相关参考链接当时没保存,现在找不到了,如有冒犯请告知,侵删。
一些基于VesPA,WPAL的行人属性识别方法。 PA-100K和RAP用于训练。
关于行人属性的开源代码资源,主要就 Weakly-supervised Learning of Mid-level Features for Pedestrian Attribute Recognition and Localization 的开源进行了相关的测试和拓展,利用RAP数据集以及PA-100K数据集进行训练和测试。另外 Adaptively Weighted Multi-task Deep Network for Person Attribute Classification 提供了不完整且仅针对人脸属性的代码,并且没有相应的文档说明。
数据集方面比较著名的是RAP数据集和PETA数据集,PA-100K克服了前两个数据集中一些数据采集和分配方面的缺点,但是只进行了26个属性的标注。
相关论文可以参考的部分
1.Adaptively Weighted Multi-task Deep Network for Person Attribute Classification
这篇论文的测试主要基于人脸属性数据集和冷门的行人属性数据集,所以测试结果可参考性不大,但其提出的动态调整loss权重的训练算法感觉可以用在其他地方,辅助提升属性识别效果
2.HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
https://github.com/xh-liu/HydraPlus-Net 作者放出来了caffe版本的
作者提出的方法是通过提取不同位置的特征,即从局部到整体多个角度进行提取,来解决属性识别的问题。同时,还需要从不同的特征层次进行提取,如衣服条纹用浅层特征,但是头发长度则需要相对高层的语意特征。

一张图片首先在M-net的3个block产生3个输出,这三个输出再分别用一层1 * 1 * L的卷积层调整到channel为L,然用基于元素与一个矩阵相乘,分别输入到AF-net中的3个block。M-net输出的3种不同的featuremap决定了feature level,而channel决定了location。
训练过程是分阶段训练. 首先训练M-net,并复制其参数到3条AF-net分支上,再分别训练3条AF-net分支。之后固定前面的网络,训练池化层和全连接层。
Weakly-supervised Learning of Mid-。。。
其mA指标在RAP数据集中效果较好,但是基于example的一组指标却表现不甚理想。奇怪的是,我用其他方式进行数据预处理后,这组指标出现显著提升,怀疑先前通过简单的padding对每个图片补足到与所在batch同样size的预处理方式对最终效果产生了很大的影响。
本篇工作提出的想法是,如果行人属性每次的位置不统一的话,那么就难以通过直接输入全幅图像的方式识别属性。所以,论文提出了一种基于弱监督方式并且能够检测属性位置的网络,这样如果某个属性被检测出来出现在图像上,那么与该属性相关的其他属性就更可能被识别出来。比如如果检测网络检测到长发的话,那么女性这个相关的属性就更可能会被识别出来。这里体现了属性定位和属性相关性的思想。
本篇提出的架构与HydraPlus-Net中的架构有些相似,可以说是三条分支简化版本的HP-net。不同点在于分支后面的网络设计,这里采用了FSPP,一种特殊的池化层去定位属性的大概位置。
本篇工作主要针对现在存在的三个问题:
-
细粒度的属性会因为多层的卷积层和池化层的处理,被忽视掉。
-
同一个属性相对于人的相对位置可能不一致,比如一个包可能在肩上也可能在膝盖附近。
-
以往的训练都是用人工标注数据进行训练,默认行人在行人框的中心位置,相当于已经默认了行人的分布。但如果要用检测器进行自动化行人属性识别,则行人可能不在行人框的中心位置,行人的分布将是不统一的。
GoogLeNet(Inception V3)简介
获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),但是这种情况下会出现如下的缺陷:
1.参数太多,若训练数据集有限,容易过拟合;
2.网络越大计算复杂度越大,难以应用;
3.网络越深,梯度越往后穿越容易消失,难以优化模型。
解决上述缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。为了打破网络对称性和提高
学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,
所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。现在的问题是有没有一种方法,
既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏结。
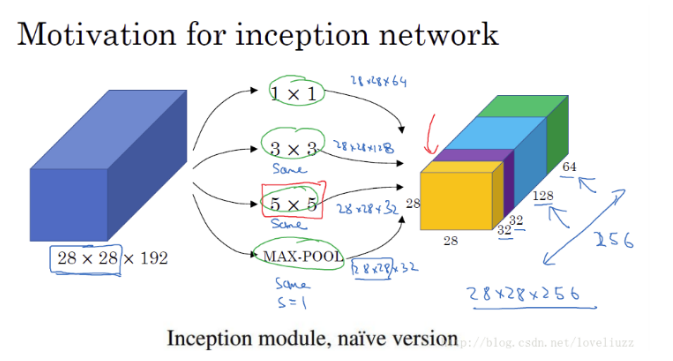
上图:
1.采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2.之所以卷积核大小采用11、33和5*5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding =0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
-
文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
-
网络越到后面特征越抽象,且每个特征涉及的感受野也更大,随着层数的增加,3x3和5x5卷积的比例也要增加
Inception的作用
代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层,即:不需要人为的决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数。
naive版本的Inception网络的缺陷:计算成本。使用5x5的卷积核仍然会带来巨大的计算量,约需要1.2亿次的计算量。(28×28×192×32×5×5=120422400)

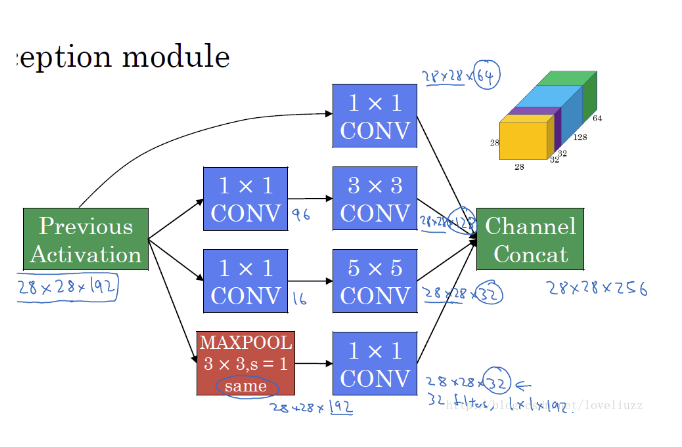
为了减少计算成本,采用1×1卷积核进行降维:
在3x3和5x5的过滤器前面,max pooling后分别加上了1x1的卷积核,最后将它们全部以通道/厚度为轴拼接起来,最终输出大小为2828256,卷积的参数数量比原来减少了4倍,得到最终版本的Inception模块为:
googLeNet——Inception V1结构
googlenet的主要思想就是围绕这两个思路去做的:
(1)深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
(2)宽度,增加了多种核 1x1,3x3,5x5,还有直接max pooling的,但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。
对Inception V1做如下说明: (1)显然GoogLeNet采用了Inception模块化(9个)的结构,共22层,方便增添和修改; (2)网络最后采用了average pooling来代替全连接层,想法来自NIN,参数量仅为AlexNet的1/12,性能优于AlexNet,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便finetune; (3)虽然移除了全连接,但是网络中依然使用了Dropout ; (4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
(5)上述的GoogLeNet的版本成它使用的Inception V1结构。
Inception V2结构:
大尺寸的卷积核可以带来更大的感受野,也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,这便是Inception V2结构,保持感受野范围的同时又减少了参数量,如下图:

Inception V3结构:
大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。文章考虑了 nx1 卷积核