原文链接:http://tecdat.cn/?p=21892
引言
多元统计分析 中,交互作用是指某因素作用随其他因素水平的不同而不同,两因素同时存在是的作用不等于两因素单独作用之和(相加交互作用)或之积(相乘交互作用)。通俗来讲就是,当两个或多个因素同时作用于一个结局时,就可能产生交互作用,又称为效应修饰作用(effect modification)。当两个因素同时存在时,所导致的效应(A)不等于它们单独效应相加(B+C)时,则称因素之间存在交互作用。当A=B+C时称不存在交互效应;当A>B+C时称存在正交互作用,又称协同作用(Synergy)。
在一个回归模型中,我们想写的是
![]()
当我们限制为线性模型时,我们写
![]()
或者
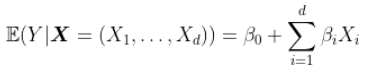
但是我们怀疑是否缺少某些因素……比如,我们错过所有可能的交互影响。我们可以交互变量,并假设
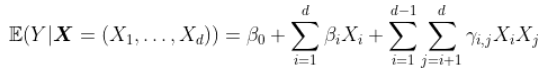
可以进一步扩展,达到3阶
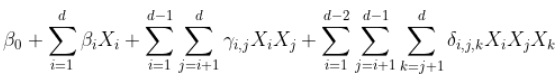
甚至更多。
假设我们的变量 在这里是定性的,更确切地说是二元的。
信贷数据
让我们举一个简单的例子,使用信贷数据集。
Credit数据是根据个人的银行贷款信息和申请客户贷款逾期发生情况来预测贷款违约倾向的数据集,数据集包含24个维度的,1000条数据。
该数据集将通过一组属性描述的人员分类为良好或不良信用风险。
数据集将通过一组属性描述的人员分类为良好或不良信用风险。
建立模型
我们读取数据
db=Credit我们从三个解释变量开始,
-
-
reg=glm(Y~X1+X2+X3,data=db,family=binomial)
-
summary(reg)
没有交互的回归长这样

这里有几种可能的交互作用(限制为成对的)。进行回归时观察到:

交互关系可视化
我们可以画一幅图来可视化交互:我们有三个顶点(我们的三个变量),并且可视化了交互关系
-
-
plot(sommetX,sommetY,cex=1,axes=FALSE,xlab="",ylab="",
-
-
for(i in 1:nrow(indices)){
-
segments(sommetX[indices[i,2]],sommetY[indices[i,2]],
-
text(mean(sommetX[indices[i,2:3]]),mean(sommetY[indices[i,2:3]]),
-
}
-
-
text(sommetX,sommetY,1:k)
这给出了我们的三个变量
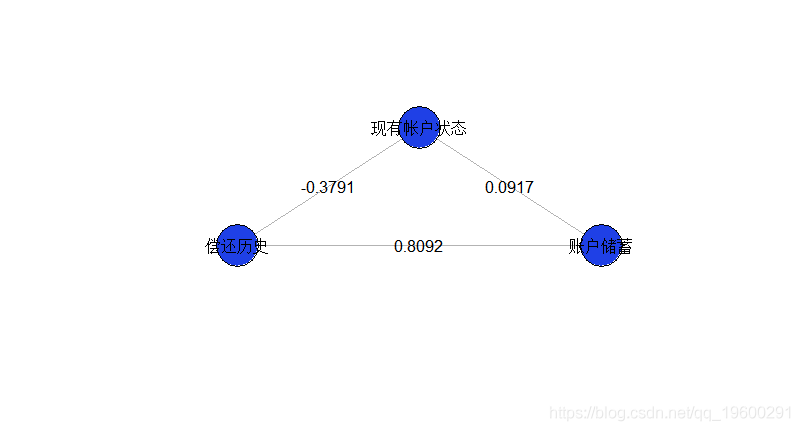
这个模型似乎是不完整的,因为我们仅成对地看待变量之间的相互作用。实际上,这是因为(在视觉上)缺少未交互的变量。我们可以根据需要添加它们
-
-
reg=glm(Y~X1+X2+X3+X1:X2+X1:X3+X2:X3,data=db,family=binomial)
-
k=3
-
theta=pi/2+2*pi*(0:(k-1))/k
-
plot(X,Y
-
for(i in 1:nrow(indices)){
-
segments(X[indices[i,2]],Y[indices[i,2]],
-
for(i in 1:k){
-
cercle(c(cos(theta)[i]*1.18,sin(theta)[i]*1.18),.18)
-
text(cos(theta)[i]*1.35,sin(theta)[i]*1.35,
-
points(X,Y,cex=6,pch=1)
这里得到
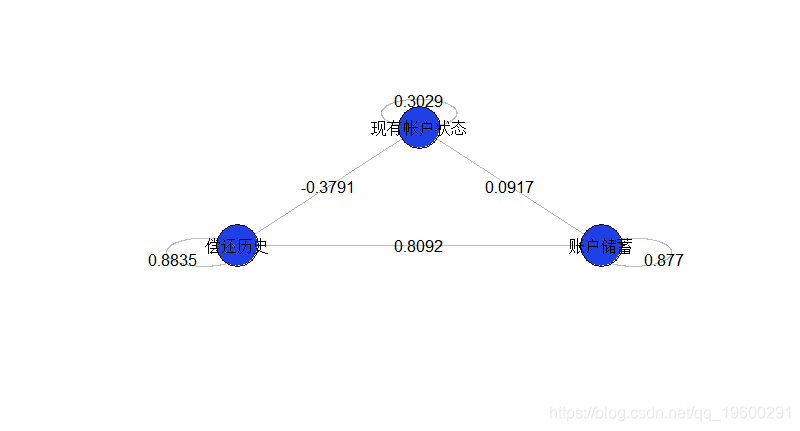
如果我们更改变量的“含义”(通过重新编码,通过排列真值和假值),将获得下图
-
-
glm(Y~X1+X2+X3+X1:X2+X1:X3+X2:X3,data=dbinv,family=binomial)
-
plot(sommetX,sommetY,cex=1
-
for(i in 1:nrow(indices)){
-
segments(sommetX[indices[i,2]]
-
for(i in 1:k){
-
cercle(c(cos(theta)[i]*1.18,sin(theta)[i]*1.18)
-
-
points(sommetX,sommetY,cex=6,pch=19)
然后可以将其与上一张图进行比较
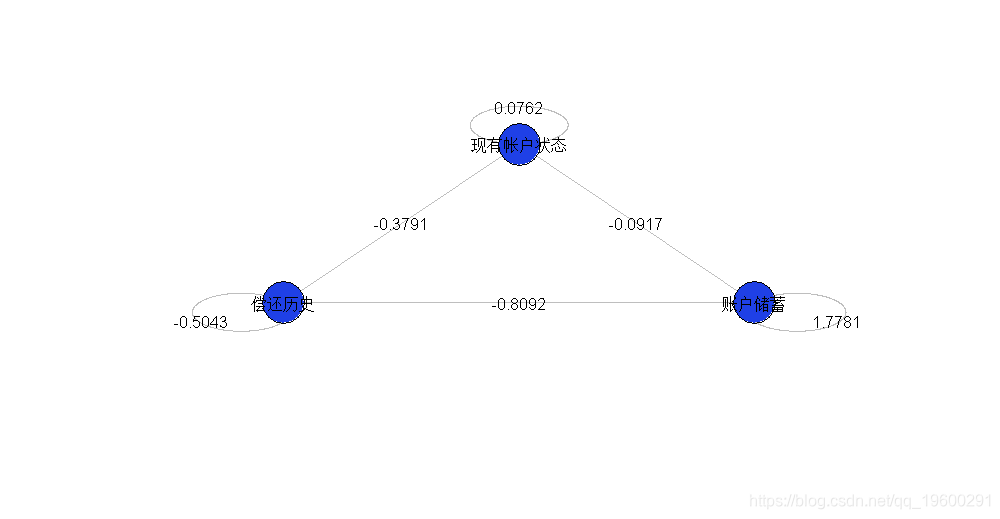
使用5个变量,我们增加了可能的交互作用。
然后,我们修改前面的代码
-
-
formule="Y~1"
-
for(i in 1:k) formule=paste(formule,"+X",i,sep="")
-
for(i in 1:nrow(indices)) formule=paste(formule,"+X",indices[i,2],":X",indices[i,3],sep="")
-
reg=glm(formule,data=db,family=binomial)
-
plot(sommetX,sommetY,cex=1
-
for(i in 1:nrow(indices)){
-
segments(sommetX[indices[i,2]],sommetY[indices[i,2]],
-
for(i in 1:k){
-
cercle(c(cos(theta)[i]*1.18,sin(theta)[i]*1.18)
-
points(sommetX,sommetY,cex=6
给出了更复杂的图,
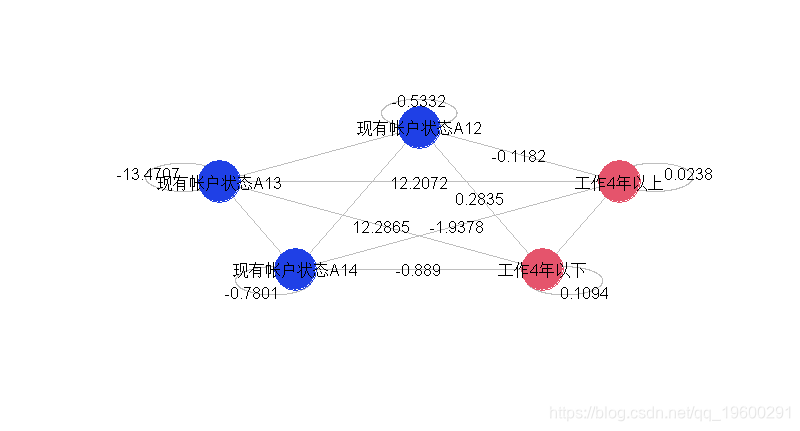
我们也可以只采用2个变量,分别取3和4种指标。为第一个提取两个指标变量(其余形式为参考形式),为第二个提取三个指标变量,
-
formule="Y~1"
-
for(i in 1:k) formule=paste(formule,"+X",i,sep="")
-
for(i in 1:nrow(indices)formule=paste(formule,"+X",indices[i,2],":X",indices[i,3],sep="")
-
reg=glm(formule,data=db,family=binomial)
-
for(i in 1:nrow(indices){
-
if(!is.na(coefficients(reg)[1+k+i])){
-
segments(X[indices[i,2]],Y[indices[i,2]],
-
}
-
for(i in 1:k){
-
cercle(c(cos(theta)[i]*1.18,sin(theta)[i]*1.18),.18)
-
text(cos(theta)[i]*1.35,sin(theta)[i]*1.35,
-
}
我们看到,在左边的部分(相同变量的三种指标)和右边的部分不再有可能发生交互作用。
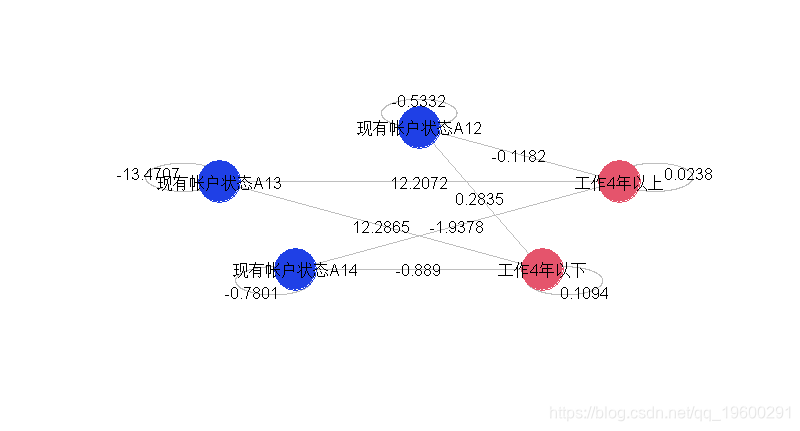
我们还可以通过仅可视化显著交互来简化图形。
-
-
for(i in 1:nrow(indices)){
-
if(!is.na(coefficients(reg)[1+k+i])){
-
if(summary(reg)$coefficients[1+k+i,4]<.1){
-
-
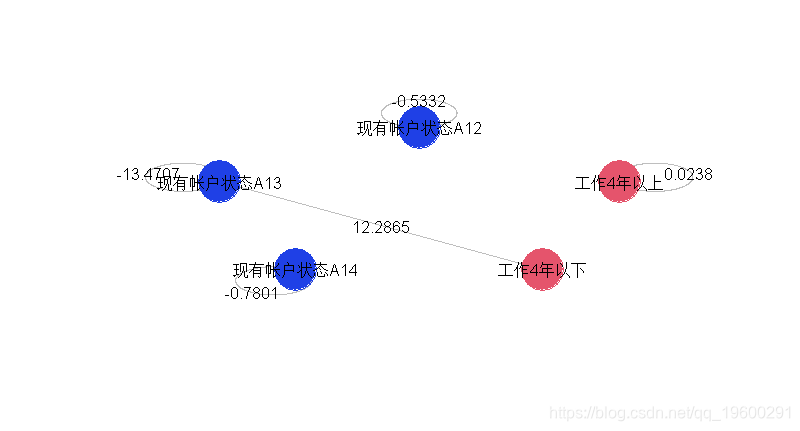
在这里,只有一个交互作用是显著的,几乎所有的变量都是显著的。如果我们用5个因子重新建立模型,
-
-
for(i in 1:nrow(indices))
-
formule=paste(formule,"+X",indices[i,2],":X",indices[i,3],sep="")
-
reg=glm(formule,data=db,family=binomial)
-
-
for(i in 1:nrow(indices){
-
if(!is.na(coefficients(reg)[1+k+i])){
-
if(summary(reg)$coefficients[1+k+i,4]<.1){
-
-
我们得到
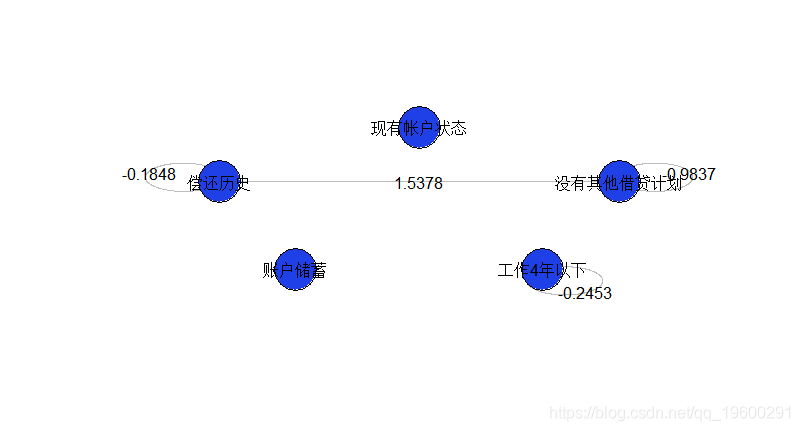

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
5.R语言回归中的Hosmer-Lemeshow拟合优度检验