Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark阅读笔记
这篇论文主要是两个贡献:LIP数据集与JPPNet网络。(论文说自己有三大共享,还有一个贡献是探索多个前沿方法在不同数据集上的表现,分析Parsing与Pose的关系,并以此说明自己的数据集最具区分性,自己的方法最好)
LIP数据集是迄今为止(2018年初)最大的像素级别的人体区域解析和姿态估计的数据集,不仅有关节点的位置与连接(图左),而且有人体区域的语义分割图(图右)。

LIP总计5W张图像与groundtruth,其中3W用于训练,1W用于测试,剩余1W不公开,用作评估Parsing和Pose Estimation效果好坏的基准。Parsing的标签共19个(包括背景则20),人体关节点16个。其图像包含遮挡、背部、复杂背景等等干扰因素,其情况比ATR数据集[只有正面的街景模特]更通用。
JPPNet(Joint Body Parsing & Pose Estimation Network)一个网络联合了Parsing和Pose Estimation两个任务,利用两个任务的相关性,使得他们相互促进。随后论文介绍了SS-JPPNet,不需要关节点信息去做图像分割(针对parsing任务无需额外的监督,称作自我监督的结构敏感学习方法),同样有很好的parsing效果。
主要研究方法:
现有方法的不足与本方法的创新点;(1)现有方法在Parsing时缺乏对人体结构的考虑。而且分割结果所包含的上下文信息和人体结构关系利于找到人体关节。Parsing和Pose Estimation这两个任务是在不同的粒度上标记图像,一个是像素级别的,一个是关节点位置。像素级别的有非常详细的信息,关节点位置则能提供高层结构信息,所以说这两个任务是互补的。(2)现有coarse-to-fine(由粗到细)方法在这两个任务中的应用方式不一样,对Parsing而言,使用多尺度分割或注意力缩放,对Pose Estimation而言,使用迭代位移细化。本文方法是联合细化。
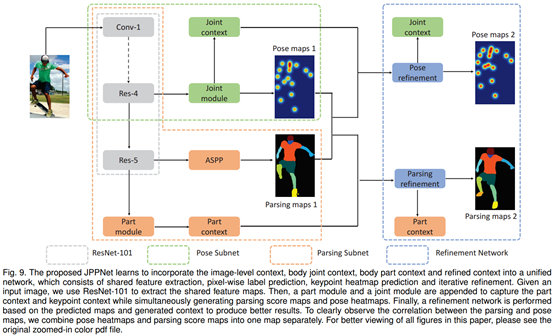
接下来讲一讲网络的构成。该网络即联合了Parsing和Pose Estimation,又联合两种由粗到细的策略【多尺度特征(多种尺度输入网络得到不同的结果,再进行融合,代码中的*0.75,*1,*1.25)和迭代细化(后接了两次细化的网络)】。网络结构如图所示
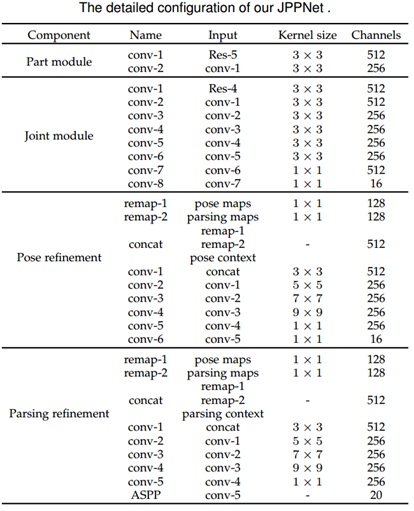
网络每一模块的细节如下表
在该网络中使用一个共享残差网络来提取人体图像特征,后面接两个不同的网络来得到Parsing结果与Pose结果,在这两个结果后面分别接细化网络去进一步细化出更精确的结果。
特征提取。卷积核为多孔卷积(也叫空洞卷积/上采样卷积,需详细,可控制特征的分辨率;在不增加参数计算机量的前提下增加感受野大小以结合更大的context)的ResNet101。本框架中,前4个ResNet共享用于提取图像特征(都是ResNet101,名字Res-1,Res-2,Res-3,Res-4)。
Parsing子网络与Pose子网络。Res-5基本结构是带多孔卷积的ResNet101,多孔空间金字塔池化(ASPP,需详细)作为输出层,以在多个尺度上鲁棒地分割图像。ASPP是具有多个采样率和感受野的卷积特征层,可以以多种尺度获取图像的context。为了生成细化阶段所需要的context,再接了两个卷积模块。详细可见上面的表格中的Part Module与Joint Module。
参考论文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLab v2,引用量1604。该论文使用多孔卷积核ASPP做出来3个贡献:①随着卷积与池化,特征图分辨率降低,该方法控制分辨率;②需处理的目标有尺度多样性;③图像分割更准确)
参考博客:https://blog.csdn.net/cicibabe/article/details/71173965
多孔卷积/空洞卷积
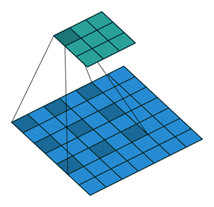
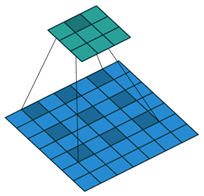
用不同采样率的多个并行的多孔卷积层做映射,“多孔空间金字塔池化(ASPP)
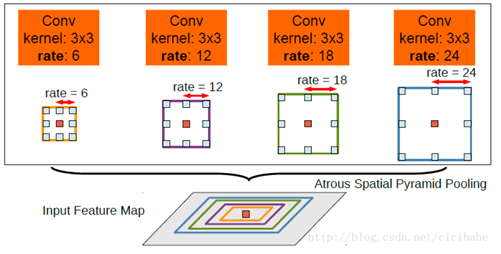
(以上的特征提取,子网络(多孔卷积,ASPP),已经由DeepLab实现,调用DeepLab中的ResNet101即可)
细化网络。该细化网络能够迭代地细化Parsing与Pose的结果。首先,用一个额外的1*1卷积将中间结果映射到一个更大通道数的特征空间中(只改变厚度。);然后,四个卷积层(卷积核大小分别为3*3,5*5,7*7,9*9),以捕获足够多的局部context,增加感受野的大小有助于长期关系(高层特征);接下来,1*1卷积层用来生成细化阶段的特征。为了细化Pose,连接了[Pose中间结果,Parsing中间结果,Pose Features]。为了细化Parsing,连接了[Pose中间结果,Parsing中间结果,Parsing features],并使用ASPP来产生Parsing最终预测结果。
整个框架能够端到端的训练,中间结果也应用了损失函数。
自我监督结构敏感学习:
以上是因为ground-truth有两个(Pose与Parsing),如果训练数据只有Parsing的标签,该网络则修改为SS-JPPNet(Self-supervised Structure-sensitive JPPNet),不需要人体关键点这一标签。SS-JPPNet 生成的Parsing效果同样也是目前最好(2018年初)。
高层的人体结构信息可以帮助parsing,比如pose。所以,没有关节点的ground-truth,该论文的方法则根据已有的parsing ground-truth生成近似人体关节,来进一步指导parsing生成。为了使生成的parsing结果与人体结构在语义上一致,我们将关节点结构的损失作为parsing损失的权重,即结构敏感损失。
从part注释中找到对结构敏感的监督:将9个区域的中心作为人的关节点(头部,上身,下身,左臂,右臂,左腿,右腿,左鞋,右鞋)。使用欧几里得度量(欧氏距离??)来评估预测的关节点。该损失乘以parsing的损失,得到该框架总的自我监督结构敏感损失。
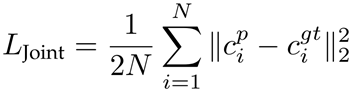
上标p代表预测值,gt代表ground-truth,N=9。C代表heatmap,没有某个关节,则该关节的heatmap为全0。总损失:
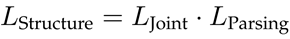
L(parsing)像素级别的softmax loss(计算方法见博客)。叫“自我监督(self-supervised)”是因为损失是由已有信息生成的额外信息组成。
实现:
JPPNet调用开源DeepLab中的ResNet101网络为基础架构(DeepLab v2);SS-JPPNet则增加Attention机制(DeepLab另一改进版,具体不懂,参考论文: Attention to scale: Scale-aware semantic image segmentation)。
训练JPPNet时,输入图像缩放到384*384,在预训练好的模型的上,再用该论文的LIP数据集训练30个epoch,其中采用的数据增强方式是:随机缩放[0.75,1.25]倍,随机裁剪,随机翻转。训练SS-JPPNet时,使用DeepLab预训练好的模型,基于Attention输入图像尺寸321*321,首先在LIP数据集上训练网络30epoch,然后执行“自我监督结构敏感”损失,fine-tune20个epoch。
图像语义分割的发展
FCN
SegNet
Dilated Convolutions 空洞卷积
DeepLab (v1 & v2)
RefineNet
PSPNet 金字塔
Large Kernel Matters
DeepLab v3 空洞卷积+金字塔
DeepLab v3讲解的参考资料:https://www.jiqizhixin.com/articles/deeplab-v3