原文链接:http://tecdat.cn/?p=19405
包含更多的预测变量不是免费的:在系数估算的更多可变性,更难的解释以及可能包含高度依赖的预测变量方面要付出代价。确实, 对于样本大小![]() ,在线性模型中可以考虑 的预测变量最大数量为 p 。或等效地,使用预测变量p 拟合模型需要最小样本量
,在线性模型中可以考虑 的预测变量最大数量为 p 。或等效地,使用预测变量p 拟合模型需要最小样本量![]() 。
。
如果我们考虑p = 1 和 p = 2 的几何,这一事实的解释很简单:
- 如果p = 1,则至少需要n = 2个点才能唯一地拟合一条线。但是,这条线没有给出关于其周围变化的信息,因此无法估计
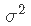 。因此,我们至少需要
。因此,我们至少需要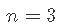 个点,换句话说就是
个点,换句话说就是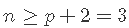 。
。 - 如果p = 2 ,则至少需要n = 3个点才能唯一地拟合平面。但是同样,该平面没有提供有关其周围数据变化的信息,因此无法估计
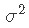 。因此,我们需要
。因此,我们需要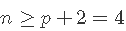 。
。
下一部分代码的输出阐明了![]() 和
和![]() 之间的区别。
之间的区别。
-
-
-
-
n <- 5
-
p <- n - 1
-
df <- data.frame(y = rnorm(n), x = matrix(rnorm(n * p), nrow = n, ncol = p))
-
-
-
-
-
summary(lm(y ~ ., data = df))
-
-
-
-
summary(lm(y ~ . - x.1, data = df))
当![]() 减小时,自由度
减小时,自由度![]() 量化
量化![]() 的变异性的增加。
的变异性的增加。

既然我们已经更多地了解了预测变量过多的问题,我们将重点放在 为多元回归模型选择最合适的预测变量上。如果没有独特的解决方案,这将是一项艰巨的任务。但是,有一个行之有效的程序通常会产生良好的结果: 逐步模型选择。其原理是 依次比较具有不同预测变量的多个线性回归模型。
在介绍该方法之前,我们需要了解什么是 信息准则。信息标准在模型的适用性与采用的预测变量数量之间取得平衡。两个常见标准是 贝叶斯信息标准 (BIC)和 赤池信息标准 (AIC)。两者都基于 模型适用性和复杂性之间的平衡:
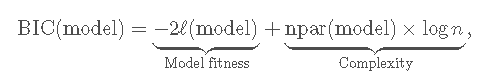
其中![]() 是模型的对 数似然度 (模型拟合数据的程度),而
是模型的对 数似然度 (模型拟合数据的程度),而![]() 是考虑的参数数量在模型中,对于具有p个预测变量的多元线性回归模型,则为p + 2。AIC在用
是考虑的参数数量在模型中,对于具有p个预测变量的多元线性回归模型,则为p + 2。AIC在用![]() 替换了
替换了![]() , 因此,与BIC相比,它对 较复杂的模型的处罚较少。这就是为什么一些从业者更喜欢BIC进行模型比较的原因之一。BIC和AIC可以通过
, 因此,与BIC相比,它对 较复杂的模型的处罚较少。这就是为什么一些从业者更喜欢BIC进行模型比较的原因之一。BIC和AIC可以通过BIC 和 计算 AIC。
我们使用地区房价数据,变量介绍:
(1)town:每一个人口普查区所在的城镇
(2)LON: 人口普查区中心的经度
(3)LAT: 人口普查区中心的纬度
(4)MEDV: 每一个人口普查区所对应的房子价值的中位数 (单位为$1000)
(5)CRIM: 人均犯罪率
(6)ZN: 土地中有多少是地区是大量住宅物业
(7)INDUS: 区域中用作工业用途的土地占比
(8)CHAS: 1:该人口普查区紧邻查尔斯河;0: 该人口普查区没有紧邻查尔斯河
(9)NOX: 空气中氮氧化物的集中度 (衡量空气污染的指标)
(10)RM: 每个房子的平均房间数目
(11)AGE: 建于1940年以前的房子的比例
(12)DIS: 该人口普查区距离波士顿市中心的距离
(13)RAD: 距离重要高速路的远近程度 (1代表最近;24代表最远)
(14)TAX: 房子每$10,000价值所对应的税收金额
(15)PTRATIO: 该城镇学生与老师的比例
他们将作为模型输入。
-
-
# 具有不同预测变量的两个模型
-
-
mod1 <- lm(medv ~ age + crim, data = Boston)
-
mod2 <- lm(medv ~ age + crim + lstat, data = Boston)
-
-
# BICs
-
BIC(mod1)
-
-
BIC(mod2) # 较小->较好
-
-
-
# AICs
-
AIC(mod1)
-
-
AIC(mod2) # 较小->较好
-
-
-
# 检查摘要
-
-
-
##
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
summary(mod2)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
让我们回到预测变量的选择。如果我们有p个预测变量,那么一个简单的过程就是检查 所有 可用它们构建的可能模型,然后根据BIC / AIC选择最佳模型。这就是所谓的 最佳子集选择。问题在于存在![]() 个可能的模型!
个可能的模型!
让我们看看如何研究 wine 数据集,将使用所有可用预测变量的数据作为初始模型。
波尔多是法国的葡萄酒产区。尽管这种酒的生产方式几乎相同,但已有数百年历史,但每年的价格和质量差异有时非常显着。人们普遍认为波尔多葡萄酒陈年越老越好,因此有动力去储存葡萄酒直至成熟。主要问题在于,仅通过品尝就很难确定葡萄酒的质量,因为在实际饮用时,味道会发生很大变化。这就是为什么葡萄酒品尝师和专家会有所帮助的原因。他们品尝葡萄酒,然后预测以后将是最好的葡萄酒。
1990年3月4日,《纽约时报》宣布普林斯顿大学经济学教授奥利·阿森费尔特(Orley Ashenfelter)可以预测波尔多葡萄酒的质量而无需品尝一滴。 Ashenfelter使用了一种称为线性回归的方法。该方法预测结果变量或因变量。作为自变量,他使用了酒的年份(因此,较老的酒会更昂贵)和与天气有关的信息,特别是平均生长季节温度,收成雨和冬雨。
stepAIC 将参数 k 设为2 (默认值)或![]() ,其中n是样本大小。
,其中n是样本大小。k = 2 它采用AIC准则, k = log(n) 它采用BIC准则。
-
-
# 完整模型
-
-
-
# 用 BIC
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
summary(modBIC)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
# 用 AIC
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
summary(modAIC)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
接下来是stepAIC 对执行情况的解释 。在每个步骤中, stepAIC 显示有关信息标准当前值的信息。例如,对于 modBIC,第一步的BIC是Step: AIC=-53.29 ,然后在第二步进行 了改进 Step: AIC=-56.55 (即使使用“ BIC”,该功能也会始终输出“ AIC”)。下一个继续前进的模型是stepAIC 通过研究添加或删除预测变量后得出的不同模型的信息标准来决定的 (取决于 direction 参数,在下文中进行解释)。例如modBIC在第一步中,删除导致的模型 FrancePop 的BIC等于 -56.551,如果 Year 删除,则BIC将为 -56.519。逐步回归,然后删除 FrancePop (因为它给出了最低的BIC),然后重复此过程,最终导致删除 <none> 预测变量是可能的最佳操作。下面的代码块说明了stepsAIC的输出 extractAIC,和BIC / AIC的输出BIC/ AIC。
-
-
# 相同的BIC,标准不同
-
-
-
AIC(modBIC, k = log(n))
-
-
BIC(modBIC)
-
-
-
-
-
-
AIC(modBIC, k = 2)
-
-
BIC(modBIC)
-
-
-
-
BIC(modBIC) - AIC(modBIC
-
-
n * (log(2 * pi+ 1) + log(n)
-
-
-
#与AIC相同
-
-
-
AIC(modAIC) - AIC(modAIC
-
-
n * (log(2 * pi + 1 + 2
-
请注意,所选模型 modBIC 和 modAIC 等效于 modWine2 ,我们选择的最佳模型。这说明,选择的模型 stepAIC 通常是进一步添加或删除预测变量的良好起点。
使用 stepAIC BIC / AIC时,可能会选择不同的最终模型 direction。这是解释:
“backward”: 从给定模型中顺序删除预测变量。“forward”: 将 预测变量顺序添加到给定模型中。“both”(默认):以上的组合。
该 建议 是尝试几种这些方法并保留一个最小的BIC / AIC。设置 trace = 0 为省略冗长的搜索过程信息输出。下面的代码块清楚地说明了如何使用 数据集的修改版本 来利用 direction 参数和的其他选项 。stepAICwinedirection = "forward"direction = "both"scope
-
-
# 将无关的预测变量添加到葡萄酒数据集中
-
-
# 向后选择:从给定模型中顺序删除预测变量
-
-
-
# 从具有所有预测变量的模型开始
-
-
-
-
modAll, direction = "backward", k = log(n)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
# 从中间模型开始
-
-
-
AIC(modInter, direction = "backward", k = log(n)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
# 正向选择:从给定模型顺序添加预测变量
-
-
-
# 从没有预测变量的模型开始,仅截距模型(表示为〜1)
-
-
-
AIC(modZero, direction = "forward"
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
#从中间模型开始
-
-
-
-
## Start: AIC=-32.38
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
#两种选择:如果从中间模型开始,则很有用
-
-
#消除了与从中间模型完成的“向后”和“向前”搜索相关的问题
-
-
-
## Start: AIC=-32.38
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
#使用完整模型中的默认值实质上会进行向后选择,但允许已删除的预测变量在以后的步骤中再次输入
-
-
-
AIC(modAll direction = "both", k = log(n)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
# 省略冗长的输出
-
-
-
AIC(modAll, direction = "both", trace = 0
-
-
-
-
-
-
-
-
对Boston 数据集运行逐步选择 ,目的是清楚地了解不同的搜索方向。特别:
"forward"从 逐步拟合medv ~ 1开始做。"forward"从 逐步拟合medv ~ crim + lstat + age开始做。"both"从 逐步拟合medv ~ crim + lstat + age开始做。"both"从逐步拟合medv ~ .开始做。"backward"从逐步拟合medv ~ .开始做。
stepAIC 假定数据中不存在 NA(缺失值)。建议先删除数据中的缺失值。它们的存在可能会导致错误。为此,请使用 data = na.omit(dataset) 调用 lm (如果您的数据集为 dataset)。
我们通过强调使用BIC和AIC得出结论:它们的构造是假设样本大小n 远大于模型中参数的数量p + 2。因此,如果n >> p + 2 ,它们将工作得相当好,但是如果不是这样,则它们可能会支持不切实际的复杂模型。下图对此现象进行了说明。BIC和AIC曲线倾向于使局部最小值接近p = 2,然后增加。但是当p + 2 接近n 时,它们会迅速下降。

图:n = 200和p从1 到198 的BIC和AIC的比较。M = 100数据集仅在前两个 预测变量有效的情况下进行了模拟 。较粗的曲线是每种颜色曲线的平均值。
房价案例研究应用
我们要建立一个线性模型进行预测和解释 medv。有大量的预测模型,其中一些可能对预测medv没什么用 。但是,目前尚不清楚哪个预测变量可以更好地解释 medv 的信息。因此,我们可以对所有 预测变量进行线性模型处理 :
-
-
summary(modHouse)
-
-
-
##
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
有几个不重要的变量,但是到目前为止,该模型具有R ^ 2 = 0.74,并且拟合系数对预期的结果很敏感。例如 crim, tax, ptratio,和 nox 对medv有负面影响 ,同时 rm, rad和 chas 有正面的影响。但是,不重要的系数不会显着影响模型,而只会增加噪声并降低系数估计的总体准确性。让我们稍微完善一下以前的模型。
-
-
# 最佳模型
-
-
AIC(modHouse, k = log(nrow(Boston)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
# 模型比较
-
compare(modBIC, modAIC)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
summary(modBIC)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
# 置信区间
-
-
conf(modBIC)
-
-
-
-
-
-
-
-
-
-
-
-
-
请注意,相对于完整模型,![]() 略有增加,以及所有预测变量显着。
略有增加,以及所有预测变量显着。
我们已经量化了预测变量对房价(Q1)的影响,可以得出结论,在最终模型(Q2)中,显着性水平为 ![]() :
:
chas,age,rad,black对medv有 显著正面 的影响 ;nox,dis,tax,ptratio,lstat对medv有 显著负面 的影响。
检查:
modBIC不能通过消除预测指标来改善BIC。modBIC无法通过添加预测变量来改进BIC。使用addterm(modBIC, scope = lm(medv ~ ., data = Boston), k = log(nobs(modBIC)))。
-
应用其公式,我们将获得
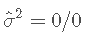 ,因此
,因此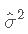 将不会定义。
将不会定义。 -
具有相同的因变量。
-
如果是
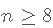 ,则
,则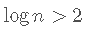 。
。 -
同样,由于BIC 在选择真实的分布/回归模型时是 一致的:如果提供了足够的数据
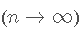 ,则可以保证BIC在候选列表中选择真实的数据生成模型。如果真实模型包含在该列表中,则模型为线性模型。但是,由于实际模型可能是非线性的,因此在实践中这可能是不现实的。
,则可以保证BIC在候选列表中选择真实的数据生成模型。如果真实模型包含在该列表中,则模型为线性模型。但是,由于实际模型可能是非线性的,因此在实践中这可能是不现实的。

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
5.R语言回归中的Hosmer-Lemeshow拟合优度检验