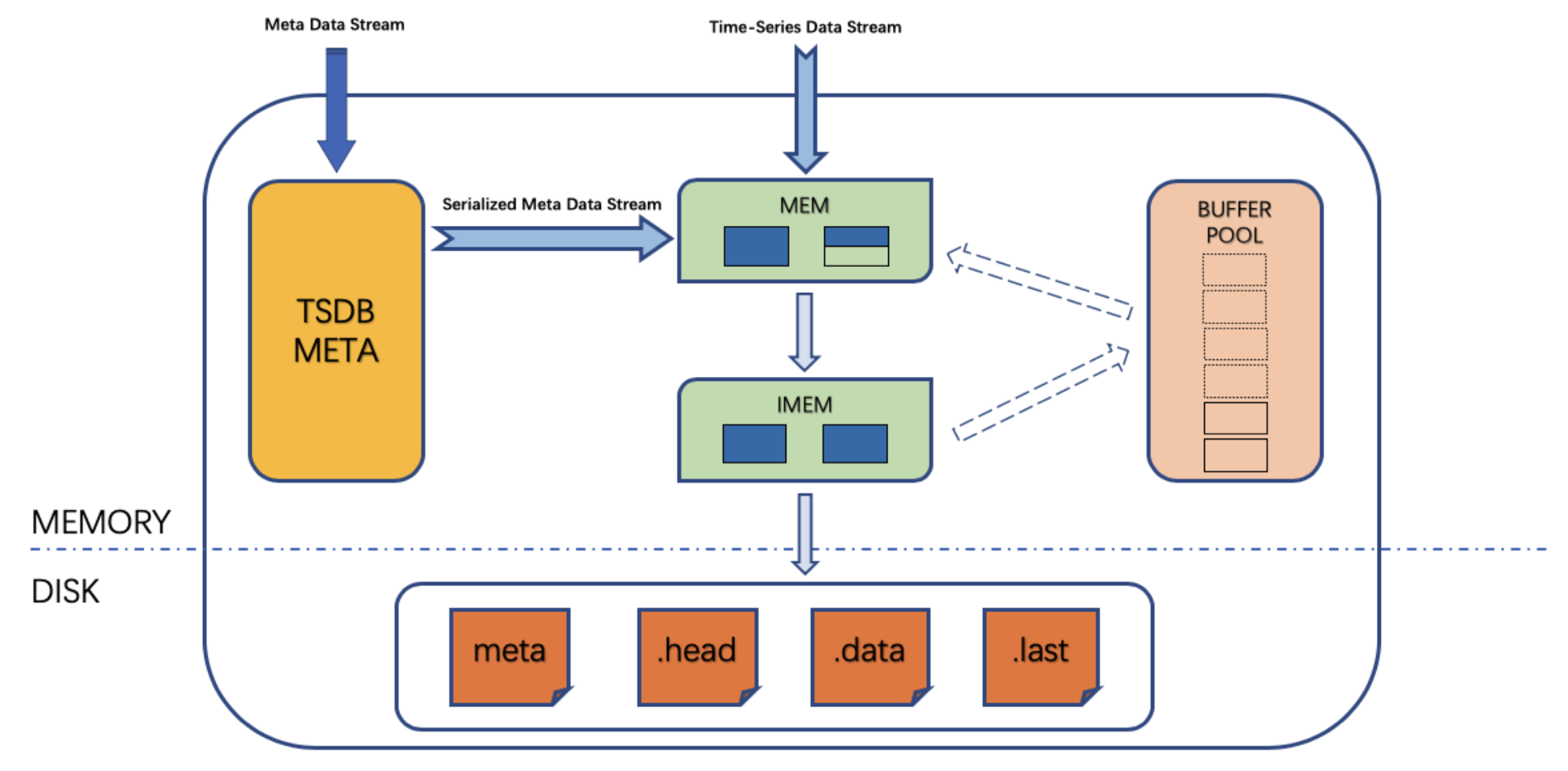
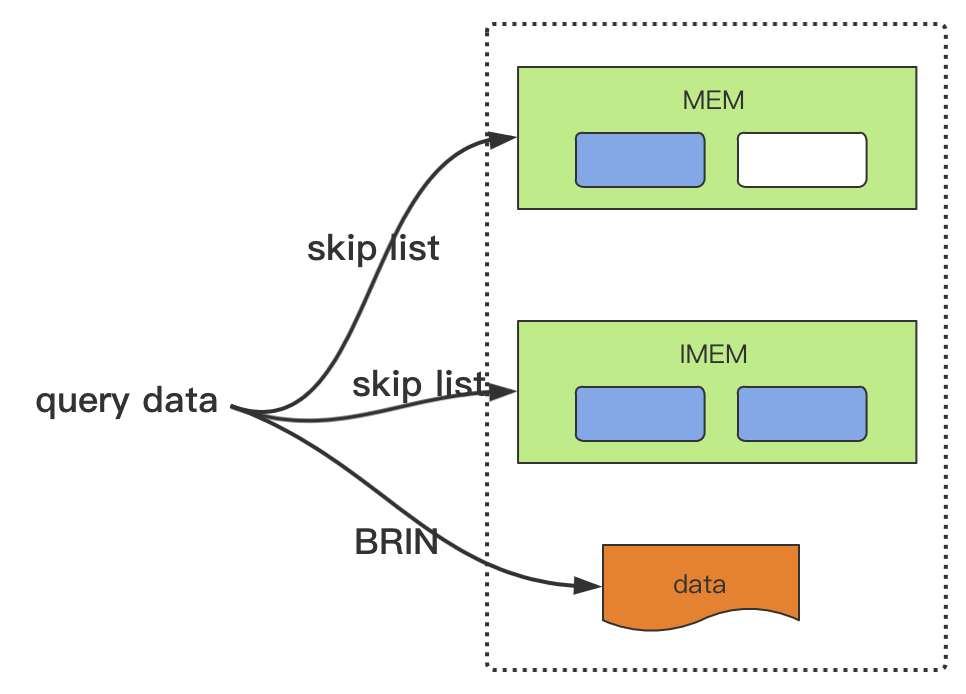
再来看 last 和 last_row 缓存 (local storage)。
-
时序数据库总是有对最新一行数据或者某列最新一条数据查询的需求,因此设计了 last 和 last_row 缓存来快速响应用户需求。防止每次都去磁盘查询数据。
-
每个表开辟缓存区缓存该数据,服务启动时会全量加载,插入时会更新,此外在配置更新的时候,也会更新缓存数据。比如,默认是关闭的。用户使用命令开启缓存功能时,就会加载数据,同理关闭开关时,会释放之前的缓存区。
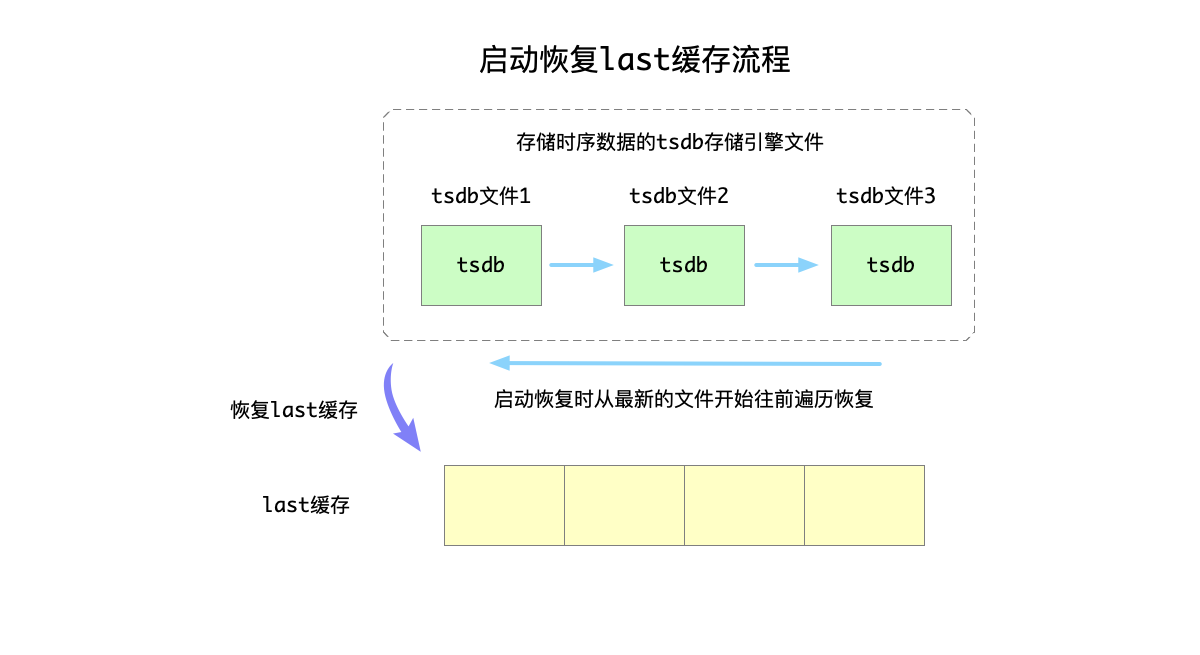
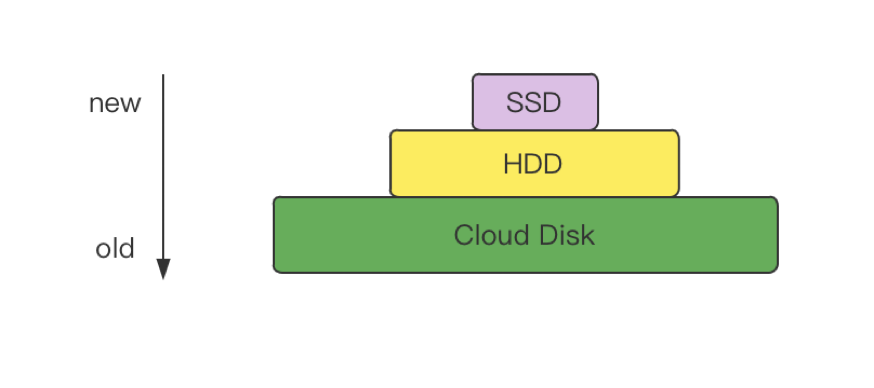
最后我们再来看一下多级存储 (ssd/hdd/cloud)。
由于物联网的数据量是巨大的,为了很好的平衡性能和成本,TDengine 还采用了分级存储的思想,不同热度数据存储在不同的地方。分级存储的这一思想也体现在计算机的体系结构里(寄存器、L1/L2 Cache、内存、硬盘)。
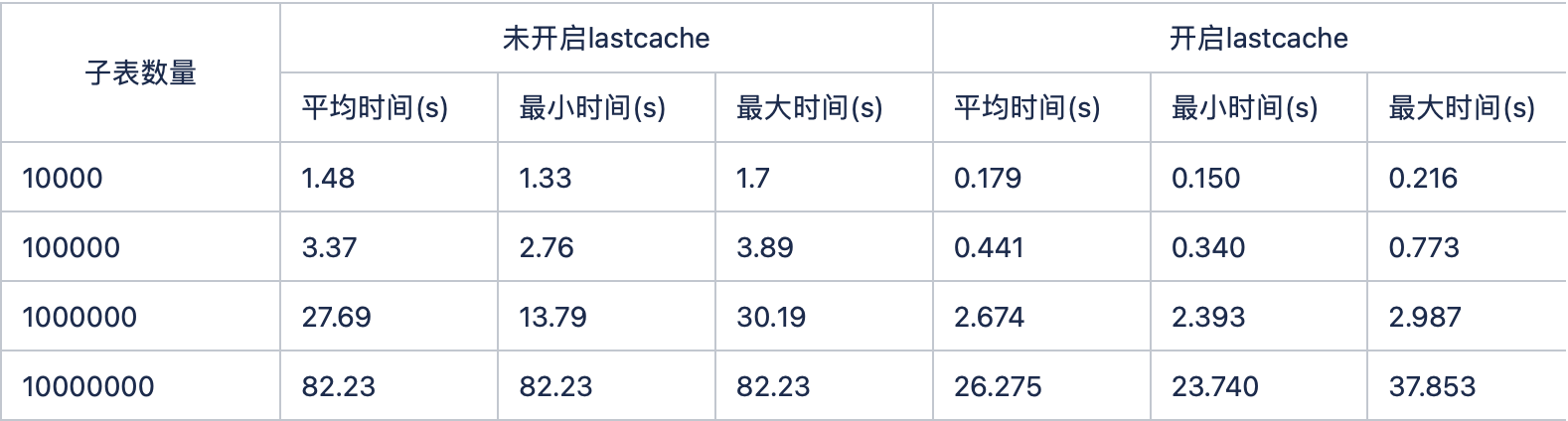
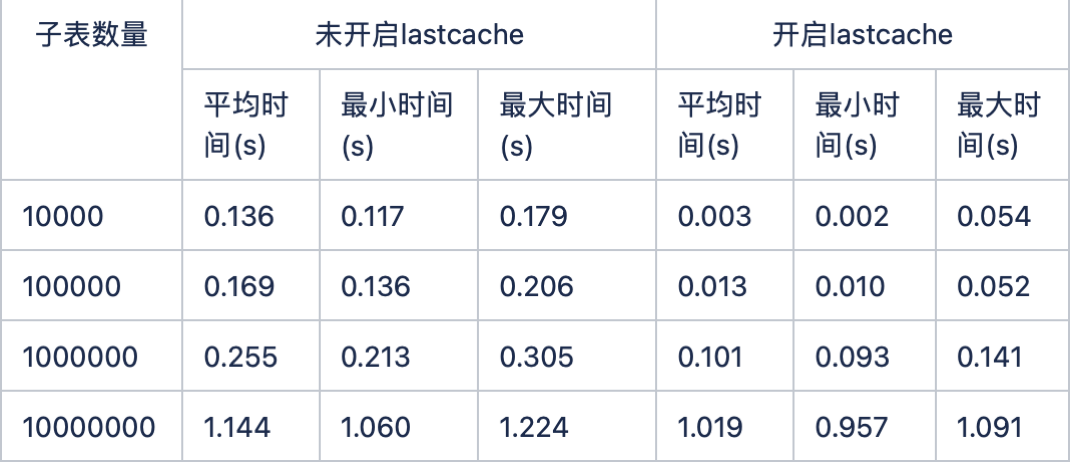
缓存对性能提升举例
-
测试环境: 12 核 i7 3.2GHz 64GB 4T HDD
-
last_row 缓存性能对比 (select last_row(*) from stable 查询语句 1000 次,统计查询时间)
-
last 缓存性能对比 (select last(*) from stable 和 select last_row(*) from stable 查询语句 1000 次,统计查询时间)
-
开启缓存性能比不开启缓存提升将近 1 个数量级。缓存对系统性能提升还是很大的,所以,在使用 TDengine 时,可以根据自己的需求,打开或关闭开关
问题及改进优化方向
先来看问题,主要是两点:
-
mnode 的 meta 数据全量加载,表数量很大时,内存占用大,启动慢;
-
last 和 last_row 缓存启动全量加载。
最后我们再来看一下优化方向:
-
全量加载改为动态加载;
-
预分配缓存大小,通过 LRU 等策略来更新数据;
-
qhandle 通过对象池管理,避免频繁 calloc。
如果想了解更具体的实现细节,可以在GitHub上查看相关源代码,也期待大家加入进来,一起改进TDengine!
关于作者
王明明,北京邮电大学毕业,主修方向为电子信息、模式识别和图像处理。毕业后入职腾讯,先后在 TEG 魔王工作室卡牌游戏开发、腾讯地图手图后台开发、腾讯看点知识图谱后台开发。对网络编程、RPC 框架原理、Redis 缓存等技术有深入的研究。