原文链接:http://tecdat.cn/?p=19751
本示例说明如何使用长短期记忆(LSTM)网络对序列数据进行分类。
要训练深度神经网络对序列数据进行分类,可以使用LSTM网络。LSTM网络使您可以将序列数据输入网络,并根据序列数据的各个时间步进行预测。
本示例使用日语元音数据集。此示例训练LSTM网络来识别给定时间序列数据的说话者,该时间序列数据表示连续讲话的两个日语元音。训练数据包含九位发言人的时间序列数据。每个序列具有12个特征,并且长度不同。数据集包含270个训练观察和370个测试观察。
加载序列数据
加载日语元音训练数据。 XTrain 是包含长度可变的维度12的270个序列的单元阵列。 Y 是标签“ 1”,“ 2”,...,“ 9”的分类向量,分别对应于九个扬声器。中的条目 XTrain 是具有12行(每个要素一行)和不同列数(每个时间步长一列)的矩阵。
-
XTrain(1:5)
-
ans=5×1 cell array
-
{12x20 double}
-
{12x26 double}
-
{12x22 double}
-
{12x20 double}
-
{12x21 double}
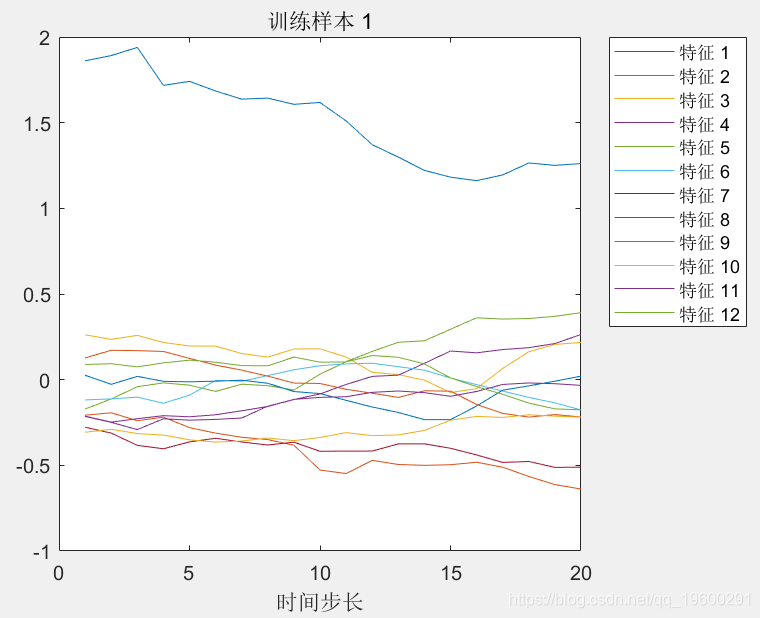
可视化图中的第一个时间序列。每行对应一个特征。
-
figure
-
plot(Train')
-
xlabel("时间步长")
-
title("训练样本 1")
-
numFeatures = size(XTrain{1},1);
-
legend("特征 "
准备填充数据
在训练过程中,默认情况下,该软件默认将训练数据分成小批并填充序列,以使它们具有相同的长度。太多的填充可能会对网络性能产生负面影响。
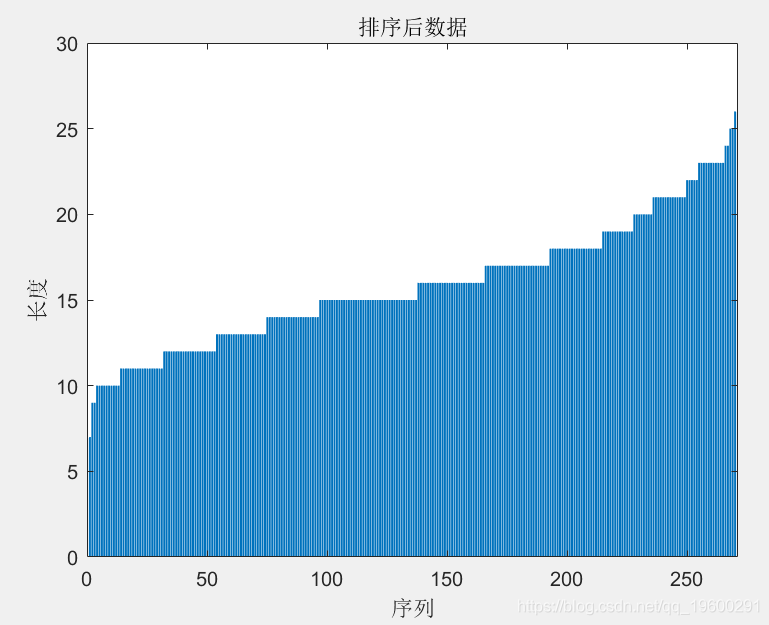
为防止训练过程增加太多填充,您可以按序列长度对训练数据进行排序,并选择小批量的大小,以使小批量中的序列具有相似的长度。下图显示了对数据进行排序之前和之后的填充序列的效果。
获取每个观察的序列长度。
按序列长度对数据进行排序。
在条形图中查看排序的序列长度。
-
figure
-
bar(sequenceLengths)
-
ylim([0 30])
-
xlabel("序列")
-
ylabel("长度")
-
title("排序后数据")
选择大小为27的小批量可均匀划分训练数据并减少小批量中的数量。下图说明了添加到序列中的填充量。
定义LSTM网络架构
定义LSTM网络体系结构。将输入大小指定为大小为12的序列(输入数据的大小)。指定具有100个隐藏单元的双向LSTM层,并输出序列的最后一个元素。最后,通过包括大小为9的完全连接层,其后是softmax层和分类层,来指定九个类。
如果可以在预测时使用完整序列,则可以在网络中使用双向LSTM层。双向LSTM层在每个时间步都从完整序列中学习。例如,如果您无法在预测时使用整个序列,比如一次预测一个时间步长时,请改用LSTM层。
-
-
layers =
-
5x1 Layer array with layers:
-
-
1 '' Sequence Input Sequence input with 12 dimensions
-
2 '' BiLSTM BiLSTM with 100 hidden units
-
3 '' Fully Connected 9 fully connected layer
-
4 '' Softmax softmax
-
5 '' Classification Output crossentropyex
现在,指定训练选项。将优化器指定为 'adam',将梯度阈值指定为1,将最大历元数指定为100。要减少小批量中的填充量,请选择27的小批量大小。与最长序列的长度相同,请将序列长度指定为 'longest'。为确保数据仍按序列长度排序,请指定从不对数据进行随机排序。
由于批处理的序列短,因此训练更适合于CPU。指定 'ExecutionEnvironment' 为 'cpu'。要在GPU上进行训练(如果有),请将设置 'ExecutionEnvironment' 为 'auto' (这是默认值)。
训练LSTM网络
使用指定的训练选项来训练LSTM网络 trainNetwork。
测试LSTM网络
加载测试集并将序列分类为扬声器。
加载日语元音测试数据。 XTest 是包含370个长度可变的维度12的序列的单元阵列。 YTest 是标签“ 1”,“ 2”,...“ 9”的分类向量,分别对应于九个扬声器。
-
XTest(1:3)
-
ans=3×1 cell array
-
{12x19 double}
-
{12x17 double}
-
{12x19 double}
LSTM网络 net 是使用相似长度的序列进行训练的。确保测试数据的组织方式相同。按序列长度对测试数据进行排序。
分类测试数据。要减少分类过程引入的数据量,请将批量大小设置为27。要应用与训练数据相同的填充,请将序列长度指定为 'longest'。
计算预测的分类准确性。
-
acc = sum(YPred == YTest)./numel(YTest)
-
acc = 0.9730

最受欢迎的见解
1.用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
2.Python中利用长短期记忆模型LSTM进行时间序列预测分析 – 预测电力消耗数据
4.Python中用PyTorch机器学习分类预测银行客户流失模型
6.在r语言中使用GAM(广义相加模型)进行电力负荷时间序列分析