原文链接:http://tecdat.cn/?p=7923
使用R和Python进行分析的主要好处之一是,它们充满活力的开源生态系统中总是有新的和免费提供的服务。如今,越来越多的数据科学家能够同时在R,Python和其他平台上使用数据,这是因为供应商向R和Python引入了具有API的高性能产品,也许还有Java,Scala和Spark。
H2O品牌被称为“商业AI”,“使任何人都可以轻松地应用数学和预测分析来解决当今最具挑战性的业务问题。” H2O的与众不同之处在于其全面的,开源,跨平台,机器学习基础架构从头开始,以实现可扩展性和速度。
在本练习中,我部署了R的数据管理功能来构建模型数据集,然后“导入”到H2o结构中以运行模型。我可以轻松使用H2O功能。
概述的任务序列从数据加载和训练/测试数据集构建开始。然后启动H2O服务器,依次按glm,带有三次样条的glm,梯度增强,随机森林和深度学习模型计算/绘制结果。提供了H2O数据集构建和模型训练的时间。
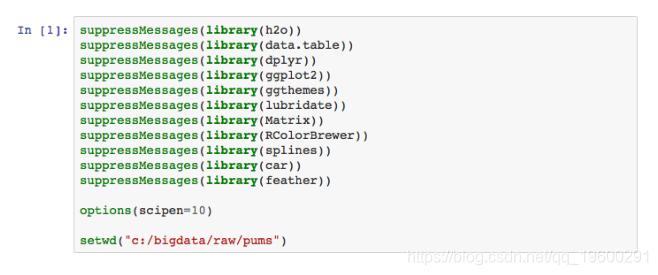
首先加载R库并设置工作目录。
![]()
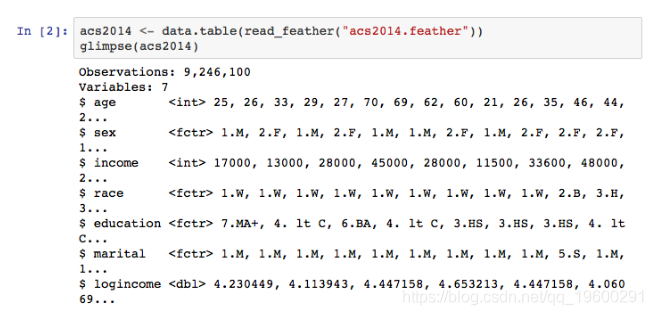
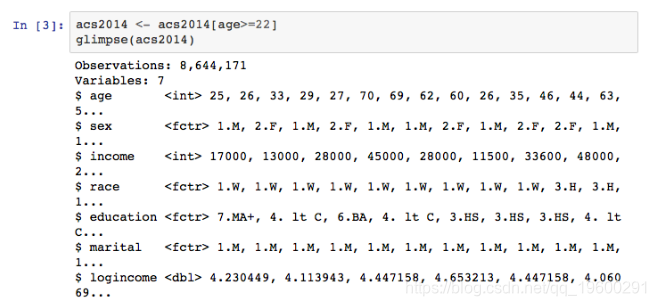
现在加载并子集用于建模练习的数据。 有8,644,171个案例和7个属性。
![]()
![]()
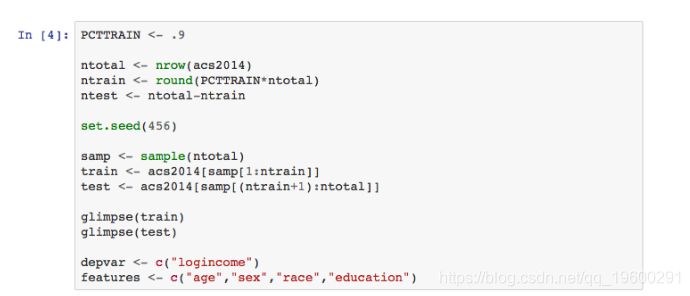
下一步是将Acs2014划分为R中的训练和测试数据表。对于我们的分析,因变量是logincome,而功能包括年龄,性别,种族和教育程度。
![]()

![]()
启动H2O服务器,分配16G RAM并使用所有8个内核。
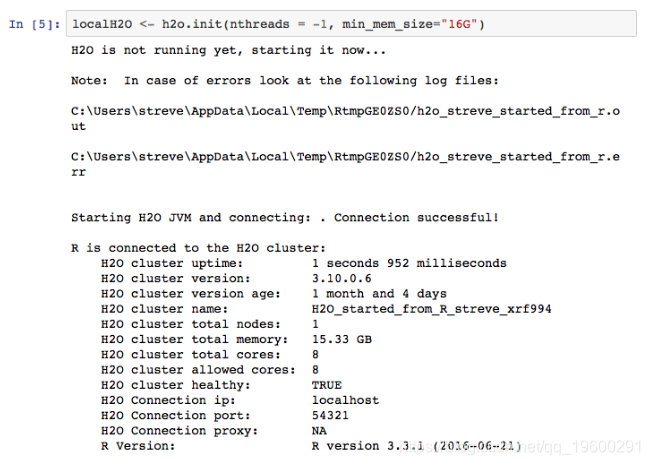
![]()
现在从R data.tables创建H2O数据结构。我们可以使用data.frames / data.tables进行数据处理,也可以直接使用H2O数据结构和功能。
运行 线性模型(glm),并使用训练数据对登录年龄,性别,种族和教育程度进行回归。
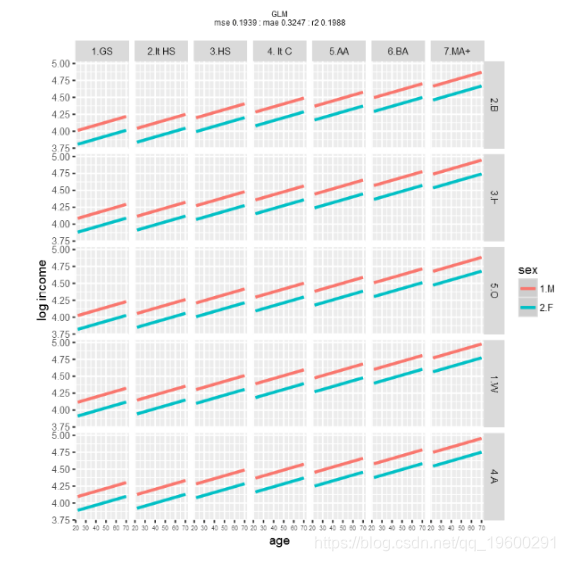
![]()
再次运行glm模型,这次使用年龄的三次样条来显示年龄和登录名之间的曲线关系。

![]()
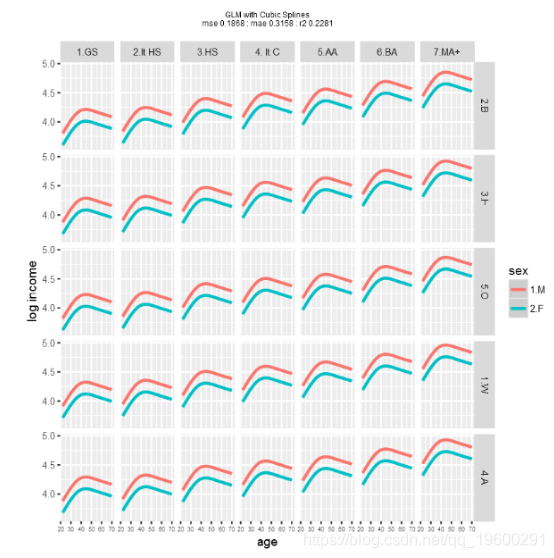
![]()
接下来,进行梯度增强,更多是非参数的,重采样的黑匣子模型。执行速度慢得多,反映出计算量很大。请
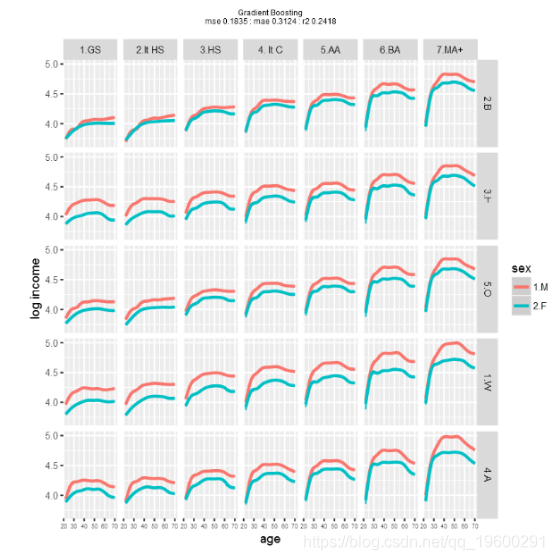
![]()
现在让我们尝试随机森林。
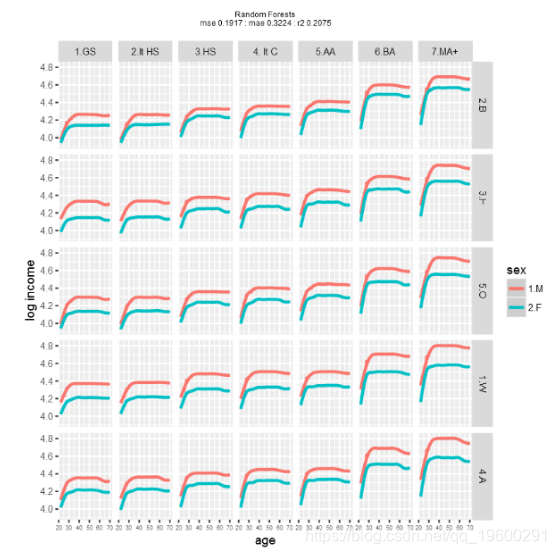
![]()
最后是深度学习。
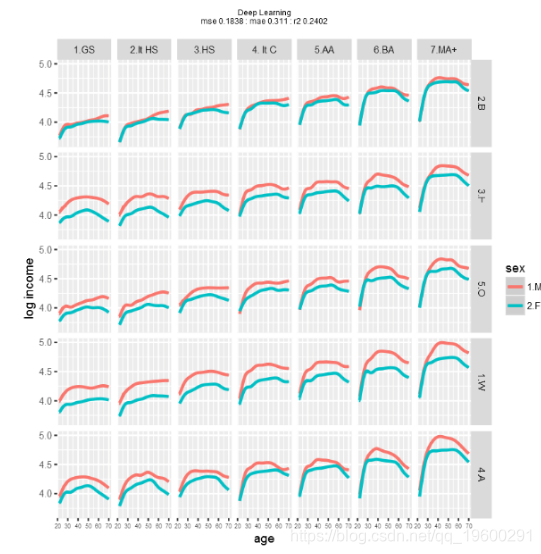
![]()
对模型性能的粗略检查表明,使用这些数据和模型,梯度提升可能会产生最佳结果。当然,不同的训练和测试数据集会产生不同的性能。