原文链接:http://tecdat.cn/?p=12200
对于许多模型,例如物流模型,没有共轭先验。因此,吉布斯采样不适用。
这篇文章展示了我们如何使用Metropolis-Hastings(MH)从每次Gibbs迭代中的非共轭条件后验对象中进行采样–比网格方法更好的替代方法。
我将说明该算法,给出一些R代码结果,然后分析R代码以识别MH算法中的瓶颈。
模型
此示例的模拟数据是包含![]()
![]() 患者的横截面数据集。有一个二元结果,
患者的横截面数据集。有一个二元结果,![]() 一个二元治疗变量,
一个二元治疗变量,![]() 一个因子age。年龄是具有3个等级的分类变量。我用贝叶斯逻辑回归建模:
一个因子age。年龄是具有3个等级的分类变量。我用贝叶斯逻辑回归建模:
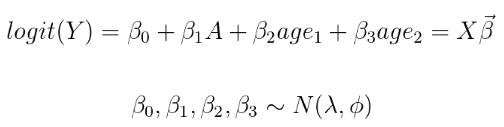
![]()
对于大都市吉布斯来说,这是一个相当现实的示例:
- 我们有一个二进制结果,为此我们采用了非线性链接函数。
- 我们有一个需要调整的因素。
- 我们正在估计我们关心的更多参数。在这种情况下,我们确实关心治疗效果的估计
 ,因此其他系数在某种意义上是令人讨厌的参数。我不会说这是一个“高维”设置,但肯定会给采样器带来压力。
,因此其他系数在某种意义上是令人讨厌的参数。我不会说这是一个“高维”设置,但肯定会给采样器带来压力。
非规范条件后验
让我们看一下该模型的(非标准化)条件后验。我不会进行推导,但是它遵循我以前的帖子中使用的相同过程。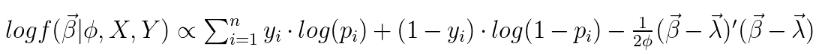
![]()
此条件分布不是已知分布,因此我们不能简单地使用Gibbs从中进行采样。相反,在每个gibbs迭代中,我们需要另一个采样步骤来从该条件后验中提取。第二个采样器将是MH采样器。
Metroplis-in-Gibbs采样
目标是从中取样![]()
![]() 。请注意,这是4维密度。
。请注意,这是4维密度。
MH采样器的工作方式如下:
- 开始采样。
- 让我们假设将提案分配的方差设置为某个常数。
- 我们计算在上一次绘制时评估的非标准化密度与当前提案的比率:
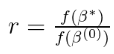
- 如果该比率大于1,则当前提议的密度高于先前值的密度。因此,我们“接受”了提案并确定了
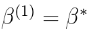 。然后,我们使用以提案为中心的提案分布重复步骤2-4 ,然后生成新提案。如果该比率小于1,则当前建议值的密度低于先前建议。
。然后,我们使用以提案为中心的提案分布重复步骤2-4 ,然后生成新提案。如果该比率小于1,则当前建议值的密度低于先前建议。
因此,总是接受产生更高条件的后验评估的提议。但是,有时仅接受具有较低密度评估的提案-提案的相对密度评估越低,其接受的可能性就越低。
经过多次迭代,从后验的高密度区域开始的抽样被接受,并且被接受的序列“爬升”到高密度区域。一旦序列到达此高密度区域,它将趋于保持在那里。因此,这也类似于模拟退火。
这种表示法很容易扩展到我们的4维示例:提案分布现在是4维多元高斯模型。代替标量方差参数,我们有一个协方差矩阵。因此,我们的建议是系数的向量。从这个意义上讲,我们运行的是Gibbs –使用MH每次迭代绘制整个系数块。
- 跳跃分布的方差是重要的参数。如果方差太小,则当前提案可能会非常接近最后一个值,因此也很可能接近1。因此,我们会非常频繁地接受,但由于接受的值彼此之间非常接近,因此我们会攀升至较高在许多次迭代中慢慢降低密度区域。如果方差太大,则序列到达高密度区域后可能无法保留在该区域。
- 许多“自适应” MH方法是此处描述的基本算法的变体,但包括调整周期以找到产生最佳接受率的跳跃分布方差。
- MH中计算量最大的部分是密度评估。对于每个Gibbs迭代,我们必须两次评估4维密度。
- 尽管此符号很容易扩展到高维度,但性能本身在高维度上会变差。这样做的原因是非常技术性的,但是非常有趣。
结果
这是我们感兴趣的4个参数的MCMC链。红线表示真实值。
profvis(expr = {
for(i in 2:gibbs_iter){
# sample from posterior of phi
gibbs_res[i,p+1] <- rcond_post_phi(gibbs_res[i-1,1:p],
alpha, gamma, lambda, p)
# sample from posterior of beta vector ( using MH )
mh_draw <- rcond_post_beta_mh(gibbs_res[i-1,1:p], gibbs_res[i,p+1],
lambda, X, Y, mh_trials=5, jump_v=.01)
}
})
par(mfrow=c(2,2))
plot(gibbs_res[,1],type='l',xlab='MCMC Iterations',ylab=c('Coefficient Draw'),
main='Intercept')
abline(h=-1,col='red')
plot(gibbs_res[,2],type='l',xlab='MCMC Iterations',ylab=c('Coefficient Draw'),
main='Age1')
abline(h=.7,col='red')
plot(gibbs_res[,3],type='l',xlab='MCMC Iterations',ylab=c('Coefficient Draw'),
main='Age2')
abline(h=1.1,col='red')
plot(gibbs_res[,4],type='l',xlab='MCMC Iterations',ylab=c('Coefficient Draw'),
main='Treatment')
abline(h=1.1,col='red')
# calculate posterior means and credible intervals
post_burn_trim<-gibbs_res[seq(1000,gibbs_iter,100),]
colMeans(post_burn_trim)
apply(post_burn_trim, 2, quantile, p=c(.025,.975))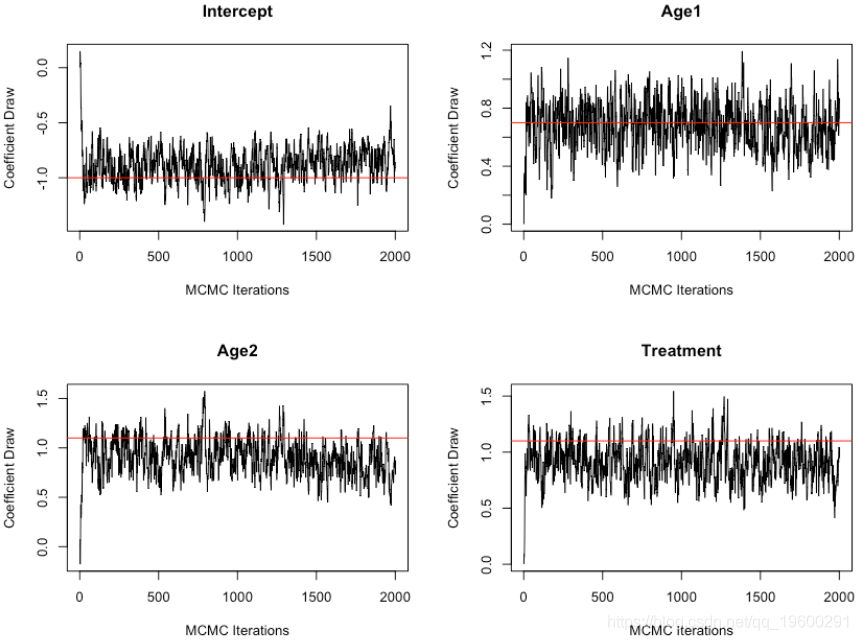
![]()
有一些改进的空间:
- 接受率只有18%,我本可以调整跳跃分布协方差矩阵来获得更好的比率。
- 我认为更多的迭代肯定会在这里有所帮助。这些链看起来不错,但仍然是自相关的。
关于贝叶斯范式的好处是,所有推断都是使用后验分布完成的。现在,系数估计值是对数刻度,但是如果我们需要比值比,则只需对后验取幂。如果我们想要对比值比进行区间估计,那么我们就可以获取指数后验平局的2.5%和97.5%。
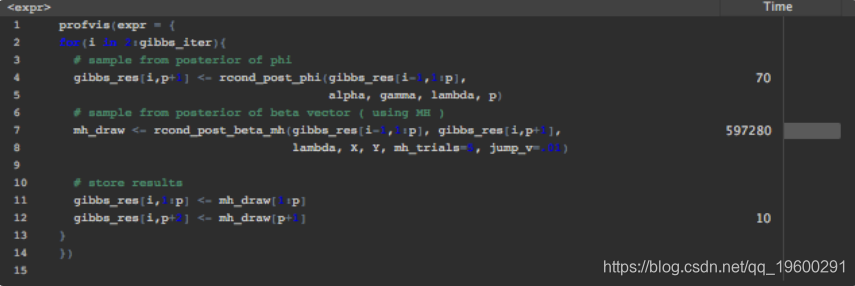
下面是使用R分析,显示了这一点。for循环运行Gibbs迭代。在每个Gibbs迭代中,我都调用函数rcond_post_beta_mh(),该函数使用MH从参数向量的条件后验中得出图形。
![]()
深入研究rcond_post_beta_mh(),我们看到子例程log_cond_post_beta()是MH运行中的瓶颈。此函数是beta载体的对数条件后验密度,将其评估两次。

![]()