5.1,干掉 active namenode, 看看集群有什么变化
5.2,干掉 active resourcemanager, 看看集群有什么变化
正文
一,前言
在hadoop中的HDFS和yarn都存在单点故障问题,例如当namenode宕机或者断电后,整个集群就会停止提供服务,为了解决这个问题我们可以引入两个namenode(一个提供服务(active),一个当做备用(standby)),当提供服务的namenode出现故障宕机后,会自动切换到备用的namenode进行服务提供,这就是所以说的高可用。同理yarn中的resoucemanager也是一样的。而其中namenode的主备切换是相对来说比较麻烦的,因为这之中有状态和数据的操作问题,所以会依赖一些其他的服务,接下来就对其细说,同时,搭建一个高可用的hadoop集群。
二,集群准备工作
2.1 HA集群基础架构
下图是HDFS的HA基础架构:
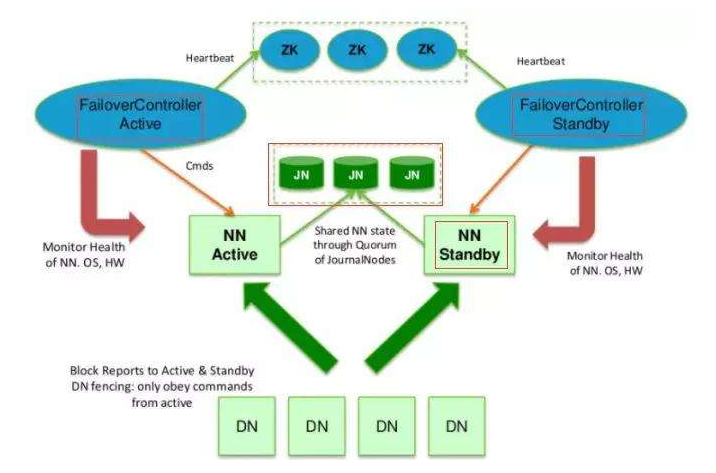
上诉架构图对应着hadoop的一些进程如下:
DFSZKFailover controller:对应上图的(Failover controller)作用就是监控namenode是否能够正常服务,如果不行就进行备用namenode的切换。该服务都需要依赖Zookeeper。
QuorumPeerMain:该进程是zookeeper的主进程,用于(Failover controller)的监听工作。
JournalNode:该进程对应上图的JN,作用是用于主备操作文件edit.log的同步,每一次对HDFS的文件操作,除了会在namenode中生成edit的操作文件,还会在JN上生成一个同样的文件。而stanby的namenode就从JN中读取edit文件,从而达到主备namenode数据同步的效果。
namenode:NN
datanode:DN
对于YARN的HA架构比较容易,只需进行配置文件简单配置,开启两个resourcemanager即可。
2.2 集群规划

2.3 文件下载
hadoop下载:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
zookeeper下载:http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
JDK下载:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2.4 集群的免密配置
第一步:所有服务器执行
ssh-keygen
执行后会在当前用户的家目录下生成.ssh的隐藏目录,进入改目录会看到如下文件:
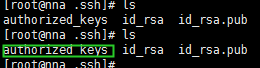
标绿色的是我们自己创建的文件,该文件保存了我们需要远程访问的公钥。即id_rsa.pub文件内容。所以我们只需要把其他4台服务器产生的公钥的内容追加到改文件即可,然后将该文件复制到每一台机器上,这样就可以来这些机器上自由的免密登入了。
三,集群安装
3.1 环境变量配置
所以服务器需要安装:hadoop,JDK
ha3,ha4,ha5:安装zookeeper
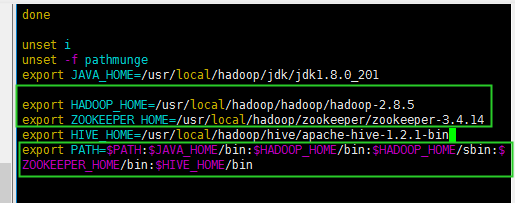
在安装前将下载的hadoop,JDK,zookeeper安装包解药到指定的目录,然后将三者的bin文件目录添加到环境变量中。
下面是我下载解压的目录:
所以环境变量配置如下:
3.2,hadoop配置
3.2.1 core-site.xml(ha1)
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://haserver/</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>ha3:2181,ha4:2181,ha5:2181</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/hadoop/tmp</value> </property> </configuration>
3.2.2 hdfs-site.xml(ha1)
<configuration> <!--指定hdfs的nameservice为bi,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>haserver</value> </property> <!-- hdp24下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.haserver</name> <value>namenode1,namenode2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.haserver.namenode1</name> <value>ha1:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.haserver.namenode1</name> <value>ha1:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.haserver.namenode2</name> <value>ha2:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.haserver.namenode2</name> <value>ha2:50070</value> </property> <!-- 指定NameNode的edits元数据在机器本地磁盘的存放位置 --> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/hadoop/hdpdata/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/hadoop/hdpdata/datanode</value> </property> <!-- 指定NameNode的共享edits元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://ha3:8485;ha4:8485;ha5:8485/haserver</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/hadoop/hadoop/hdpdata/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.haserver</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>
3.2.3 yarn-site.xml(ha1)
<configuration> <!-- Site specific YARN configuration properties --> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!-- 指定RM的逻辑名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>ha1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>ha2</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>ha3:2181,ha4:2181,ha5:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1024</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value> </property> </configuration>
3.2.4 mapre-site.xml(ha1)
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
3.3,配置slaves文件(ha1)
该文件就是告知服务器在那几台启动datanode和nodemanager
ha3
ha4
ha5
3.4,zookeeper配置(ha3)
3.5,复制配置文件到相应节点
上述配置文件配置完毕后,将core-site.xml,hdfs-site.xml,yarn-site.xml,slaves,mapre-site.xml远程复制到ha2,ha3,ha4,ha5
scp core-site.xml hdfs-sit.xml yarn-site.xml slaves mapre-site.xml ha2:$PWD scp core-site.xml hdfs-sit.xml yarn-site.xml slaves mapre-site.xml ha3:$PWD scp core-site.xml hdfs-sit.xml yarn-site.xml slaves mapre-site.xml ha4:$PWD scp core-site.xml hdfs-sit.xml yarn-site.xml slaves mapre-site.xml ha5:$PWD
将zoo.cfg文件复制到ha4,ha5
scp zoo.cfg ha4:$PWD scp zoo.cfg ha5:$PWD
四,启动集群
4.1,启动zookeeper
在前面自己写过一个zookeeper启动脚本如下:
#!/bin/bash for host in ha3 ha4 ha5 do echo "${host}:starting..." ssh $host "source /etc/profile; /usr/local/hadoop/zookeeper/zookeeper-3.4.14/bin/zkServer.sh start" done sleep2 for host in ha3 ha4 ha5 do ssh $host "source /etc/profile; /usr/local/hadoop/zookeeper/zookeeper-3.4.14/bin/zkServer.sh status" done
执行该脚本进行启动:
zkStart_all.sh
4.2,启动Journernode
在ha3,ha4,ha5中启动Journernode
hadoop-daemon.sh start journalnode
4.3,启动HDFS
第一步:初始化namenode
hdfs namenode -format # 在ha1进行初始化
初始化后会在产生namenode的数据目录,该目录在配置文件已经配置,将数据目录复制到第二个namenode上:
我这里配置的数据目录是:/usr/local/hadoop/hadoop/hdpdata/namenode,所以执行如下命令:
cd /usr/local/hadoop/hadoop scp -r hdpdata ha2:$PWD
第二步:格式ZKFC
在ha1上执行就可以:
hdfs zkfc -formatZK
第三步:启动HDFS
# ha1上启动
start-dfs.sh
4.4,启动yarn
# ha1上启动
start-yarn.sh
# 启动后发现只有一个resourcemanager,另一个需要我们自己手动启动
# ha2 启动
yarn-deamon.sh start resourcemanager
4.5,查看各主节点的状态
在各个服务器上执行jps查看服务是否启动成功:
下面我我搭建的状态各个服务器的进程:

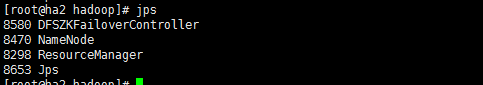



五,集群性能测试
5.1,干掉 active namenode, 看看集群有什么变化
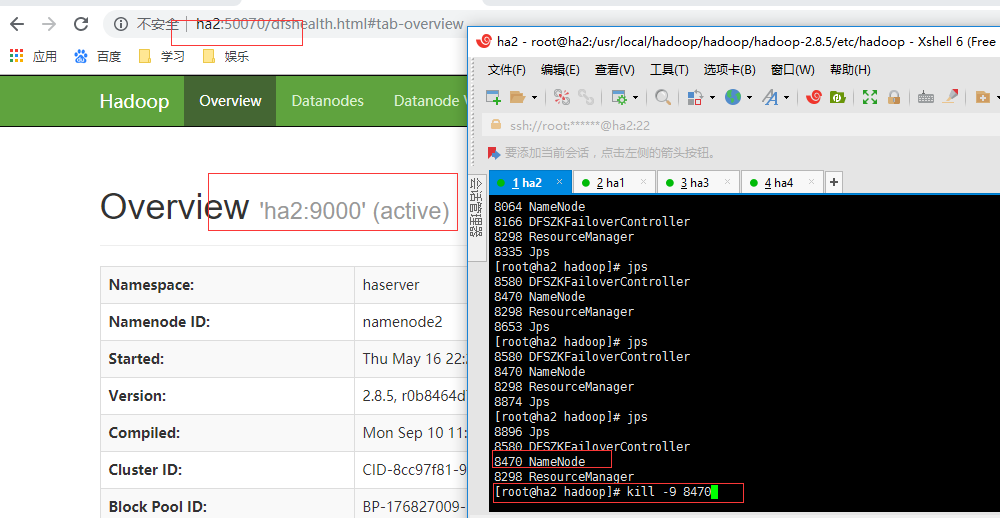
ha1开始为standby状态即:备用的namenode,ha2为active状态:正在服务的namenode,关闭ha2进程,ha1会切换到active状态,如下所示:
起始状态:ha1

起始状态ha2:
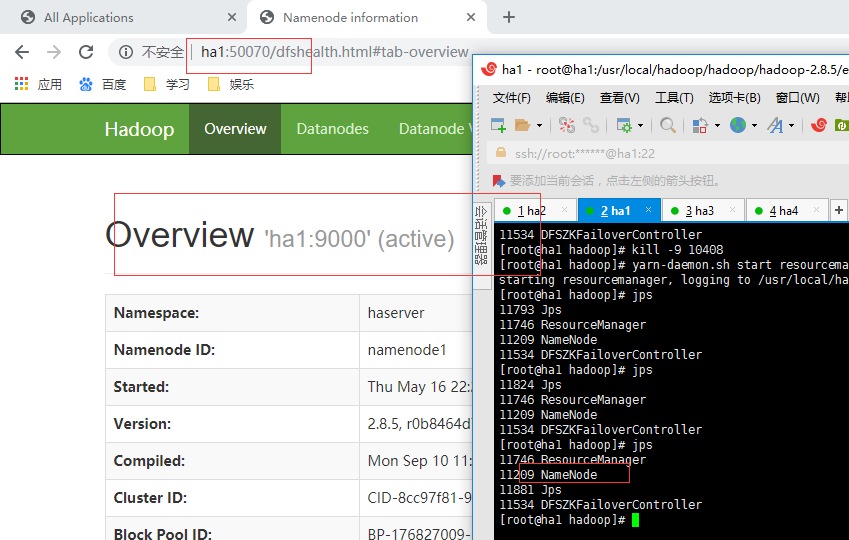
当ha2宕机后,ha1状态:
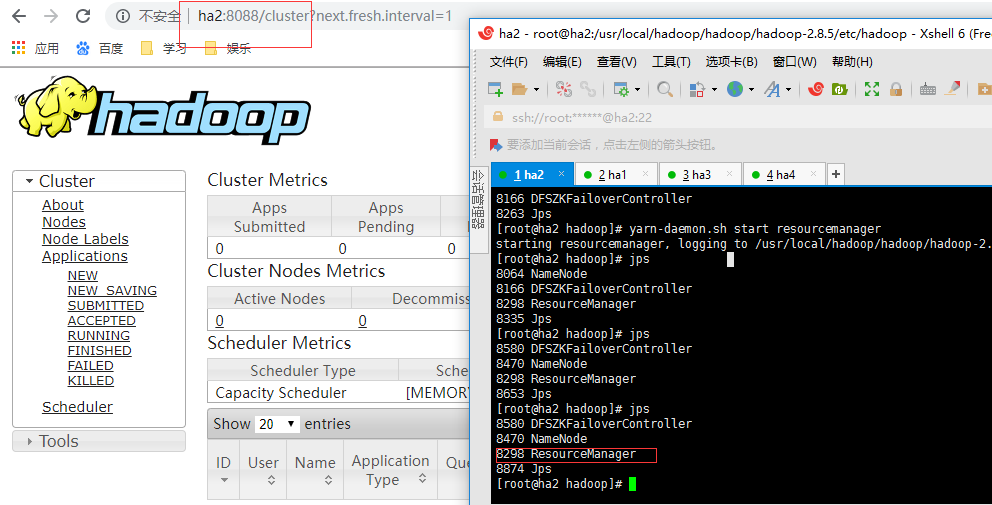
5.2,干掉 active resourcemanager, 看看集群有什么变化
我们在ha1和ha2上启动了resourcemanager,访问ha1:8088端口如下:
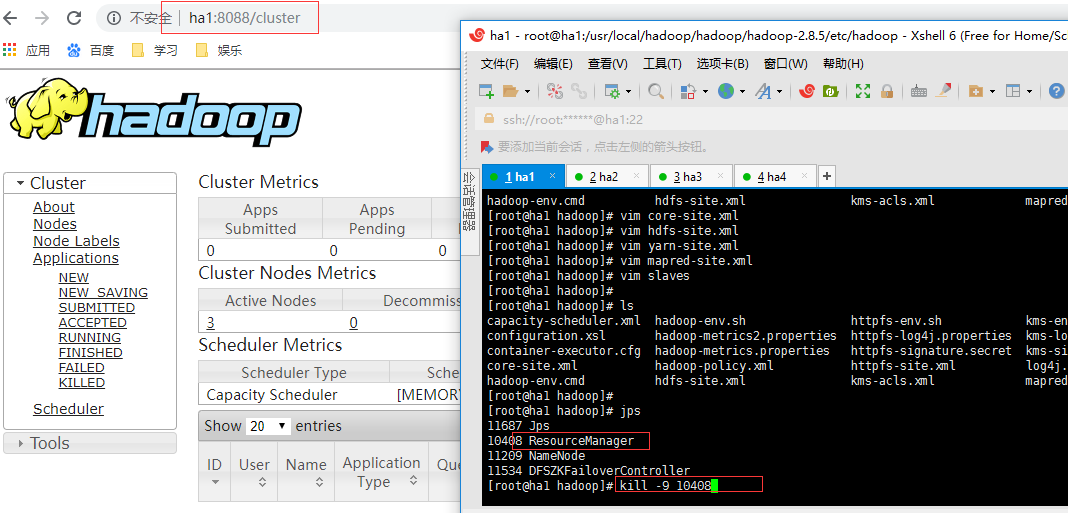
如果你直接访问ha2的8088端口,它会进行重定向到ha1的8088端口,当我们关不ha1的resourceManager进程时,再访问ha2的8088就可以正常访问了: