原文链接:http://tecdat.cn/?p=7661
为了在SAS中运行随机森林,我们必须使用PROC HPFOREST指定目标变量,并概述天气变量是“类别”还是“定量”。为了进行此分析,我们使用了目标(Repsone变量),该目标是分类的(SAS语言中标称的),如下面的图像代码中所描述的黄色和红色:
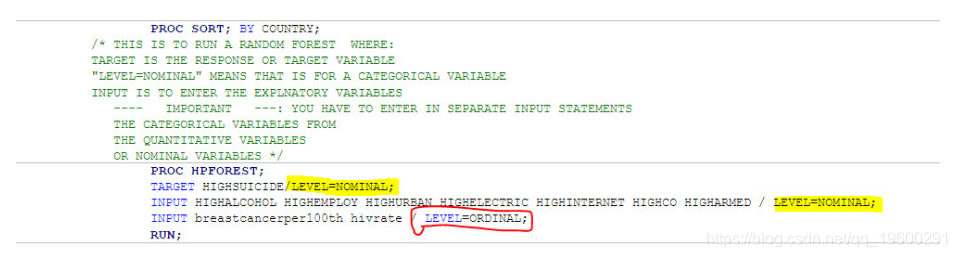
![]()
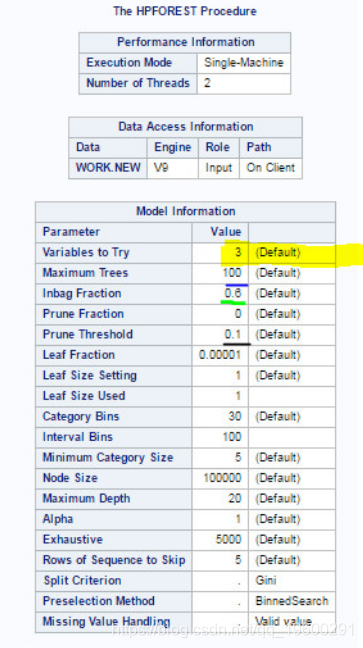
运行代码后,我们得到了一系列表格,这些表格将详细分析数据。例如,模型信息让我们知道,随机选择了3个变量来测试每个节点或每个树中可能的分割(黄色)。我们还可以看到,运行的最大树数为100,如蓝色下划线所示。
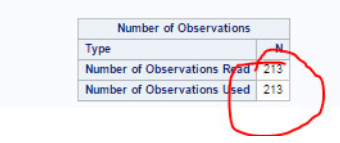
HPFOREST仅使用在任何观察值下均没有缺失记录的有效变量。但是,我们还可以看到,在研究样本的213个国家中,有213个被利用。
![]()
![]()
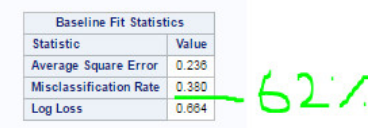
接下来,我们可以看到模型生成带有“基线拟合统计量”的表。就本研究中的数据而言,我们可以看到该模型识别出38%的误分类,换句话说是62%的准确分类。这表示大部分样本已在每个随机选择的样本中正确分类。
![]()
在下表中分析森林时,我们可以看到误分类率已经达到了最低点,这表明在OOB样本中使用该模型进行测试时,误分类率仅在22%。
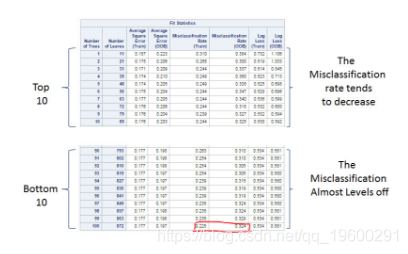
![]()
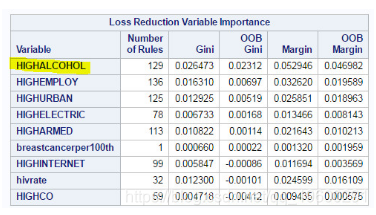
最后,我们看到SAS POC HPFOREST为我们提供了“损失减少变量的重要性”表。下表概述了每个变量如何有助于模型的可预测性的重要性等级。如下图所示,酒精变量排名最高。
现在,以下内容将帮助我们理解如何阅读表格:
- 规则数:告诉我们使用变量的拆分规则数
- 每个数据计算两次:
- Gini OOB:这是在“ Out of Bag”阶段中计算出的数据
- 拟合统计告诉我们,OOB数据的偏差较小,因此,数据通过OOB Gini度量进行排序
- 就预测自杀率高于正常水平而言,这些变量被列为高度重要性(顶部)和最低重要性(底部)。
- 从下表中我们可以看出,最容易预测模型自杀率高于正常模型的变量是酒精消费量,就业率和城市率。

通过上面的练习,我们可以看到随机森林是一种数据挖掘算法,可以选择重要的解释变量,这些变量可以用于确定响应变量(目标变量)的分类结果还是定量结果。此外,此练习还允许我们结合使用分类变量和定量变量。总之,这个森林让我们知道哪些变量很重要,但彼此之间没有关系。