原文链接:http://tecdat.cn/?p=20678
预测股价已经受到了投资者,政府,企业和学者广泛的关注。然而,数据的非线性和非平稳性使得开发预测模型成为一项复杂而具有挑战性的任务。在本文中,我将解释如何将 GARCH,EGARCH和 GJR-GARCH 模型与Monte-Carlo 模拟结合使用, 以建立有效的预测模型。金融时间序列的峰度,波动率和杠杆效应特征证明了GARCH的合理性。时间序列的非线性特征用于检查布朗运动并研究时间演化模式。非线性预测和信号分析方法因其在特征提取和分类中的鲁棒性而在股票市场上越来越受欢迎。
动力学系统可以用一组时变(连续或离散)变量来描述,这些变量构成信号分析非线性方法的基础。如果时间的当前值和状态变量可以准确地描述下一时刻的系统状态,则可以说这样的系统是确定性的。另一方面,如果时间和状态变量的当前值仅描述状态变量的值随时间变化的概率,则将动力学系统视为随机系统。
因此,在使用GARCH 建模方法之前 ,我将采用 分形维数(FD),重定 范围 和 递归量化分析(RQA)的 数据建模 技术 来总结数据的非线性动力学行为并完成研究目标。
方法
Hurst系数 (H) 是长期依赖的特征参数,与 FD (FD + H = 2)有关。 R / S分析是数据建模的核心工具。经验研究表明, 与同类中的其他方法相比, R / S带来了更好的结果,例如自相关,光谱分解的分析。它是度量时间序列差异的度量,该时间序列的定义是给定持续时间(T)的均值范围 ,除以该持续时间的标准偏差 [ R / S = k * T(H) ]; ķ 是一个取决于时间序列的常数。H度量时间序列的长期记忆,将其表征为均值回复,趋势或随机游走。
H <0.5表示均值回复
H> 0.5表示趋势序列,并且
H = 0.5表示随机游走。
我将展示如何使用 GARCH 模型进行风险评估。
GARCH 模型的一个关键限制 是对其参数施加非负约束,以确保条件方差的正性。这样的约束会给估计GARCH 模型带来困难 。
因此,提出了 非对称GARCH 模型,即俗称的 GJR-GARCH 模型,以解决对称GARCH 模型的局限性 。更重要的是,指数 GARCH 或 EGARCH 模型相对于传统的GARCH 模型具有潜在的改进 。
数据挖掘
查看数据。
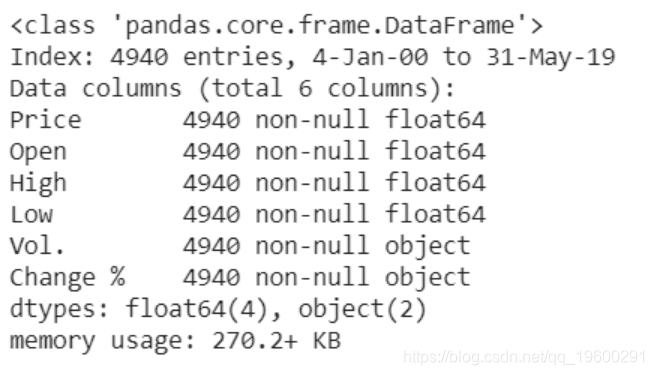
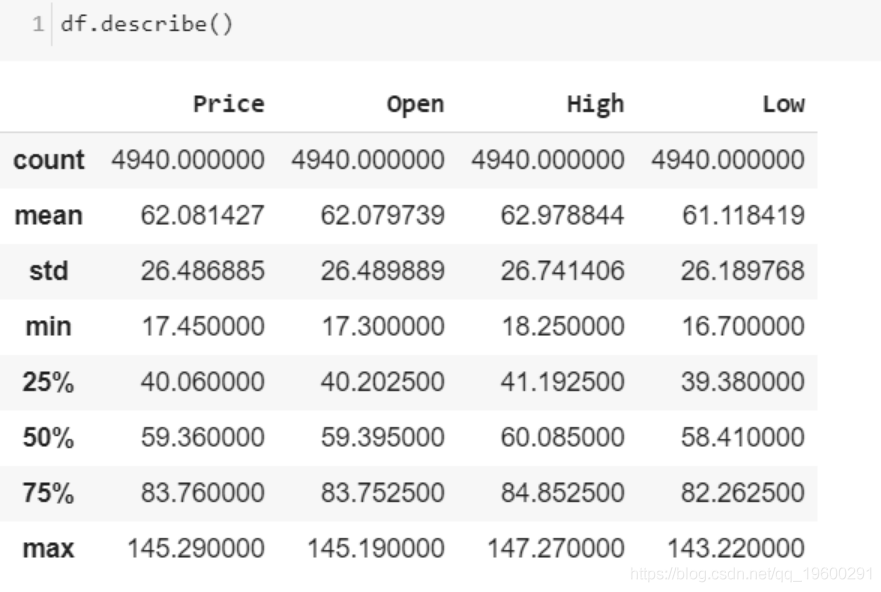

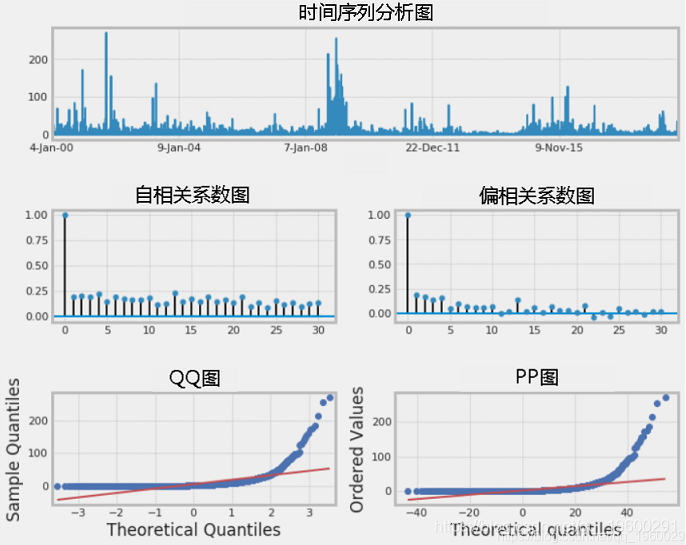
在过去的几十年中,原油价格呈现出较大的波动,尤其是在2008年左右。可以看出,随着多次上升和下降,价格保持在相对较低的水平。从自相关图可以看出原始数据中明显的自相关。QQ和PP图的形状表明该过程接近正态,但是重尾分布。
简单收益率的常用形式为:r(t)= {p(t)— p(t-1)} / p(t-1),对数收益率= ln(pt / p(t-1),pt每日原油价格,r(t)是每日收益。
对数收益率在这里被视为本文的每日收益率。原始价格和对数收益率的直观显示清楚地证明了以几乎恒定的均值,使用对数收益率是合理的。
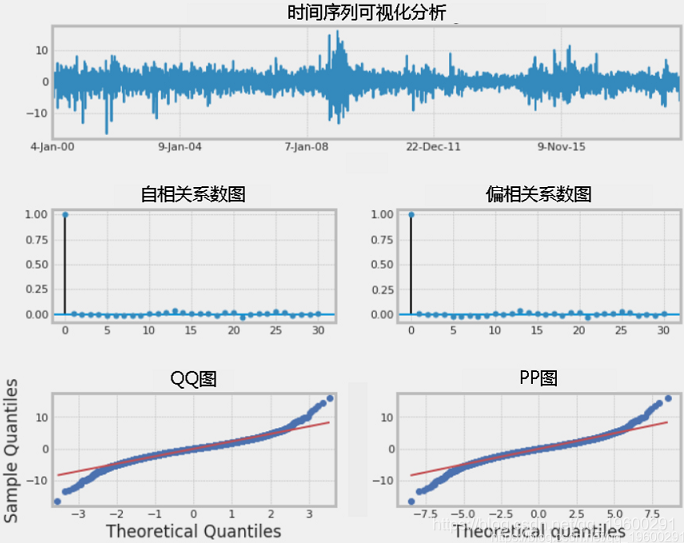
收益率序列图显示了高和低变化周期。在图中可以看到一个随机且集中在零附近的过程。大幅度波动的正收益和负收益都增加了风险投资和管理的难度。每日收益率的平均值基本上在零水平水平附近,并且具有明显的波动性聚类,表明存在异方差性。ACF很小,但是高度相关。QQ和PP图的形状没有明显变化。
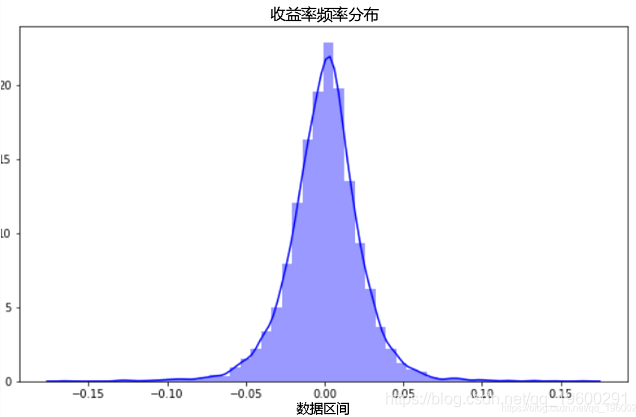
-
-
sns.distplot(df.returns, color=’blue’) #密度图
-
-
# 汇总统计数据
-
print(df.returns.describe())
-
收益率的偏度(-0.119)和向右偏离表明,收益率正比负收益率高,峰度(7.042)反映了油价波动大。
标准正态分布的偏度和峰度分别为0和3。
Jarque-Bera检验的值表明,传统的正态分布假设不适用于原油收益的真实分布。
-
ADF = ADF(df.returns)
-
print(ADF.summary().as_text())
-
-
kpss = KPSS(df.returns)
-
print(kpss.summary().as_text())
-
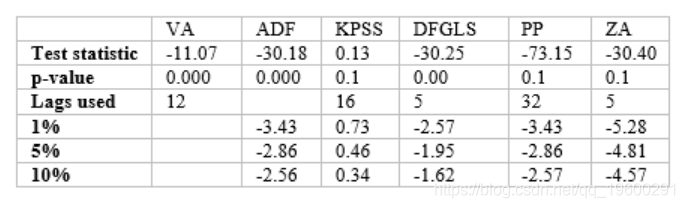
进行了VR检验,以测试对数收益率序列是否是纯粹的随机游走,以及是否具有一定的可预测性。我在这里比较了1个月和12个月的对数收益率,并且拒绝了该系列为纯随机游走的空值。用负检验统计量VA(-11.07)拒绝零表示在时间序列中存在序列相关性。用ADF,KPSS,DFGLS,PP和ZA统计量对单位根和平稳性进行的检验均显示出显着性,表明使用 GARCH型模型来拟合收益序列是合适的。
非线性动力学
使用Hurst对平稳性的研究 。
-
-
# 计算最近价格的Hurst系数
-
-
tau = [sqrt(std(subtract(closes_recent[lag:], closes_recent[:-lag]))) for lag in lags]
-
m = polyfit(log(lags), log(tau), 1)
-
hurst = m[0]*2
H(0.531)表示具有长期依赖性的随机运动时间序列。证明了 本研究中GARCH模型的合理性 。
-
-
computation = RQAComputation.create(settings,
-
verbose=True)
-
result = computation.run()
-
result.min_diagonal_line_length = 2
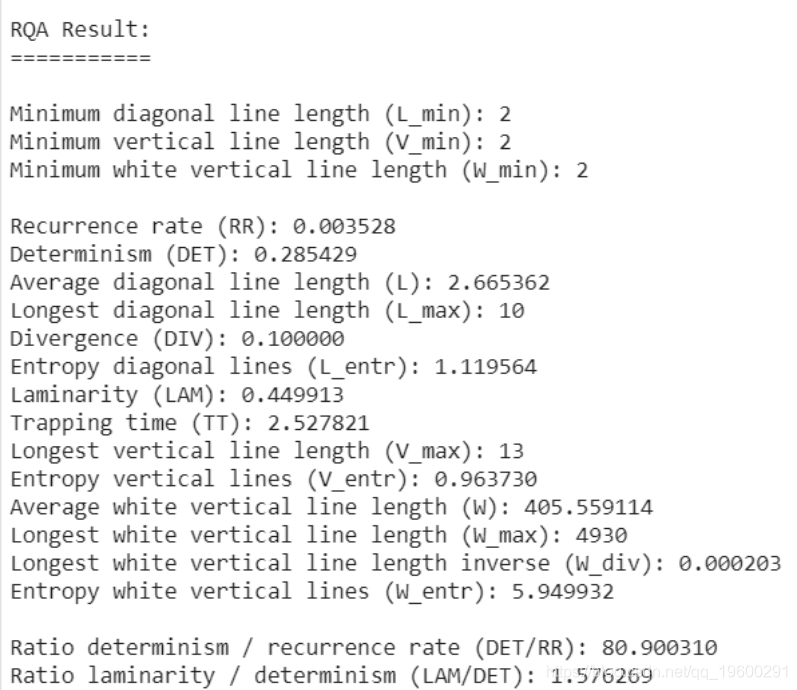
此处,低 R 表示较低的周期性和随机行为。此外,较低的 DET 值表示不确定性。这证明了使用GARCH 方法的合理性 。
GARCH模型
在估算GARCH类型的模型之前,将收益率乘以100。由于波动率截距与模型中其他参数非常接近,因此这有助于优化程序进行转换。
-
-
X = 100* df.returns
-
让我们拟合一个 ARCH 模型并绘制平方残差以检查自相关性。
-
-
def getbest(TS):
-
best_aic = np.inf
-
-
for i in pq_rng:
-
for d in d_rng:
-
for j in pq_rng:
-
try:
-
tmp_mdl = smt.ARIMA(TS, order=(i,d,j)).fit(
-
-
-
-
-
#aic: 22462.01 | order: (2, 0, 2)
-
gam = arch_model(Model.resid, p=2, o=0, q=2, dist=’StudentsT’)
-
gres = gam.fit(update_freq=5, disp=’off’)
-
print(gres.summary())
-
-
tsplot(gres.resid**2, lags=30)
我们可以看到平方残差具有自相关的依据。让我们拟合一个GARCH模型并查看其性能。我将按照以下步骤进行操作:
- 通过ARIMA(p,d,q) 模型的组合进行迭代 ,以拟合最优时间序列。
- 根据 具有最低AIC的ARIMA模型选择 GARCH模型 。
- 将 GARCH(p,q) 模型拟合到时间序列。
- 检查模型残差和平方残差进行自相关
因此,我们在这里发现,最好的模型是 ARIMA(2,0,2)。现在,我们对残差进行绘图,以确定它们是否具有条件异方差。
arch_model(X, p=2, q=2, o=1,power=2.0, vol=’Garch’, dist=’StudentsT’)
-
-
am = arch_model(X, p=2, q=2, o=1,power=2.0, vol=’Garch’, dist=’StudentsT’)
-
-
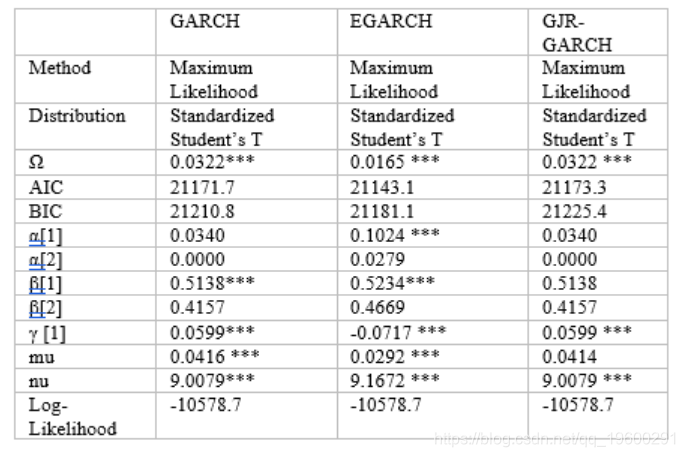
所有3个GARCH 模型的输出 都以表格格式显示。Ω (ω) 是白噪声,alpha和beta是模型的参数。此外, α[1] +β[1] <1 表示稳定的模型。 EGARCH 似乎是最好的三个这模型。
最好在训练/测试中拆分数据并获得MSE / MAE / RMSE结果以比较最佳模型拟合。
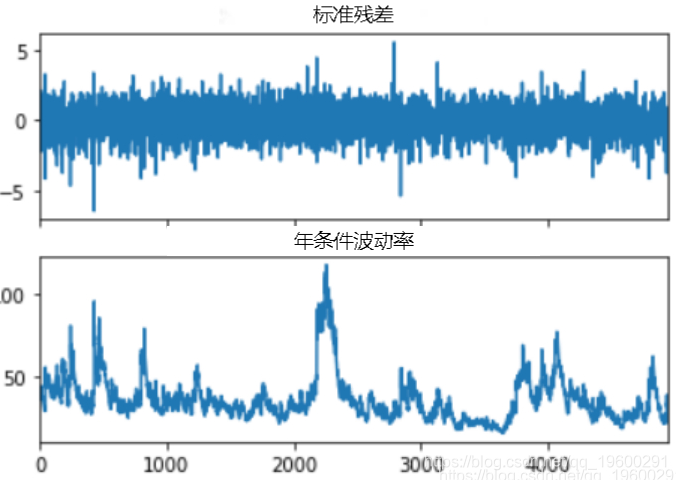
通过将残差除以条件波动率来计算标准化残差。
-
std_resid = resid / conditional_volatility
-
unit_var_resid = resid / resid.std()
标准化残差和条件波动图显示了一些误差,但幅度不大。
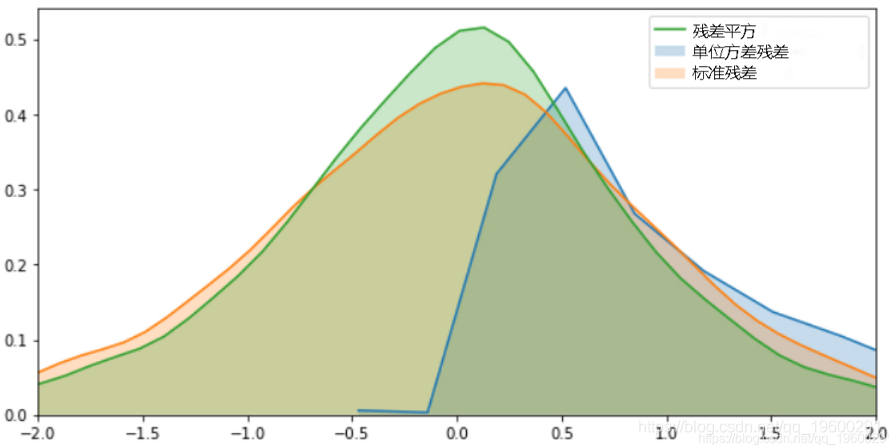
-
-
sns.kdeplot(squared_resid, shade=True)
-
sns.kdeplot(std_resid, shade=True)
-
sns.kdeplot(unit_var_resid, shade=True)
还标绘了标准化残差以及非标准化的残差。残差的平方在中心更加尖峰,表明分布的尾部比标准残差的尾部更重。让我们检查一下ACF图。
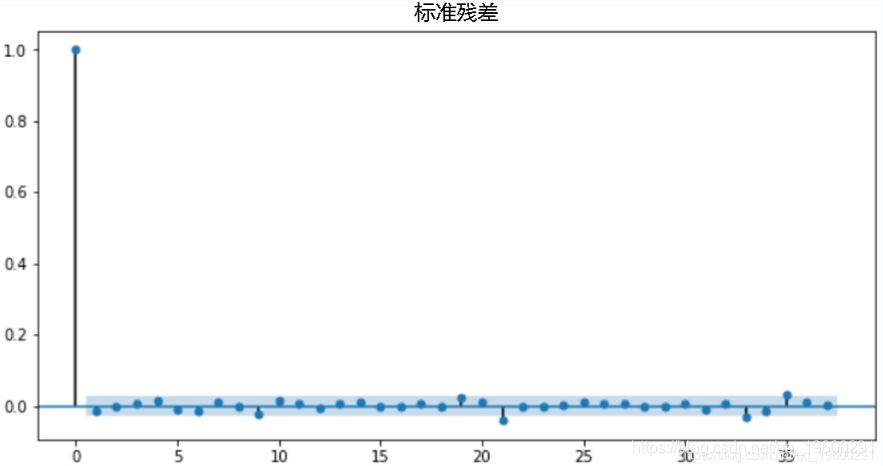
plot_acf(std_resid)
看起来有些尖峰超出了阴影的置信区。让我们查看残差平方。
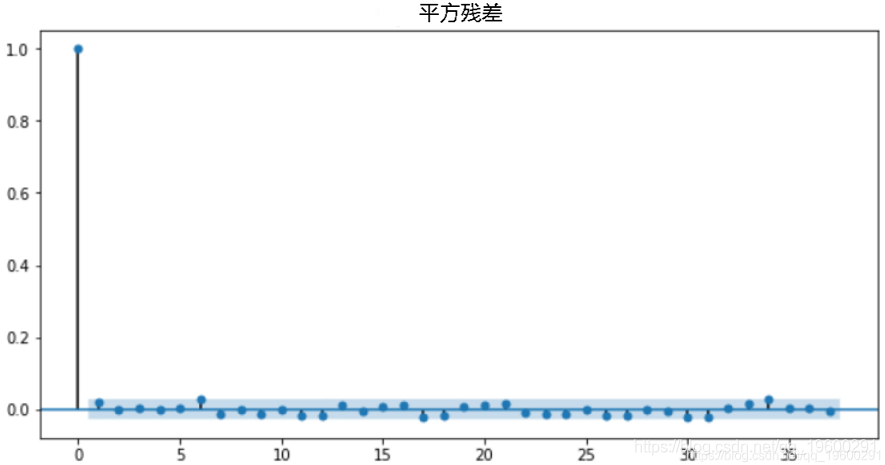
残差平方显示数据点在蓝色阴影的置信度区域(95%)内,表示模型拟合较好。
-
-
res = am.fit()
-
fig = res.hedgehog_plot(type=’mean’)
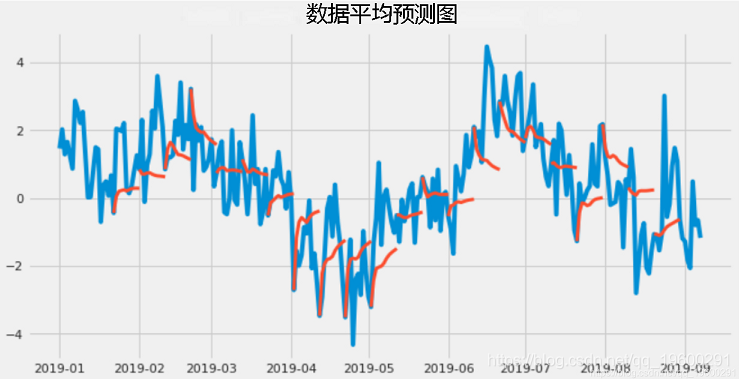
图显示了整个2019年的预测。橙色线表示在不同时间区间的预测。
基于模拟的预测
这里使用基于仿真的方法从EGARCH 模拟中获得预测波动率的置信区间 。要从EGARCH 模型获得波动预测,该 模型是从拟合模型的最后一次观察中模拟得出的。重复此过程很多次,以获得波动率预测。预测点是通过对模拟求平均值来计算的,分别使用模拟分布的2.5%和97.5%的分位数来计算95%的置信区间。考虑平均收益率(mu)为0.0292,年波动率(vol)为(26.48)* sqrt 252 = 37.37%。

-
-
-
#定义变量
-
T = 252 #交易天数
-
mu = 0.0622 #收益
-
vol = 0.3737 #波动率
-
-
daily_returns=np.random.normal((1+mu)**(1/T),vol/sqrt(T),T)
-
-
-
#生成图-价格序列和每日收益的直方图
-
plt.plot(price_list)
-
plt.hist(daily_returns-1, 100)
-
在最上方的图上,根据遵循正态分布的随机每日收益,显示了一个交易年度(252天)内潜在价格序列演变的模拟。第二个图是一年中这些随机每日收益的直方图。但是,可以通过运行成千上万的模拟来获得洞察,每次模拟都基于相同的特征(价格交易量)产生一系列不同的潜在价格演变。
-
-
#设置一个空列表来保存我们每个模拟价格序列的最终值
-
result = []
-
-
S = df.Price[-1] #起始股票价格(即最后可用的实际股票价格)
-
T = 252 #交易天数
-
mu = 0.0622 #收益率
-
vol = 0.3737 #波动率
-
-
#选择要模拟的运行次数-我选择了10,000
-
for i in range(10000):
-
#使用随机正态分布创建每日收益表
-
daily_returns= np.random.normal((1+mu)**(1/T),vol/sqrt(T),T)
-
-
#设定起始价格,并创建由上述随机每日收益生成的价格序列
-
-
-
-
#将每次模拟运行的结束值添加到我们在开始时创建的空列表中
-
result.append(price_list[-1])
-
由于这些是对每日收益的随机模拟,因此此处的结果会略有不同。由于每个模拟中包含的路径,平均值趋向于“ mu”使用的平均收益。下面的直方图显示了价格分布的两个分位数,以了解高收益率或低收益率的可能性。
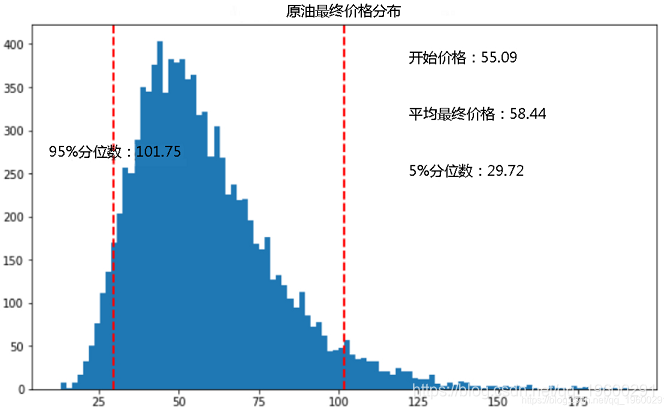
很显然,原油价格有5%的机会最终跌破29.72元,有5%的机会高于101.75美元。
概括
在原油价格高波动的背景下,我研究并提出了混合时变长记忆 GARCH 和基于模拟的预测模型,该模型考虑了诸如非对称性和异方差,时变风险,长记忆和重尾分布等波动事实。经验证据表明,具有布朗运动的原油数据往往在其时间动态方面显示出一定程度的可预测性。这项研究考虑了2000年至2019年的数据,当时股市经历了几次金融危机和危机后阶段。使用此时期的数据训练的模型有望具有出色的预测能力。
当处理长时间波动的原油价格的时间序列数据时,GARCH (2,2)模型估计了方差的持久性 。 进行了蒙特卡洛分析,以检查结果的稳健性。蒙特卡洛 模拟的输出 表明,即使在控制了无关因素之后,结果仍然是可靠的。因此,这些发现提供了出色的混合 EGARCH 和 蒙特卡洛 模拟的的预测模型,其中考虑了波动性特征,如波动性聚类和不对称性,时变风险和重尾分布,来衡量原油价格。

最受欢迎的见解
1.HAR-RV-J与递归神经网络(RNN)混合模型预测和交易大型股票指数的高频波动率
2.R语言中基于混合数据抽样(MIDAS)回归的HAR-RV模型预测GDP增长
4.R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测