原文链接:http://tecdat.cn/?p=18149
无人驾驶汽车最早可以追溯到1989年。神经网络已经存在很长时间了,那么近年来引发人工智能和深度学习热潮的原因是什么呢?[1秒]答案部分在于摩尔定律以及硬件和计算能力的显著提高。我们现在可以事半功倍。顾名思义,神经网络的概念是受我们自己大脑神经元网络的启发。神经元是非常长的细胞,每个细胞都有称为树突的突起,分别从周围的神经元接收和传播电化学信号。结果,我们的脑细胞形成了灵活强大的通信网络,这种类似于装配线的分配过程支持复杂的认知能力,例如音乐播放和绘画。
视频:CNN(卷积神经网络)模型以及R语言实现
神经网络结构
神经网络通常包含一个输入层,一个或多个隐藏层以及一个输出层。输入层由p个预测变量或输入单位/节点组成。不用说,通常最好将变量标准化。这些输入单元可以连接到第一隐藏层中的一个或多个隐藏单元。与上一层完全连接的隐藏层称为密集层。在图中,两个隐藏层都是密集的。

输出层的计算预测
输出层计算预测,其中的单元数由具体的问题确定。通常,二分类问题需要一个输出单元,而具有k个类别的多类问题将需要 k个对应的输出单元。前者可以简单地使用S形函数直接计算概率,而后者通常需要softmax变换,从而将所有k个输出单元中的所有值加起来为1,因此可以将其视为概率。无需进行分类预测。
权重
图中显示的每个箭头都会传递与权重关联的输入。每个权重本质上是许多系数估计之一,该系数估计有助于在相应箭头指向的节点中计算出回归![]() 。这些是未知参数,必须使用优化过程由模型进行调整,以使损失函数最小化。训练之前,所有权重均使用随机值初始化。
。这些是未知参数,必须使用优化过程由模型进行调整,以使损失函数最小化。训练之前,所有权重均使用随机值初始化。
优化和损失函数
训练之前,我们需要做好两件事一是拟合优度的度量,用于比较所有训练观测值的预测和已知标签;二是计算梯度下降的优化方法,实质上是同时调整所有权重估计值,以提高拟合优度的方向。对于每种方法,我们分别具有损失函数和优化器。损失函数有很多类型,所有目的都是为了量化预测误差,例如使用交叉熵![]() 。流行的随机优化方法如Adam。
。流行的随机优化方法如Adam。
卷积神经网络
卷积神经网络是一种特殊类型的神经网络,可以很好地用于图像处理,并以上述原理为框架。名称中的“卷积”归因于通过滤镜处理的图像中像素的正方形方块。结果,该模型可以在数学上捕获关键的视觉提示。例如,鸟的喙可以在动物中高度区分鸟。在下面描述的示例中,卷积神经网络可能会沿着一系列涉及卷积,池化和扁平化的变换链处理喙状结构,最后,会看到相关的神经元被激活,理想情况下会预测鸟的概率是竞争类中最大的。

可以基于颜色强度将图像表示为数值矩阵。单色图像使用2D卷积层进行处理,而彩色图像则需要3D卷积层,我们使用前者。
核(也称为滤镜)将像素的正方形块卷积为后续卷积层中的标量,从上到下扫描图像。
在整个过程中,核执行逐元素乘法,并将所有乘积求和为一个值,该值传递给后续的卷积层。
内核一次移动一个像素。这是内核用来进行卷积的滑动窗口的步长,逐步调整。较大的步长意味着更细,更小的卷积特征。
池化是从卷积层进行的采样,可在较低维度上呈现主要特征,从而防止过度拟合并减轻计算需求。池化的两种主要类型是平均池化和最大池化。提供一个核和一个步长,合并就相当于卷积,但取每帧的平均值或最大值。
扁平化顾名思义,扁平只是将最后的卷积层转换为一维神经网络层。它为实际的预测奠定了基础。
R语言实现
当我们将CNN(卷积神经网络)模型用于训练多维类型的数据(例如图像)时,它们非常有用。我们还可以实现CNN模型进行回归数据分析。我们之前使用Python进行CNN模型回归 ,在本视频中,我们在R中实现相同的方法。
我们使用一维卷积函数来应用CNN模型。我们需要Keras R接口才能在R中使用Keras神经网络API。如果开发环境中不可用,则需要先安装。本教程涵盖:
- 准备数据
- 定义和拟合模型
- 预测和可视化结果
- 源代码
我们从加载本教程所需的库开始。
-
library(keras)
-
library(caret)
准备
数据在本教程中,我们将波士顿住房数据集用作目标回归数据。首先,我们将加载数据集并将其分为训练和测试集。
-
set.seed(123)
-
boston = MASS::Boston
-
indexes = createDataPartition(boston$medv, p = .85, list = F)
-
-
train = boston[indexes,]
-
test = boston[-indexes,]
接下来,我们将训练数据和测试数据的x输入和y输出部分分开,并将它们转换为矩阵类型。您可能知道,“ medv”是波士顿住房数据集中的y数据输出,它是其中的最后一列。其余列是x输入数据。
检查维度。
-
dim(xtrain)
-
[1] 432 13
-
-
dim(ytrain)
-
[1] 432 1
接下来,我们将通过添加另一维度来重新定义x输入数据的形状。
-
dim(xtrain)
-
[1] 432 13 1
-
-
dim(xtest)
-
[1] 74 13 1
在这里,我们可以提取keras模型的输入维。
-
print(in_dim)
-
[1] 13 1
定义和拟合模型
我们定义Keras模型,添加一维卷积层。输入形状变为上面定义的(13,1)。我们添加Flatten和Dense层,并使用“ Adam”优化器对其进行编译。
-
-
-
model %>% summary()
-
________________________________________________________________________
-
Layer (type) Output Shape Param #
-
========================================================================
-
conv1d_2 (Conv1D) (None, 12, 64) 192
-
________________________________________________________________________
-
flatten_2 (Flatten) (None, 768) 0
-
________________________________________________________________________
-
dense_3 (Dense) (None, 32) 24608
-
________________________________________________________________________
-
dense_4 (Dense) (None, 1) 33
-
========================================================================
-
Total params: 24,833
-
Trainable params: 24,833
-
Non-trainable params: 0
-
________________________________________________________________________
-
-
接下来,我们将使用训练数据对模型进行拟合。
-
-
print(scores)
-
loss
-
24.20518
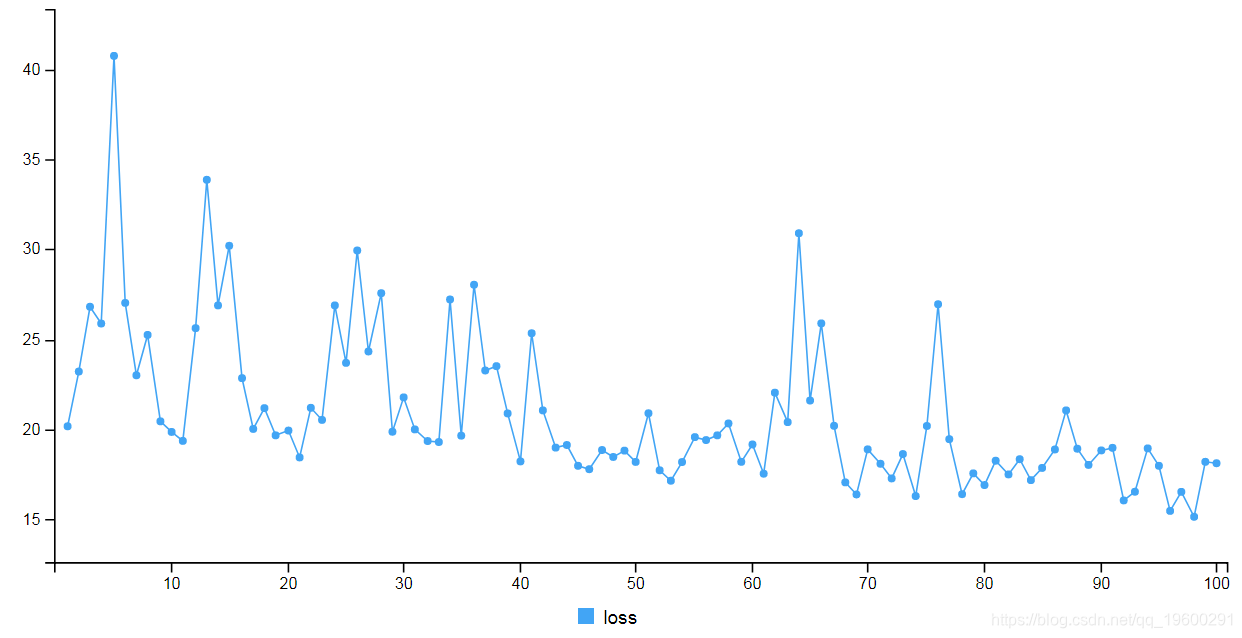
预测和可视化结果
现在,我们可以使用训练的模型来预测测试数据。
predict(xtest)
我们将通过RMSE指标检查预测的准确性。
-
cat("RMSE:", RMSE(ytest, ypred))
-
RMSE: 4.935908
最后,我们将在图表中可视化结果检查误差。
-
x_axes = seq(1:length(ypred))
-
-
lines(x_axes, ypred, col = "red", type = "l", lwd = 2)
-
legend("topl
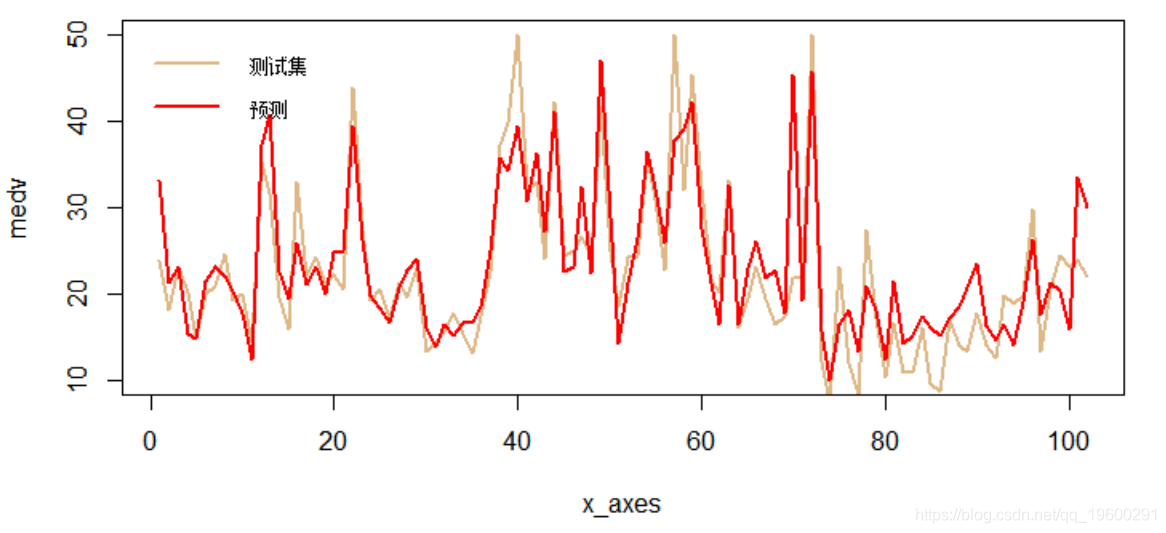
在本教程中,我们简要学习了如何使用R中的keras CNN模型拟合和预测回归数据。

最受欢迎的见解
1.r语言用神经网络改进nelson-siegel模型拟合收益率曲线分析
3.python用遗传算法-神经网络-模糊逻辑控制算法对乐透分析
4.用于nlp的python:使用keras的多标签文本lstm神经网络分类