原文链接:http://tecdat.cn/?p=8578
介绍
对象检测是一种属于计算机视觉领域的技术。它处理识别和跟踪图像和视频中存在的对象。物体检测具有多种应用,例如面部检测,车辆检测,行人计数,自动驾驶汽车,安全系统等。
对象检测的两个主要目标包括:
- 识别图像中存在的所有对象
- 筛选出关注的对象
在本文中,您将看到如何在Python中执行对象检测。
用于对象检测的深度学习
深度学习技术已被证明可解决各种物体检测问题。
我们将了解ImageAI的确切含义以及如何使用它执行对象检测。
图像AI
ImageAI是一个Python库,旨在使开发人员能够使用几行简单的代码来构建具有独立的深度学习和计算机视觉功能的应用程序和系统。ImageAI包含Python实现的几乎所有最新的深度学习算法,例如TinyYOLOv3。
ImageAI利用了几种脱机工作的API-它具有对象检测,视频检测和对象跟踪API,无需访问互联网即可调用它们。ImageAI利用了预先训练的模型,可以轻松地进行定制。
设置环境
要使用ImageAI,您需要安装一些依赖项。第一步是在计算机上安装Python。
TensorFlow
$ pip install tensorflow
OpenCV
$ pip install opencv-python
$ pip install keras
$ pip install imageAI
现在下载TinyYOLOv3模型文件,该文件包含将用于对象检测的分类模型。
使用ImageAI执行对象检测
现在,让我们看看如何实际使用ImageAI库。我将逐步解释如何使用ImageAI构建第一个对象检测模型。
第1步
我们的第一个任务是创建必要的文件夹。对于本教程,我们需要以下文件夹:
- 对象检测:根文件夹
- 模型:存储预先训练的模型
- 输入:存储要在其上执行对象检测的图像文件
- 输出:存储带有检测到的对象的图像文件
创建文件夹后,Object detection文件夹应包含以下子文件夹:
├── input
├── models
└── output
3 directories, 0 files
第2步
打开用于编写Python代码的首选文本编辑器,然后创建一个新文件detector.py。
第三步
ObjectDetection从ImageAI库导入类。
from imageai.Detection import ObjectDetection
第四步
现在,您已经导入了imageAI库和ObjectDetection该类,下一步是创建该类的实例ObjectDetection,如下所示:
detector = ObjectDetection()
第5步
让我们从输入图像,输出图像和模型指定路径。
model_path = "./models/yolo-tiny.h5"
input_path = "./input/test45.jpg"
output_path = "./output/newimage.jpg"
第6步
我们现在可以从该类中调用各种函数。该类包含以下功能调用预先训练模式:setModelTypeAsRetinaNet(),setModelTypeAsYOLOv3(),和setModelTypeAsTinyYOLOv3()。
就本教程而言,我将使用预训练的TinyYOLOv3模型,因此,我们将使用该setModelTypeAsTinyYOLOv3()函数加载模型。
detector.setModelTypeAsTinyYOLOv3()
步骤7
接下来,我们将调用函数setModelPath()。此函数接受一个字符串,其中包含预训练模型的路径:
detector.setModelPath(model_path)
步骤8
此步骤loadModel()从detector实例中调用函数。它使用setModelPath()类方法从上面指定的路径加载模型。
detector.loadModel()
步骤9
要检测图像中的对象,我们需要detectObjectsFromImage使用detector在上一节中创建的对象来调用函数。
此函数需要两个参数:input_image和output_image_path。input_image是我们正在检测的图像所在的路径,而output_image_path参数是将图像与检测到的对象一起存储的路径。此函数返回一个字典,其中包含图像中检测到的所有对象的名称和百分比概率。
detection = detector.detectObjectsFromImage(input_image=input_path, output_image_path=output_path)
第10步
可以通过遍历字典中的每个项目来访问字典项目。
for eachItem in detection:
print(eachItem["name"] , " : ", eachItem["percentage_probability"])
在输出中,您可以看到每个检测到的对象的名称及其百分比概率,如下所示:
输出
car : 54.72719073295593
car : 58.94589424133301
car : 62.59384751319885
car : 74.07448291778564
car : 91.10507369041443
car : 97.26507663726807
car : 97.55765795707703
person : 53.6459743976593
person : 56.59831762313843
person : 72.28181958198547
原始图片:
原始图像“ test45”如下所示:

![]()
带有对象检测的图像:
检测到对象后,生成的图像如下所示:
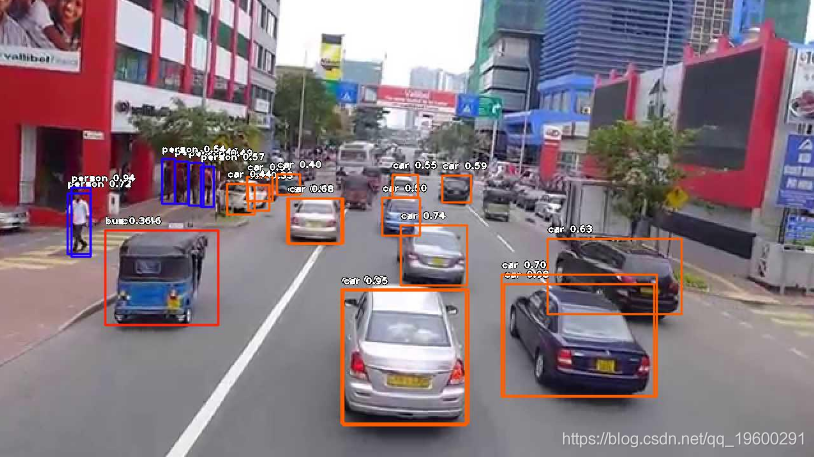
![]()
可以看到ImageAI在图像中成功识别了汽车和人员。
结论
对象检测是最常见的计算机视觉任务之一。本文通过示例说明如何使用ImageAI库在Python中执行对象检测。