使用默认参数创建的虚拟机,虚拟机的VCPU在物理CPU不同核心之间动态调度,另外,由于Linux还可能会将软中断,内存交换等进程调度到虚拟机正在使用的物理核心上,这些因素导致这些虚拟机相对于物理机的计算性能可能会产生较大的抖动,不能满足一些对计算SLA要求很严格的业务,比如,很多金融业务就要求99.999%的请求处理时间延时不得高于1毫秒。
高性能虚拟机
为了减少 Linux 和 Hypervisor 对虚拟机的影响,让虚拟机的性能接近物理机,一般可以采用如下优化手段:
1.CPU 绑核(pin):将虚拟 CPU 和物理 CPU 逐一绑定起来,这样不同虚拟机的VCPU各自运行在不同的物理核心上,不会相互影响。
2.CPU隔离(isolate):将虚拟机使用的物理 CPU 从 Linux 隔离出来,Linux Kernel 不再调度任何应用甚至是任何系统进程到这些 CPU 上,尽量让这些CPU 100%为虚拟机使用。
3.CPU拓扑(Topology): CPU 分配尽量不要跨 NUMA ,如果必须要跨NUMA,将 NUMA 拓扑结构呈现给 Guest OS ,同时也把 SMT 拓扑结构呈现给 Guest OS 。
OpenStack 环境
1.OpenStack Mitaka:Mitaka 现在运行的很好, 新版本的 Cell 机制甚至会导致一些不可预料的结果,我们一直没有冒险去做升级投入。
2.CentOS 7.3:OpenStack Mitaka 在 CentOS 7.4 的 repo 里面已经找不到了,应该是停止支持了,由于担心一些不必要的包依赖问题,我们继续使用 CentOS 7.3 。
3.QEMU: CentOS 7默认的qemu 1.5版本非常老,会导致compute节点的resource_tracker不能上报numa_topology到controller节点,导致NUMATopologyFilter无法调度,所以必须升级到2.6。

升级qemu到2.6
计算节点配置
使用numactl查看下主机的numa拓扑结构,比如下面的输出说明 cpu 0-3 在一个numa node上,而 cpu 4-7 在另一个 numa node 上:
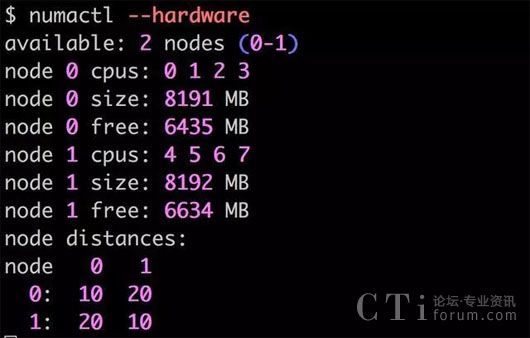
numactl --hardware
比如,我们希望将2,3, 6,7隔离出来,专门给虚拟机用,尽量让Linux不要将任何用户进程和系统进程调度到这些cpu上。
首先,编辑/etc/nova/nova.conf, 配置这台主机能用来创建VM的cpu为2,3,6,7:
vcpu_pin_set=2,3,6,7
然后,编辑/boot/grub/grub.conf:

grub.conf
1.isolcpus:不要将任何应用和系统进程(softirq, swap.……)调度到指定的CPU上;
2.nohzfull: 指定的CPU上没有时钟中断;
3.rcunocbs:不要在指定的CPU上调度执行rcb callbacks;
最后,重启主机生效。
控制节点配置
修改/etc/nova/nova.conf, 将调度过滤器NUMATopologyFilter加入到scheduler_default_filters:
scheduler_default_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,CoreFilter,NUMATopologyFilter
然后,重启nova-scheduler服务
systemctl restart openstack-nova-scheduler.service
创建支持cpu pin的flavor:
openstack flavor set m1.large --property hw:cpu_policy=dedicated --property hw:cpu_thread_policy=require
CPU-POLICY :
1.shared: (默认)VCPU会在PCPU上任意漂移;
2.dedicated: VCPU会绑定在指定的PCPU上;
3.CPU-THREAD-POLICY :
4.prefer: (默认) VCPU会优先选择同一核心上的超线程。
5.isolate: VCPU会选用不同核心的超线程。
6.require: VCPU优先选择同一核心上的超线程,如果主机的BIOS超线程没有开启,就会报告失败。
除了hw:cpu_policy和hw:cpu_thread_policy,这里还可以定义hw:numa_nodes,hw:numa_cpus.N,hw:numa_mem.N等NUMA策略。
用指定的flavor创建虚拟机:
openstack server create --image cirros --nic net-id=provider-net --flavor m1.large instance-001
验证
在计算节点上使用virsh dumpxml domID观察虚拟机,输出的xml应该包括类似下面的内容:

virsh dumpxml