1、数据库种类
关系型数据库:常见的Mysql,Oracle,PostgreSql
k-v数据库:常见的Redis,C
列式数据库:Hbase,Cassandra
文档型数据库:MongoDB,CouchDB
图形数据库:Neo4j,GraphSql
newSql: Oceanbase,TIDB
redis是由C语言编写,作为k-v型数据库,基于内存操作,也可以持久化,有着非常高的处理性能。
redis命令参考网站:http://doc.redisfans.com/
redis版本6.0
2、redis数据类型
1》String(字符串)
2》Hash(哈希表
3》List(有序且可重复集合)
4》Set(无序且补课重复集合)
5》zSet(有序且补课重复集合)
6》HyperLogLog(基数)
7》Streams(流信息)
8》Geospatial(地理位置计算)
9》Bit Arrays(位集合)
3、String类型
常用命令:
set key value [ex seconds] ... 对key设置value值
get key 获取指定key的value值
del key [key ...] 删除指定key
mset key value [key value ...] 批量设置值
mget key [key ...] 批量获取值
incr key 对指定的key对应的value值进行原子递增(value必须是int类型,可以做分布式id)
decr key 对指定的key对应的value值进行原子递减
setex key value(second) 设置指定key的过期时间,单位为秒
setnx 将key的值设置为value,如果key存在,返回0不做任何处理,否则返回(可以做分布式锁)
getset 将指定key的值设置为value,并返回key修改之前的值
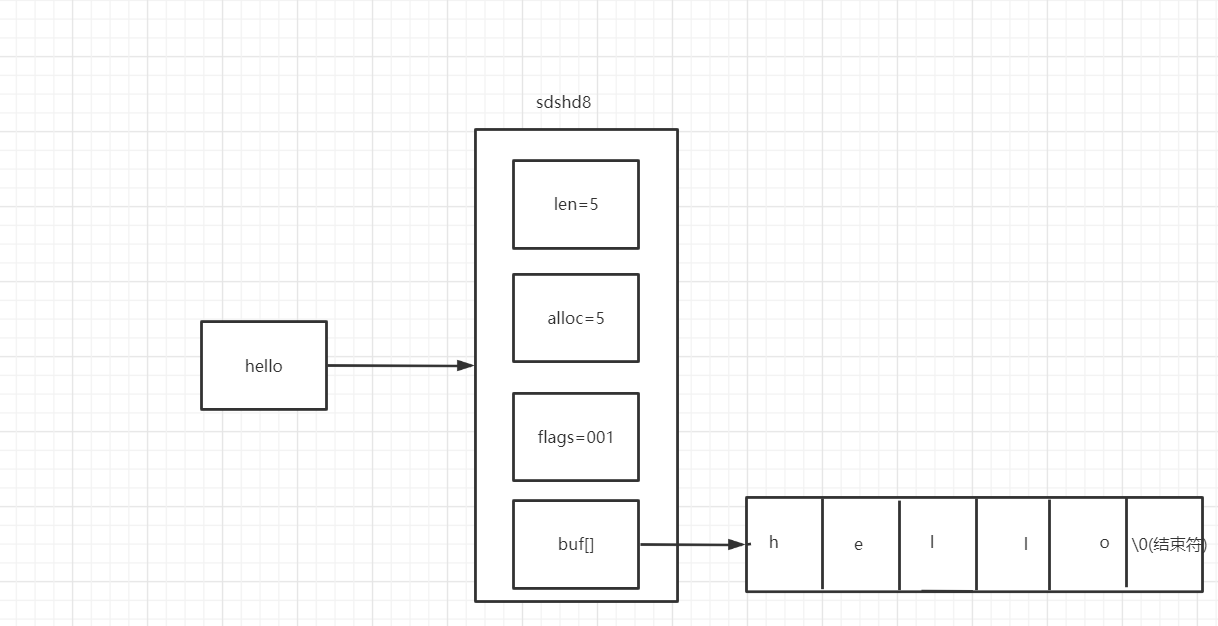
在C语言中没有String的类型,它在c语言中的数据结构存储:是使用SDS动态类型的一个储存,根据字符串的长度,来选择不同的SDS结构:
比如:set name 'hello' 选择的是sdshd8的一个结构存储:
String类型作为最常用的一种,主要应用场景有:
1、应用缓存,例如把字典数据,常用的城市数据,存储在redis中
2、分布式id,可以利用incr命令,实现原子递增操作

3、分布式session,让多个应用把seeeion存储在redis中,这样可以避免像session复制这样性能损耗的操作
4、限流或计算器等,例如验证码的获取次数,密码的错误次数等。
........
key命名规范:
1、不要太长,占用内存和宽带,例如当一个值有1024byte,这时候建议采用hash值,例如使用SHA1
2、不要太短,没有意义的缩写,例如:user:1000:followers缩写成u1000flw,见名知意。
建议格式:object-type:id,中间用::分割,例如:user:1000,comment:1234:reply-to
3、最大的key值为512M
4、hash
常用命令:
HSET key field value 将Hash表key中field字段的值设置为value,如果key不存在,则创建一个新的hash表,否则夏盖field的值
HGET key field 返回Hash表key中指定field字段的值
HDEL key field [field ...] 删除Hash表Key中一个或者多个field,如果不存在,则直接忽略
HEXISTS key field 查看Hash表key中,指定field是否存在,存在返回1,否则返回0
HGETALL key 返回Hash表key中所有的fheld和value
HKEYS key 返回Hash表key中所有的field
HLEN key 返回Hash表key中field的数量
HVALS key 返回Hash表key中所有的field的value
HMGET key field [feld ..] 返回Hash表Key中,-个或多个指定field的值
HMSET key feld value [feld value ..] 同时将多个field-value设置到Hash表指定的key中,如果存在field,则爱盖。如果key不存在,则创建一个新的Hash表
hash结构更适合存储对象数据,例如:存储用户信息

当然也可以用String类型来存储,但如果我们需要修改address字段的值,首先需要转为对象,再去设置值,再转为json数据
用hash的话,就可以直接去设置address的值 :hset user:1001 address hunan
还可以使用hincrby命令实现数字的递增效果,例如年龄加10:hincrby user:1001 age 10
数据结构:hash有两种存储数据结构:
1、ziplist
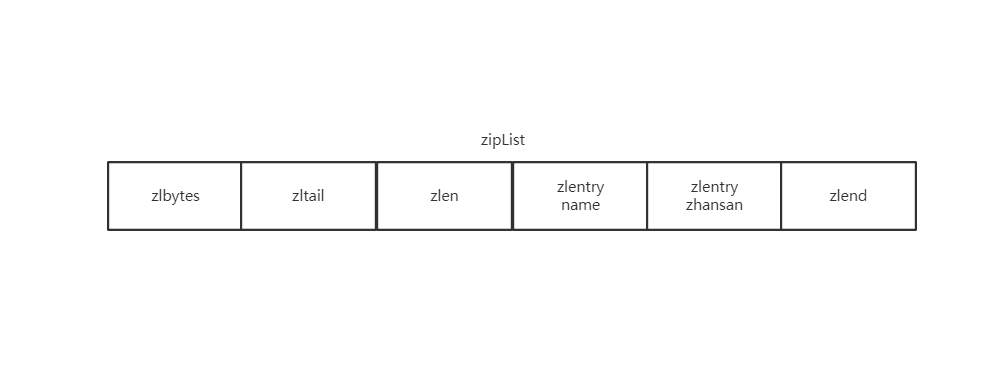
2、dictht

当hash对象可以同时满足两个条件时,哈希对象使用ziplist。
1>哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
2>哈希对象保存的键值对数量小于512个
应用场景:
1、购物车数据,商品详情页数据
2、用户数据
3、原子递增
....................
5、list
常用命令:
LPUSH key value [value...] 从队列的左边入队一个元素或多个元素
LPOP key 从队列的左边出队元素
RPUSH key value [value ....] 从队列的右边入队一个元素
RPOP key 从队列的右边出队一个元素
BLPOP key [key ...] timeout 删除,并获得该列表中的第一元素,如果当前队列没有元素则阻塞,直到有新的元素
BRPOP key [key ...] timeout 删除,并获得该列表中的最后一个元素,如果当前队列没有元素则阻塞,直到有新的元素
LRANGE key start stop 返回列表 key中指定区间内的元素,区间以偏移量start和stop指定。
RPOPLPUSH source destination 命令RPOPLPUSH在一个原子时间内,执行以下两个动作:
1.将列表source中的最后一个元素(尾元素)弹出,并返回给客户端。
2.将source 弹出的元素插入到列表destination,作为destination列表的的头元素。
LLEN key 返回列表 key的长度。
数据结构:
1、栈结构+队列结构
2、支持阻塞/非阻塞的LIFO/FIFO

list是由一个QuickList的一个结构,由一个双向链表,每个节点的数据基于zipList(压缩列表),压缩列表可以节省系统资源。
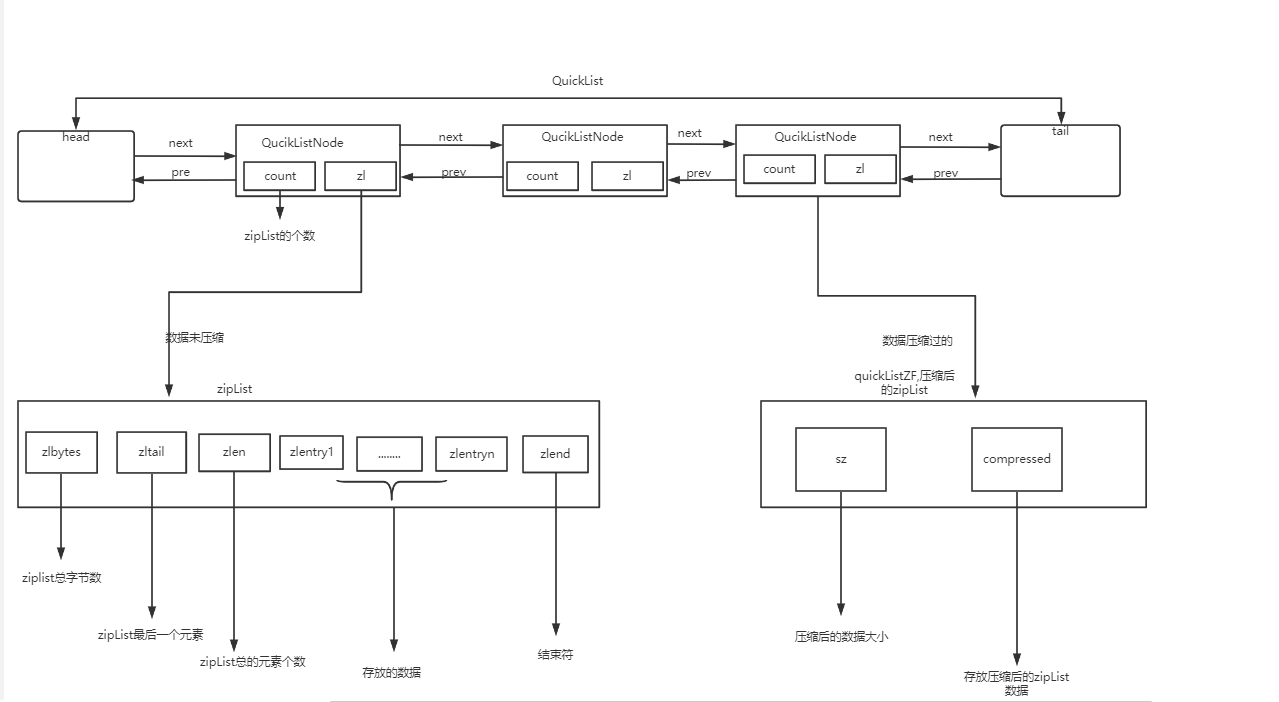
应用场景:
1、分布式队列,消息队列
2、随机红包,一个红包分为十份,创建一个大小为10的List的数据结构
3、库存秒杀活动
.......
6、set
常用命令:
SADD key member [member...] 添加一个或者多个元素到集合(set)里 SCARD key 获取集合里面的元素数量 SDIFF key [key ...] 获得队列不存在的元素 SDIFFSTORE destination key [key ....] 获得队列不存在的元素,并存储在一个关键的结果集 SINTER key [key...] 获得两个集合的交集 SINTERSTORE destination key [key ...] 获得两个集合的交桌,并存储在一个关键的结果集 SISMEMBER key member 确定一个给定的值是一个集合的成员 SMEMBERS key 获取集合里面的所有元素 SMOVE source destination member 移动集合里面的一个元素到另一个集合 SPOP key [count] 删除并获取一个集合里面的元素 SRANDMEMBER key [count] 从集合里面随机获取一个元素 SREM key member [member ...] 从集合里删除一个或多个元素 SUNION key [key ...] 添加多个set元素 SUNIONSTORE destination key [key ...] 合并set元素,并将结果存入新的set里面
数据结构:没有重复元素的一个集合数据结构

set也有两种数据结构:
intset:
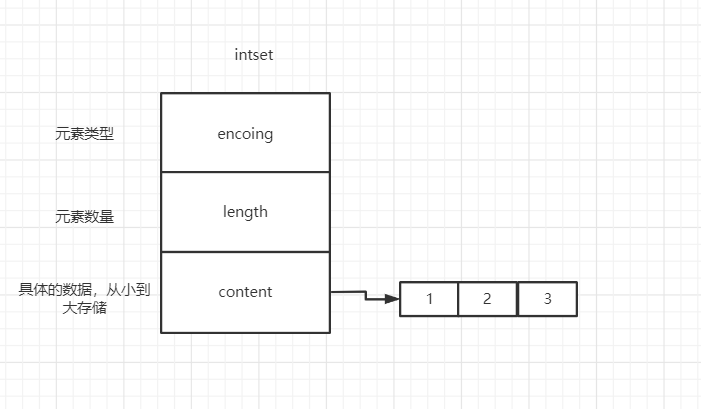
dictht:和hash一样,只不过value值是为null
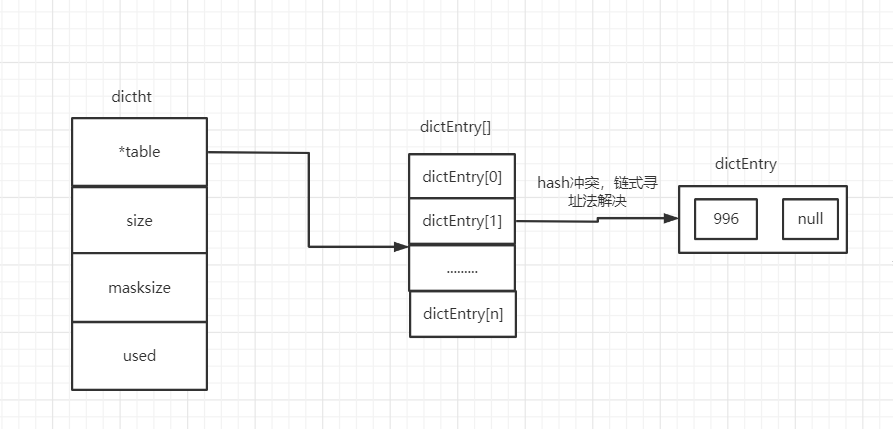
当满足以下两个条件时,采用intset:
1》集合对象保存的所有元素都是整数值。
2》集合对象保存的元素数量不超过512个。
应用场景:
1、用户画像,推荐
2、用户匹配
3、标签
....
7、zset
常用命令:
zadd key score member[{score member}...] 创建或设置指定key对应的有序集合。根据每个值对应的score来排名,升序。
zrem key member 删除指定key对应的集合中的member元素
zcard key 返回指定key对应的有序集合的元素数量
zincrby key increment member 将指定key对应的集合中的member元素对应的分值递增加increment
zcount key min max 返回指定key对应的有序集合中。分值在min-max之间的元素个数
zrank key member 返回指定key对应的有序集合中。指定元素member在集合中排名,从0开始切分值是从小到大升序
zscore key member 返回指定key中的集合中指定member元素对应的分值
zrange key min max [withscores] 返回指定key对应的有序集合中。索引在min~max之间的元素信息,如果带上withscores属性 的话,可以将分值也带出来
zrevrank key member 返回指定key对应的集合中,指定member在其中的排名.注意排名从0开始且按照分值从大到小降序
zrevrange key start end [withscores] 指定key对应的集合中,分值在start~end之间的降序.加上withscores的话可以将分值以及 value都显示出来
zrangebyscore key start end [withscores] 同zrange命令不同的是,zrange命令是索引在start-end范围的查询。 而zrangebyscore命令是根 据分值在start-end之间的查询且升序展示
zremrangebyrank key start end 移除指定key对应集合中索引在start~end之间(包括start和end本身)的元素
zremrangebyscore by min max 同zremrangebyrank命令类似.不同的该命令是删除分值在min~max之间的元素
数据结构:zset也是采用了两种数据结构
zipList:压缩列表
zskipList:跳表
满足以下两个条件使用压缩列表
1>键值对数量少于128个;
2>每个元素的长度小于64字节
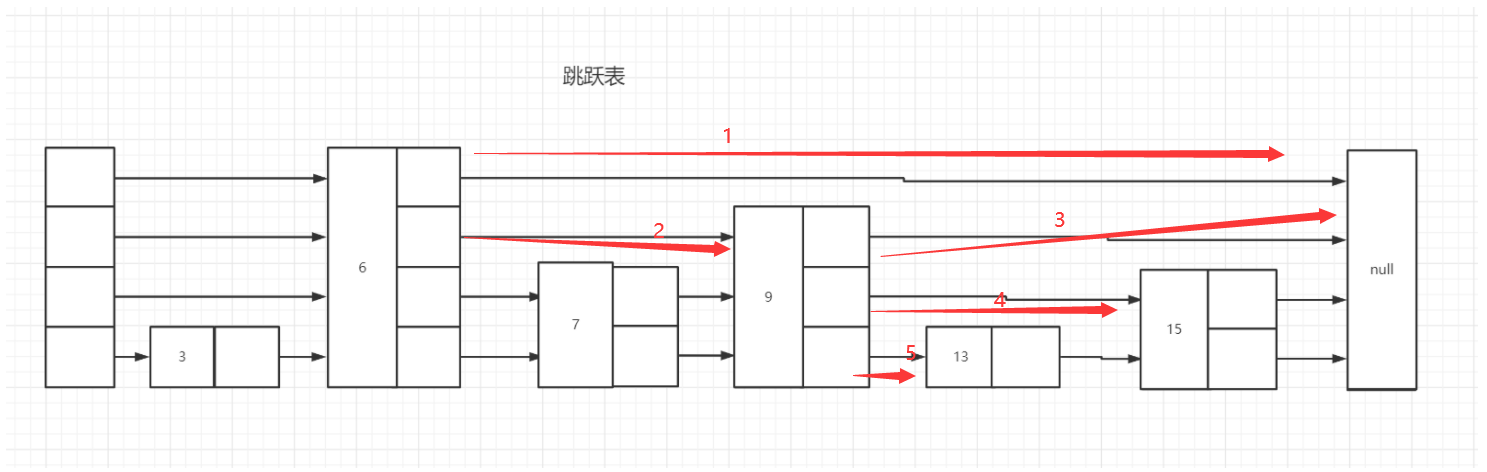
跳跃表:在有序链表的数据结构中,查询的效率为O(n),在跳跃表中,通过建立层次索引,来提高查询的效率O(Logn),
跳跃表体现了空间换时间的思想,在数据比较大的时候的使用。
跳跃表的查询过程:
例如下图已经生成一个调表的结构:现在需要查询13的数,从最高层索引开始查询,步骤如图所示。
应用场景:
1、热点话题
2、排行榜
.......
参考:
https://blog.csdn.net/mccand1234/article/details/93411326
https://www.cnblogs.com/reecelin/p/13368374.html
https://redis.io/documentation