原文链接:http://tecdat.cn/?p=17677
今天,我们正在与一位精算数据科学专业的学生讨论,有关保险费率制定的与索赔频率模型有关的观点。由于目标是预测理赔频率(以评估保险费水平),因此他建议使用旧数据来训练该模型,并使用最新数据对其进行测试。问题在于该模型没有包含任何时间模式。
这里考虑一个简单的数据集,
-
> set.seed(1)
-
> n=50000
-
> X1=runif(n)
-
> T=sample(2000:2015,size=n,replace=TRUE)
-
> L=exp(-3+X1-(T-2000)/20)
-
> E=rbeta(n,5,1)
-
> Y=rpois(n,L*E)
-
> B=data.frame(Y,X1,L,T,E)
频率由泊松过程驱动,具有一个协变量X1,并且我们假设呈指数速率。在此考虑标准线性回归,没有任何时间因素影响
-
> reg=glm(Y~X1+offset(log(E)),data=B,
-
+ family=poisson)
我们还可以计算年度经验索赔频率
-
> u=seq(0,1,by=.01)
-
> v=predict(re
-
-
> vp=Vectorize(p)(seq(.05,.95,by=.1))
并在同一张图上绘制两条曲线,
-
> plot(seq(.05,.95,by=.1),vp,type="b")
-
> lines(u,exp(v),lty=2,col="red")
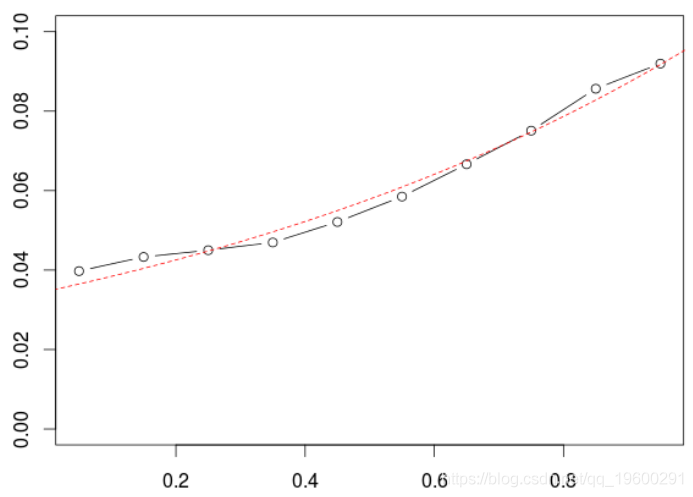
这就是我们通常在计量经济学中所做的。在机器学习中,更具体地说,是评估模型的质量以及进行模型选择,通常将数据集分为两部分。训练样本和验证样本。考虑一些随机的训练/验证样本,然后在训练样本上拟合模型,最后使用它来进行预测,
-
> idx=sample(1:nrow(B
-
-
> reg=glm(Y~X1+offset(log(E)),data=B_a,
-
+ family=poisson)
-
> u=seq(0,1,by=.01)
-
> v=predict(reg,new
-
$E)
-
+ }
-
> vp_a=Vectorize(p)(seq(.05,.95,by=.1))
-
> plot(seq(.05,.95,by=.1),vp_a,col="blue")
-
> lines(u,exp(v),l
-
X1-x)<.1,]
-
+ sum(B$Y)/sum(B$E)
-
+ }
-
-
)(seq(.05,.95,by=.1))
-
> lines(seq(.05,.95,by=.1),vp_t,col="red")
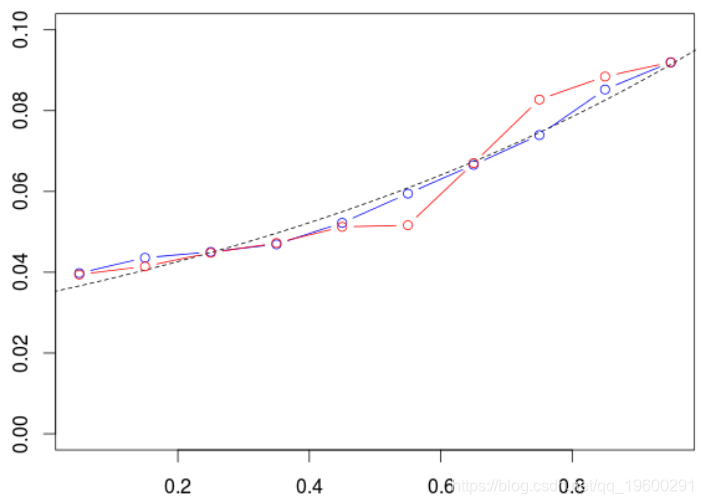
蓝色曲线是对训练样本的预测(就像在计量经济学中所做的那样),红色曲线是对测试样本的预测。
现在,如果我们使用年份作为划分标准,我们将旧数据拟合为模型,并在最近几年对其进行测试,
-
> B_a=subset(
-
T>=2014)
-
> reg=glm(Y~X1+offset(l
-
-
-
+ B=B_a[abs(B_a$X1-x)<.1,]
-
+ sum(B$Y)/sum(B$E)
-
+ }
-
> vp_a=Vectorize(p)(
-
y=.1),vp_a,col="blue")
-
> lines(u,exp(v),lty=2)
-
> p=function(x){
-
-x)<.1,]
-
+ sum(B$Y)/sum(B$E)
-
+ }
-
eq(.05,.95,by=.1))
-
> lines(seq(.05,.95,b=.1),vp_t,
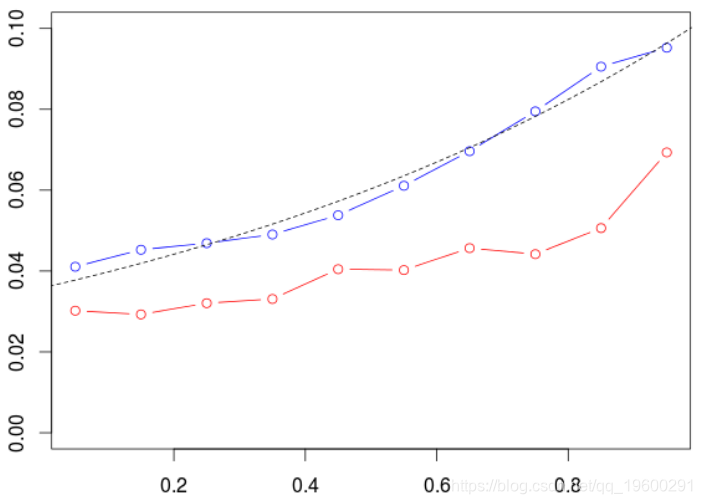
显然,结果不理想。
我花了一些时间来了解训练和验证样本的设计方式对结果产生的影响。
我使用回归模型:
-
-
glm(Y~X1+T+offset(log(E)),data=B,
-
+ family=poisson)
-
-
> u=seq(1999,2016,by=
-
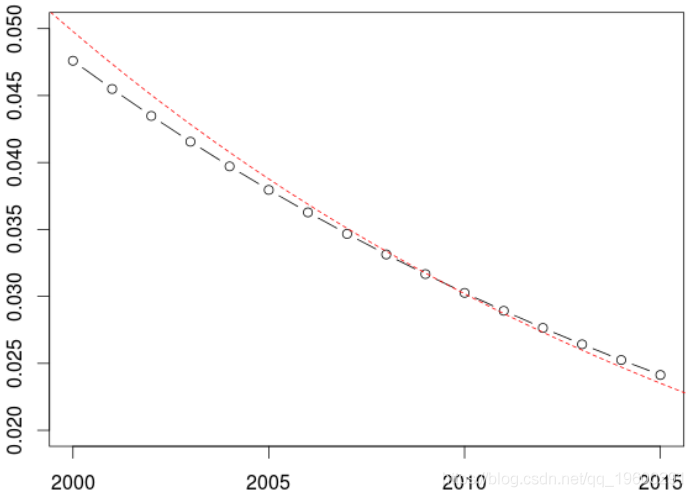
在这里,我们使用线性模型,但是通常没有理由假设线性。所以我们可以考虑样条
-
-
-
> reg=glm(Y~X1+bs(T)+offse
-
-
> u=seq(1999,2016,by=.
-
-
> v2=predict(reg,newdata=
-
-
> plot(2000:2015,exp(v2),ty
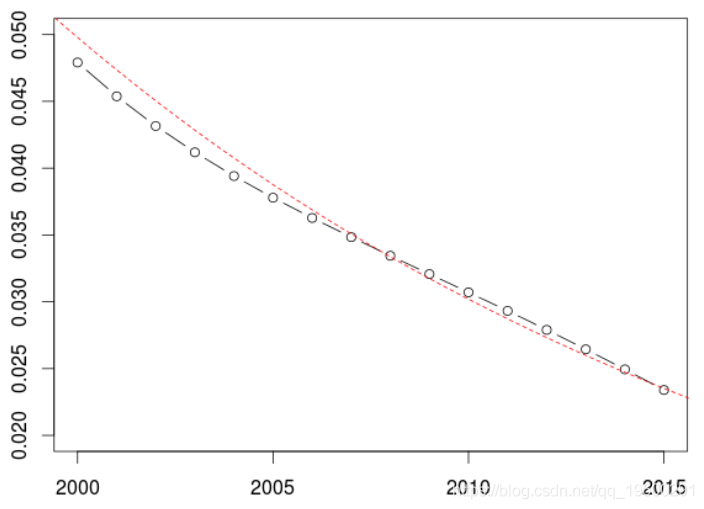
除了假设存在一个基本的平滑函数,我们可以考虑因子的回归
-
-
as.factor(T)+
-
-
+ data=B,family=p
-
g)
-
> u=seq(1999,2016,by=.1)
-
> v=exp(-(u-2000)/20
-
[2:17]),type="b")
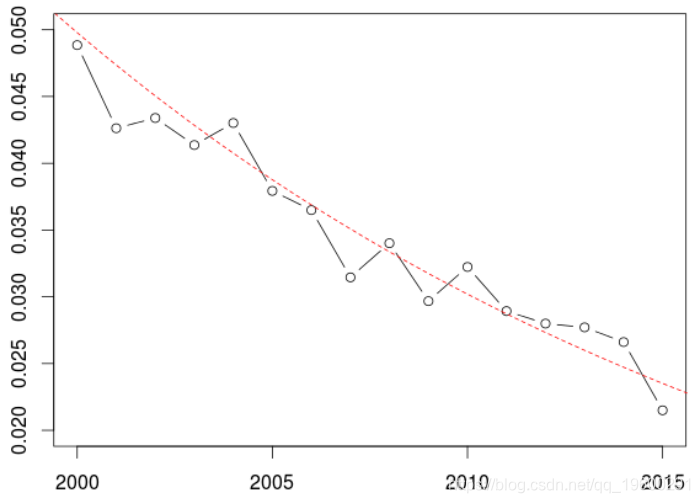
另一种选择是考虑一些更通用的模型,例如回归树
-
-
-
> reg=rpart(Y~X1+T+offset(log(E)),dat
-
-
> p=function(t){
-
+ B=B[B$T==t,]
-
-
+ mean(predict(reg,newdata=B))
-
+ }
-
2000:2015)
-
> u=seq(1999,2016,by=.1)
-
-
> plot(2000:2015,y_m,ylim=c(
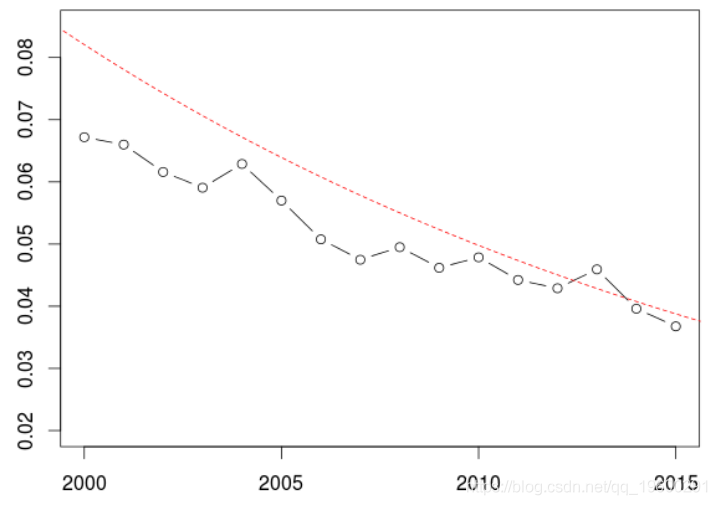
在年化频率上考虑与风险敞口相关的权重
-
> reg=rpart(Y/E~X1+T,data
-
weights=B$E,cp=1
-
-
+ B=B[B$T==t,]
-
+ B$E=1
-
-
+ }
-
> y_m=Vectorize(function(t) p(t))(
-
-
> v=exp(-(u-2000)/20-3+.5)
-
> plot(2000:2015,y_m,ylim=c(.02,.08
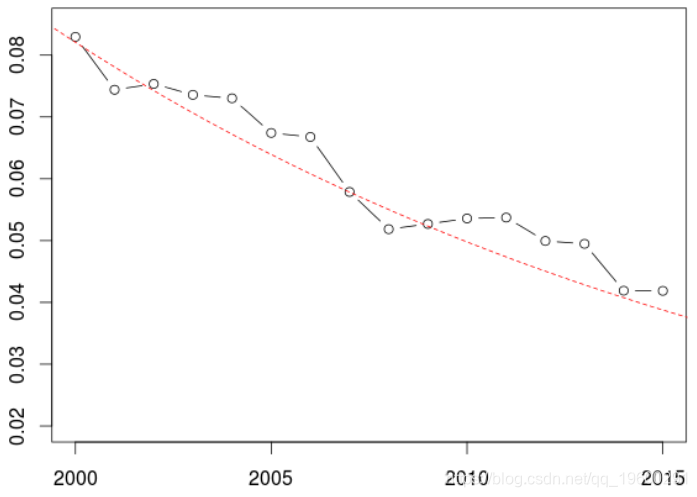
从机器学习的角度来看,考虑训练样本(基于旧数据)和验证样本(基于较新的样本)
-
> B_a=subset(B,T<2014)
-
> B_t=subset(B,T>=2014)
如果我们考虑使用广义线性模型,那么也很容易获得近年来的预测,
-
> reg_a=glm(Y~X1+T+offset(l
-
-
> C=coefficients(reg_a)
-
> u=seq(1999,20
-
/20-3)
-
+C[3]*c(2000:2013,
-
+ NA,NA)),type="b")
-
)
-
> points(2014:2015,exp(C
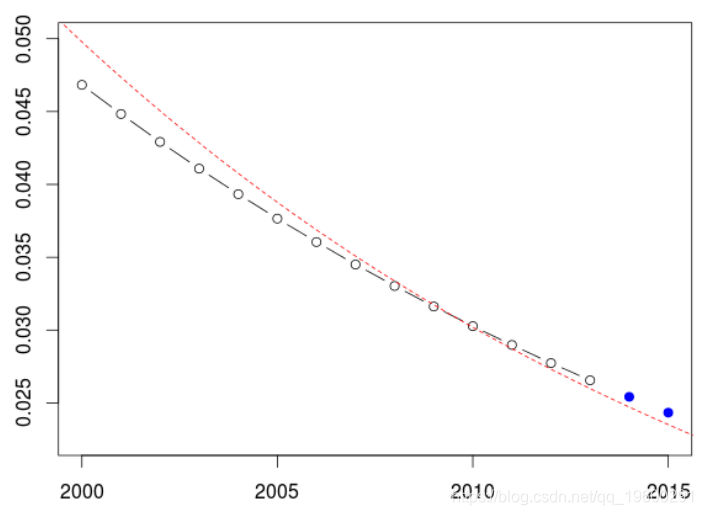
但是,如果我们以年份为因子,我们需要对训练样本中没有的水平进行预测,结果更加复杂。
-
> reg_a=glm(Y~0+X1+as.factor(T)+offse
-
-
> C=coefficients(reg_a)
-
2014) + A[2]*(B_t$T==2015))
-
+ Y_t=L*B_t$E
-
-
> i=optim(c(.4,.4),RMSE)$par
-
> plot(2000:2015,c(exp(C[2:15]
-
-
> lines(u,v,lty=2,col="red")
-
lue")
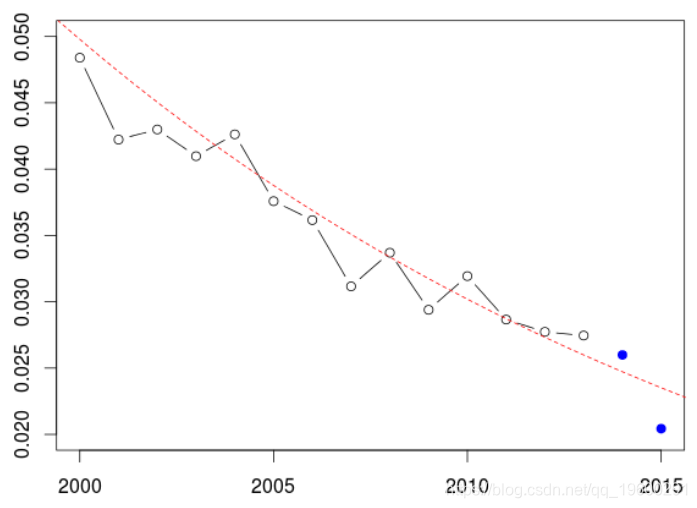
我们将RMSE量化近年来的预测水平,输出还不错。
获得旧数据的训练数据集,并在最近几年对其进行测试应该谨慎适当地考虑时间模型。
最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析