转载请注明出处:https://i.cnblogs.com/EditPosts.aspx?postid=5748920
一、基本概念
不相交集类维持着多个彼此之间没有交集的子集的集合,可以用于 判断两个元素是否属于同一个集合,或者合并两个不相交的子集。比如,
{ {1,3,5},{2},{4},{6,7} }
这整体就是一个不相交集合。里面的一些子集也是彼此互不相交的。
注意,对于每一个子集,往往用某一个元素来代表,至于用哪一个元素来表示则没有硬性要求。只要能够保证对于某一个子集中的元素查找两次它的代表,返回的值是相同的即可。还是上面的例子,
假设 1作为第一个子集的代表,find(1)、find(3)、find(5)都应该返回 1。而如果find(1)返回的是 1,find(3)返回的是 3,我们就可能认为两个元素不在同一个集合里,而事实并不是这样。
对于不相交集类,我们重点关注以下三个操作:
1.makeSet(x),建立一个新的只含有元素 x的集合。
2.union(x,y),将 x、y所在的子集(Sx和 Sy)合并成一个新的子集,并为了保证新集合的子集不相交性,消除原来集合中的 Sx和 Sy。
3.find(x),返回元素 x所在的集合的代表。
二、不相交集类的链表表示
使用链表来表示不相交集类是比较简单的。对于链表中的每一个对象,包含一个数据成员,指向所在集合的代表的指针和指向下一个节点的指针,如图 1所示。
每一个子集用一个链表表示,链表中的第一个节点代表了当前子集。另外,对于每一个链表,还设置了 head指针和 tail指针。其中, head指针指向当前子集的代表,tail指针则指向当前子集的最后一个元素,如图 2所示。
下面来分析使用这样的数据结构,其操作是如何完成的和其时间复杂度如何。
1.makeSet(x),只需要建立一个只含有元素值x的节点的链表,时间复杂度为 O(1)。
2.find(x),只需要返回其所指向的代表指针所指向的节点的数据成员即可,时间复杂度为 O(1)。
3.union(x,y),根据合并时所采用的策略,可以分为两种
3.1 将 x所在的链表合并到 y所在的链表中
此时,合并后的链表是以 y链表的第一个节点作为当前集合的代表的,这样就需要将原来 x链表的指向代表的指针都修改为指向 y链表的第一个节点,修改次数与 x链表的长度一致。如图 3所示。
假设含有 n个不相交子集的集合 S,初始状态下每个集合都只含有一个元素 xi。
第一次,执行 union(x1,x2),需要 1次操作;
第二次,执行 union(x2,x3),需要 2次操作;
......
第 i次,执行 union(xi,xi+1),需要 i次操作;
......
第 n-1次,执行 union(xn-1,xn),需要 n-1次操作;
由于总的元素子集个数只有 n个,所以 union的最大次数为 n-1。这样,对于连续 n-1次 union,总的操作次数为 1+2+...+n-1 = O(n2)。平均来看,每一次 union操作的摊还时间为 O(n)。
3.2 加权合并启发式策略——将较短的表拼到较长的表上去
仔细分析上文所述的对于含有 n个不相交子集的集合 S的合并过程,可以发现在执行 union(xi,xi+1)时,将 xi链合并到 xi+1链中,需要 i次操作,而将 xi+1链合并到 xi链中,则只需要 1次操作。那么对于连续 n-1次从 x1到 xn的union,总的操作次数只有 n-1。
这也许是合并 n个不相交子集的集合 S的最好情形,而最坏情形就是 3.1中所描述的做法。
然而实际合并时,并不总是会有包含 x1的子集,还会有其他多种情况,比如将 {x2,x3}和{x4,x5,x6}合并到一起。但是这给了我们一个启发,就是在合并时,将较短的表拼到较长的表上去,以此来减少修改指向代表的指针的次数。
对于某一个元素 x,一开始它是一个独立的子集,其代表指针指向子集。
当第一次修改它的代表指针,使它指向别的元素时,说明 {x}与其它子集合并了,此时新集合的元素个数至少是 2;
当第二次修改它的代表指针,说明与其合并的子集的元素个数至少为 2,那么此时新集合的元素个数至少是 4;
......
当第 k次修改它的代表指针,说明与其合并的子集的元素个数至少为 2k-1,那么此时新集合的元素个数至少是 2k;
由于总的元素子集个数只有 n个,所以最多修改 lgn次元素 x的代表指针。所以将 n个元素 union到一起,最坏情形下总共需要 nlgn次操作。即,其时间复杂度为 O(nlgn)。而最好情形则是本节一开始所说的 O(n)。
不过,对于链表表示,有一个很大的问题。就是以上的分析都是直接基于节点的,而不是基于节点的数据成员。比如,对于图 2中的 find(5),理论分析只需要返回它的代表指针即可;可是一开始并不能知道 5节点在哪里,还是需要先遍历当前链表,找到数据成员为 5的节点。
这样一来,时间复杂度将会增加很多,实现起来也变得麻烦了。所以这里我并没有给出链表实现的代码。(PS:这是我自己的疑问,希望各位高手能帮我解答这个疑惑,谢谢![]() )
)
三、不相交集类的根树表示
使用一棵树来表示一个子集,树的根节点可以代表当前子集,而所有子集的集合就是一个森林。而对于根树的存储结构,采用数组实现。s[i]表示元素 i的父节点。根节点令 s[i]=-1。
注意,下面这个例子以及后面的图会与测试中采用的数据和方法相一致,可以用来检测所编写程序的正确性!

图 4 含有 10个单元素子集的根树表示和存储结构
同样地,现在来考虑操作是如何完成的和其时间复杂度如何。
1.makeSet(x),令 x成为只含有根节点的树,并且令 s[x] = -1。
2.union(x,y),用根树表示的不相交子集在合并时时很容易且快速的。这里,假设 x和 y都是根节点(不是的话,可以通过find()返回其所在树的根节点)。简单的做法是将 y的父链连接到 x节点上,比如 union(6,7),图 4变成了下面图 5所示的情形.

图 5 union(6,7)
接着,union(4,5),有

图 6 union(4,5)
然后,再 union(4,6),有
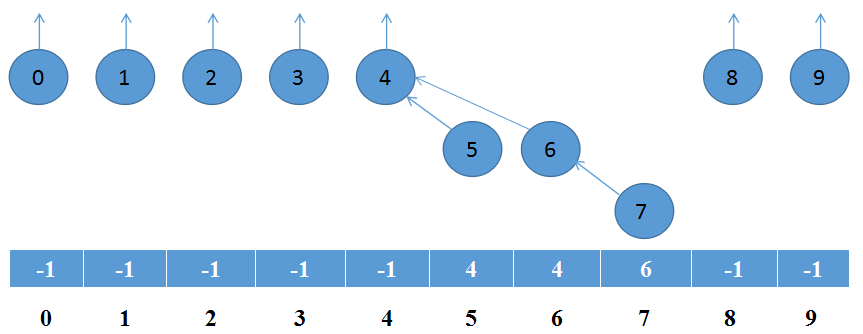
图 7 union(4,6)
可以看到,前面的合并方法是相当随意的,它通过使第二颗树成为第一颗树的子树而完成合并。这样做有一个隐患,那就是这可能会导致某些树的深度增加过大,从而增加 find()操作的时间复杂度。
这里,采用两种灵巧求并算法来完成合并操作。
2.1 按大小求并
合并的时候先检查树的大小,使较小的树成为较大的数的子树。这样的话,需要在根节点处记录每一颗树的大小。由于已经令根节点的 s[i]=-1了,这里,可以直接用根节点的 s[i]存储树的大小。而当按大小合并时,将较小树的大小加到较大树上去,并且令较小树的父链指向较大树的根节点。
下图比较了再执行 union(3,4)时随意合并与按大小求并的结果有何不同。
 和
和
图 8 使第二颗树成为第一颗树的子树而完成合并 图 9 按大小求并
2.2 按高度(秩)求并
按高度求并可以看做是按大小求并的简单修改,因为对于根树结构,节点个数多并不意味着高度就越大。对于以下两棵树而言,使用按高度求并得到的结果深度更小。
 和
和 ;按大小求并,有
;按大小求并,有 ;按高度求并,有
;按高度求并,有
图 10 按大小合并与按高度合并的区别
同样地,在合并两颗树时,将高度较小的树合并到高度较大的树中。只有在两颗子树的高度相同时,新树的高度才会增加 1。同样地,此时根节点的 s[i]存储的是树的高度。当树中只有一个根节点时,s[i]=-1;而当树的高度增 1的时候,使用 --操作符,因为此时采用的是树的高度的相反数。
使用按高度求并,执行 union(3,4),有

图 11 union(4,6)
3.find(x),寻找节点 x所在的树的根节点。一般来说,不停地通过父链向上寻找,就可以找到 x所在的树的根节点。这里,可以进行一些改进,在执行 find(x)的过程中同时实现路径压缩。即从 x到根节点的路径上的每一个节点都使它的父节点变成根。
如对上图执行完 find(7)后,有

图 12 执行完 find(7)后的不相交集和
可以看到,此时树的高度有所下降。另外,对于数组中 s[4]=-3,这里采用的是上图中的按高度求并。你也许可能会有疑问说,此时节点 4的高度为 2,为什么 s[4]=-3?接下来就来回答这个问题。
在随意执行 union操作时,单单使用路径压缩,连续 M次操作最多需要 O(MlgN)的时间。
路径压缩与按大小求并是完全兼容的,这就使得两个例程可以同时实现。时间复杂度如何?
而按高度求并不完全与路径压缩兼容,因为路径压缩会改变树的高度,而计算新的高度并不容易。怎么办呢?做法就是不计算,仍旧存储没有实行路径压缩之前的高度。注意,这个高度并不是树的真实高度,而是一个估计高度,称为秩。
按秩求并和路径压缩单独实行也能改善运行时间,但一起使用可以大幅度改善运行时间。最坏运行时间为 O(mα(n)),其中α(n)是一个增长极其缓慢的函数,在大多数不相交集的应用中,都会有 α(n)≤4。因此这个运行时间接近于 O(m)。
四、不相交集类的根树实现
完整的 C++代码及测试代码如下,这里的 unionSets操作分别采用了任意合并、按大小求并和按高度求并三种方式,而 find操作则使用了简单查找(没有任何额外操作)和路径压缩两种方式。


1 /* 2 * DisjSets.h文件,DisjSets类的声明部分 3 * 1.注意,这里实现的不相交集类是采用根树表示、数组存储的,这就带来一个问题,对于一个节点值为 x的根节点, 4 * 有 s[x]=-1。可如果数据只有 1,2,100这 3个数,却需要建立一个长度为 101的数组,是不是有些浪费了呢? 5 * 2.unionSets操作分别采用了任意合并、按大小求并和按高度求并三种方式,而 find操作则使用了简单查找(没有任何额外操作)和路径压缩两种方式。 6 * @author 塔奇克马 @data 2016.08.08 7 */ 8 9 #pragma once 10 #include <vector> 11 using namespace std; 12 13 class DisjSets 14 { 15 public: 16 explicit DisjSets(int maxNum); 17 ~DisjSets(); 18 19 // 简单查找,没有像路径压缩之类的额外操作 20 int find(int x) const; 21 // 使用了路径压缩的查找操作 22 int findWithPassCompression(int x); 23 // 一般形式的查找操作,flag为 false,使用简单查找;反之则使用了路径压缩 24 int find(int x, bool flag); 25 // 任意合并,将 y树作为 x的子树完成合并 26 void unionSets(int x, int y, bool flag = true); 27 // 按大小求并 28 void unionSetsBySize(int x, int y, bool flag = true); 29 // 按高度求并 30 void unionSetsByHeight(int x, int y, bool flag = true); 31 // 按类打印出整个不相交集合 32 void print() const; 33 private: 34 // 打印出根节点为 x的整个树 35 void print(int x) const; 36 vector<int> s; // 存储整个不相交集 37 };
1 // DisjSets.cpp文件,DisjSets类的实现部分 2 3 #include "iostream" 4 #include "DisjSets.h" 5 using namespace std; 6 7 DisjSets::DisjSets(int maxNum):s(maxNum) 8 { 9 for (int i=0; i<maxNum; i++) 10 { 11 s[i] = -1; 12 } 13 } 14 15 DisjSets::~DisjSets() 16 { 17 18 } 19 20 21 // 简单查找,没有像路径压缩之类的额外操作 22 int DisjSets::find(int x) const 23 { 24 if (s[x] < 0) 25 return x; 26 else 27 return find( s[x] ); 28 } 29 30 // 使用了路径压缩的查找操作 31 int DisjSets::findWithPassCompression(int x) 32 { 33 if (s[x] < 0) 34 return x; 35 else 36 return s[x] = find( s[x] ); 37 } 38 39 // 一般形式的查找操作,flag为 false,使用简单查找;反之则使用了路径压缩 40 int DisjSets::find(int x, bool flag) 41 { 42 if (!flag) 43 return find(x); 44 else 45 return findWithPassCompression(x); 46 } 47 48 // 任意合并,将 y树作为 x的子树完成合并 49 void DisjSets::unionSets(int x, int y, bool flag) 50 { 51 x = find(x,flag); y = find(y,flag); 52 s[y] = x; 53 } 54 55 // 按大小求并 56 void DisjSets::unionSetsBySize(int x, int y, bool flag) 57 { 58 x = find(x,flag); y = find(y,flag); 59 if ( s[x] <= s[y] ) // x树更大,令 y树成为 x的子树 60 { 61 s[x] += s[y]; 62 s[y] = x; 63 } 64 else 65 { 66 s[y] += s[x]; 67 s[x] = y; 68 } 69 } 70 71 // 按高度求并 72 void DisjSets::unionSetsByHeight(int x, int y, bool flag) 73 { 74 x = find(x,flag); y = find(y,flag); 75 if ( s[x] > s[y] ) // y树更深,令 x树成为 y的子树 76 s[x] = y; 77 else 78 { 79 if ( s[x] == s[y] ) 80 s[x]--; 81 s[y] = x; 82 } 83 } 84 85 // 按类打印出整个不相交集合 86 void DisjSets::print() const 87 { 88 cout<<"整个不相交集的全部元素为: "<<endl; 89 for (unsigned int i=0; i<s.size(); i++) 90 cout<<i<<" "; 91 cout<<endl; 92 int numOfChildSets = 0; 93 for (unsigned int i=0; i<s.size(); i++) 94 { 95 if ( s[i] < 0 ) 96 { 97 cout<<"第 "<<++numOfChildSets<<"个子集: "; 98 print( i ); 99 cout<<endl; 100 } 101 } 102 cout<<"总共有 "<<numOfChildSets<<"个子集"<<endl; 103 cout<<"s中的元素值:"<<endl; 104 for (unsigned int i=0; i<s.size(); i++) 105 cout<<s[i]<<" "; 106 cout<<endl; 107 } 108 109 // 打印出根节点为 x的整个树 110 void DisjSets::print(int x) const 111 { 112 cout<<x<<" "; 113 for (unsigned int j=0; j<s.size(); j++) 114 { 115 if ( x == s[j] ) 116 print(j); 117 } 118 }
1 #include "iostream" 2 #include "DisjSets.h" 3 using namespace std; 4 5 void main() 6 { 7 DisjSets disjSets(10); 8 disjSets.print(); 9 10 ////////////随意合并////////////////// 11 disjSets.unionSets(6, 7, false); 12 disjSets.unionSets(4, 5, false); 13 disjSets.unionSets(4, 6, false); 14 disjSets.unionSets(3, 4, false); 15 disjSets.print(); 16 17 //////////////按大小合并////////////////// 18 disjSets.unionSetsBySize(6, 7, false); 19 disjSets.unionSetsBySize(4, 5, false); 20 disjSets.unionSetsBySize(4, 6, false); 21 disjSets.unionSetsBySize(3, 4, false); 22 disjSets.print(); 23 24 ////////////按高度合并////////////////// 25 disjSets.unionSetsByHeight(6, 7, false); 26 disjSets.unionSetsByHeight(4, 5, false); 27 disjSets.unionSetsByHeight(4, 6, false); 28 disjSets.unionSetsByHeight(3, 4, false); 29 disjSets.print(); 30 31 disjSets.findWithPassCompression(7); 32 disjSets.print(); 33 34 system("pause"); 35 }
下面是测试代码的输出结果:
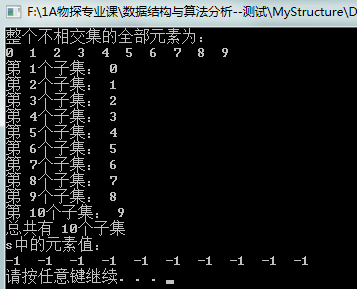 与图 4结果一致
与图 4结果一致  与图 8结果一致
与图 8结果一致  与图 9结果一致
与图 9结果一致  与图 11结果一致
与图 11结果一致  与图 12结果一致
与图 12结果一致
总的来说,不相交集类是一种很有意思的数据结构。它实现起来简单、快速,但其时间复杂度的分析却相当困难。我看到《算法导论》和《数据结构与算法分析C++描述》中关于它的分析都很复杂,并且有些地方的结论也不太相同。所以,这里我也不敢乱言。
对了,不相交集类可以用来生成迷宫,确定无向图中连通子图的个数等。