一,简介
二,角色介绍
三,启动流程图
正文
一,简介
Standalone模式下,集群启动时包括Master与Worker,其中Master负责接收客户端提交的作业,管理Worker。提供了Web展示集群与作业信息。
二,角色介绍
Client(SparkSubmit):客户端进程,负责提交作业到Master。
Master:Standalone模式中主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
Worker:Standalone模式中slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
Driver: 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
Executor:即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task
三,启动流程图
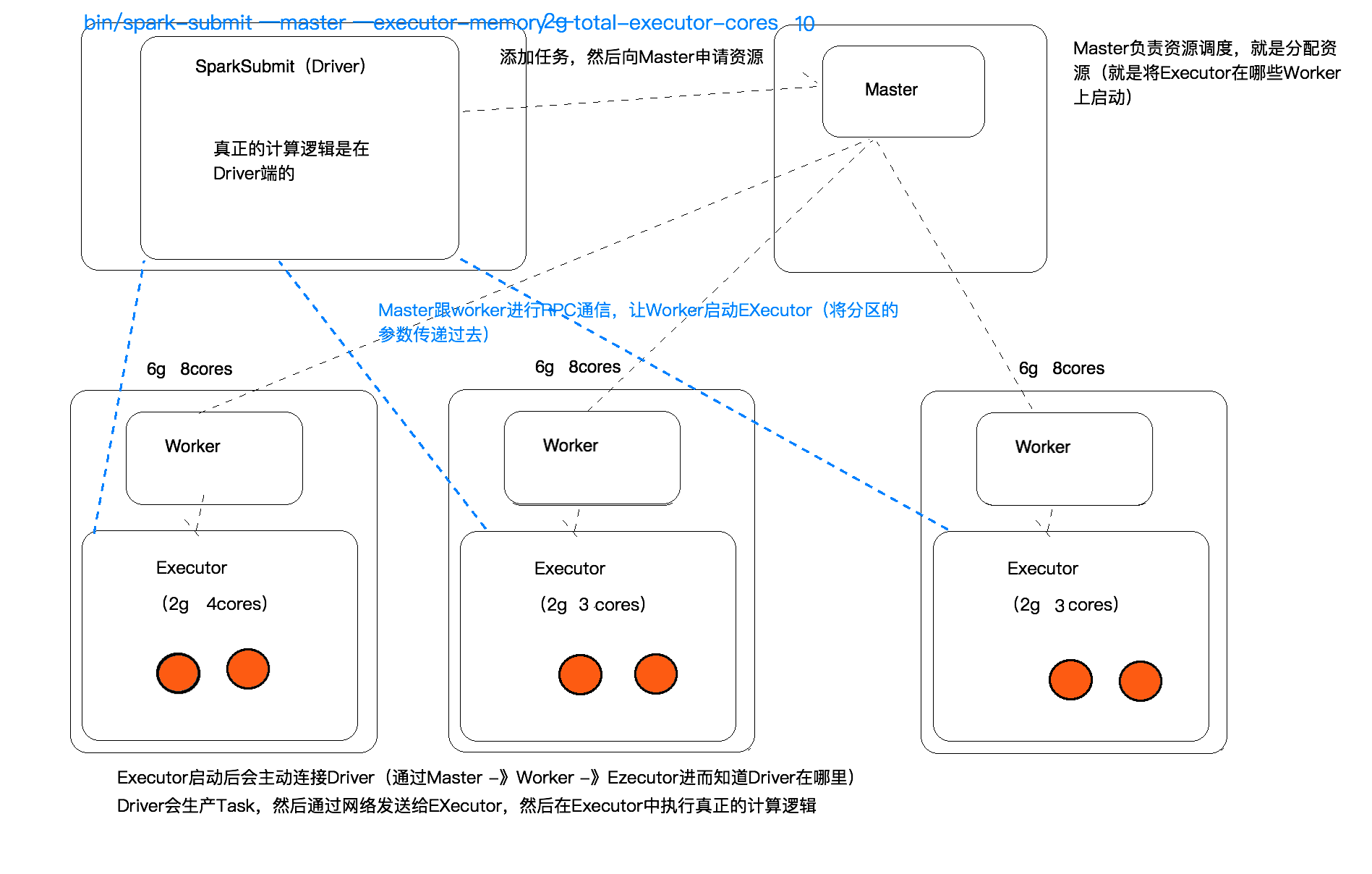
流程介绍
Standalone模式下Spark启动流程:
1. Spark程序启动后,会先后进行Master和Worker的启动,两者启动完毕,他们之间就会进行通信。
2. Worker会携带自己能够提供的资源(如CPU,内存等)向Master注册自己,告知Master我有多少资源可以提供。
3. Master接收到后会保存这些信息,以供日后任务运行时进行调度,在高可用的情况下这些信息是保存在Zookeeper上。
4. Worker注册完毕后接收到注册成功通知,而会一直和Master发送心跳,在高可用情况下,和Zookeeper发送心跳。告知该Worker可以正常提供服务。
5. 如Master发现有一端时间Worker,没有发送心跳,就会知道该Worker已经失效,在后续分配计算任务的时候就不会分配到该Worker中。
任务提交流程:
1. Client(SparkSubmit)提交任务到master。
2. master接收到任务后就会为这个任务分配资源,也就是在那些Worker来启动(Executor)。会把这些信息返回给Driver
3. Driver接收到信息后,就会参数Task,然后将这些task通过网络的方式传输到各Worke的Executor进行计算。
4. Exector运行完毕后就会释放资源。