原文链接:http://tecdat.cn/?p=22262
在讨论分类时,我们经常分析二维数据(一个自变量,一个因变量)。但在实际生活中,有更多的观察值,更多的解释变量。随着两个以上的解释变量,它开始变得更加复杂的可视化。
数据
我们使用心脏病数据,预测急诊病人的心肌梗死,包含变量:
- 心脏指数
- 心搏量指数
- 舒张压
- 肺动脉压
- 心室压力
- 肺阻力
- 是否存活
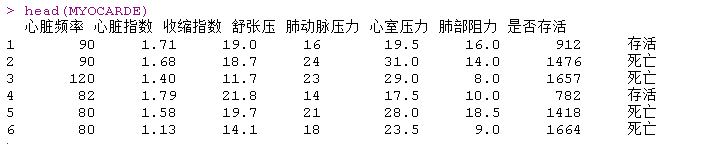
其中我们有急诊室的观察结果,对于心肌梗塞,我们想了解谁存活下来了,以得到一个预测模型。但是在运行一些分类器之前,我们先把我们的数据可视化。
主成分PCA
由于我们有7个解释变量和我们的因变量(生存或死亡),我们可以去做一个PCA。
-
-
acp=PCA(X)
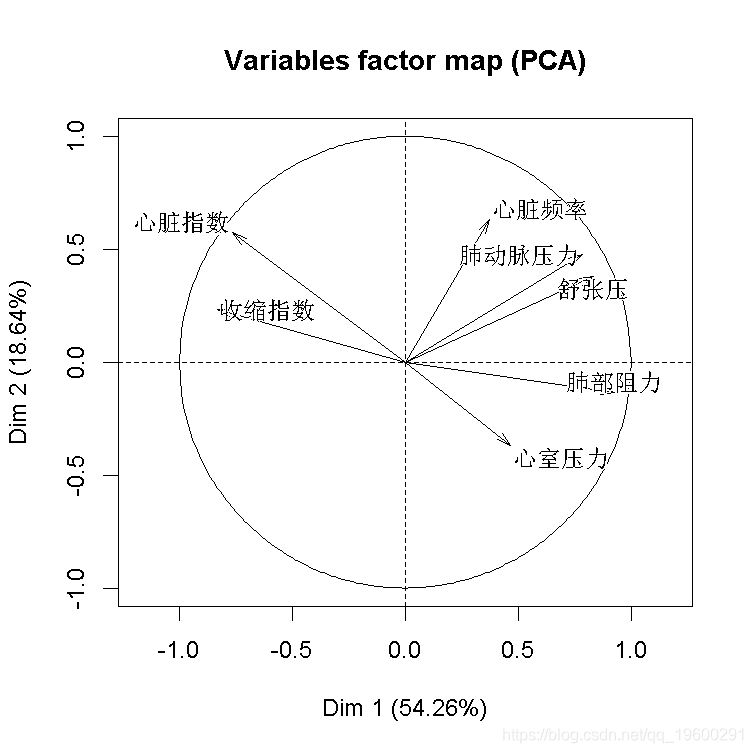
添加死亡生存变量,就把它当作数字0,1变量。
是否存活= 是否存活=="存活")*1
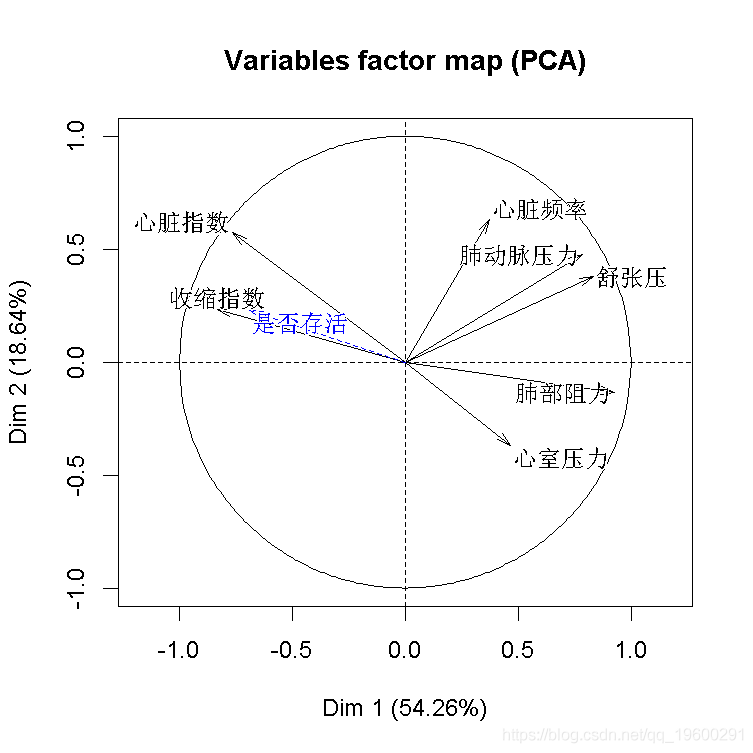
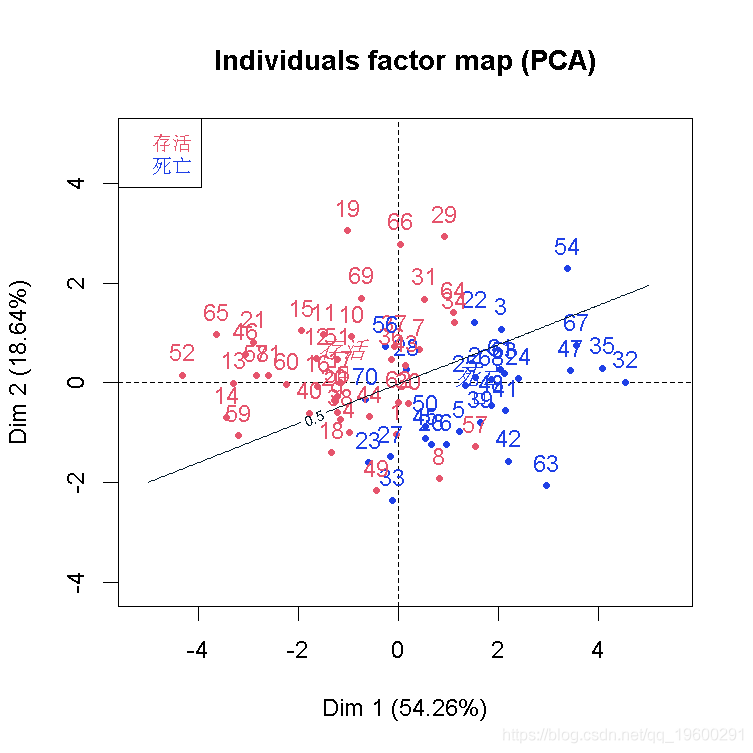
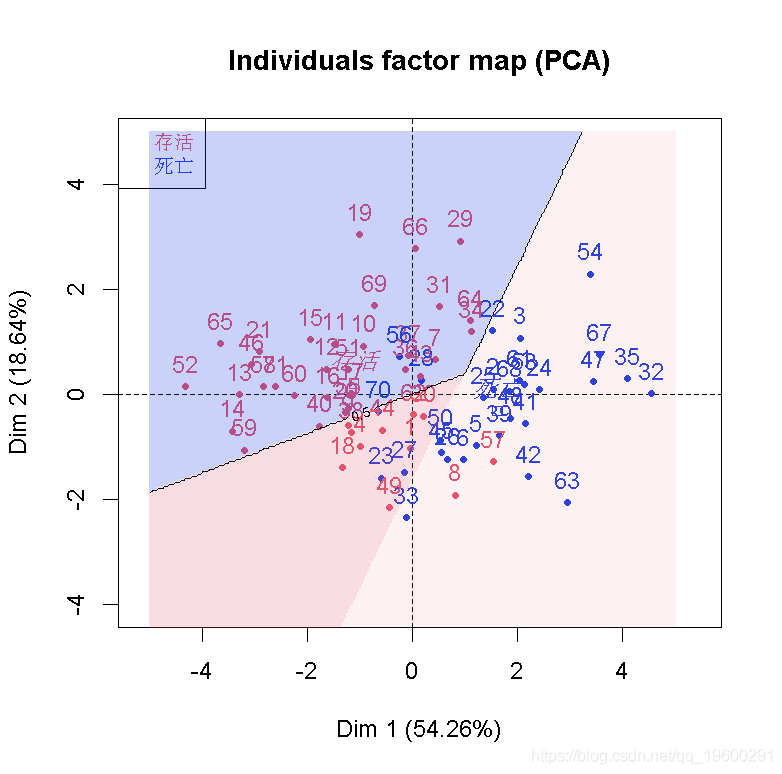
结果不错,我们看到因变量与部分自变量是同向的。也可以可视化样本和类别
plot(cp )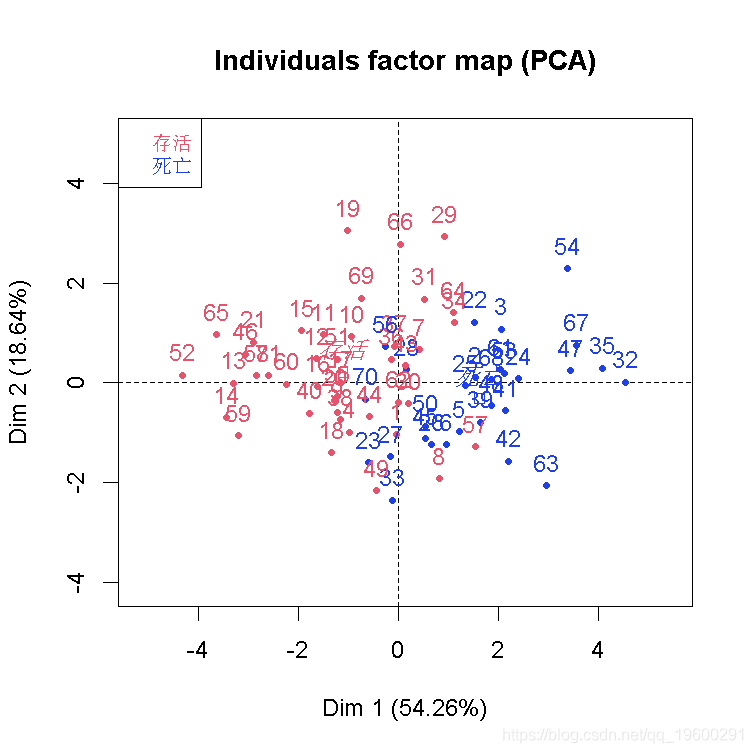
我们可以在这里推导出一个不错的分类器。至少,在前两个成分上投影时,我们可以看到我们的类别。
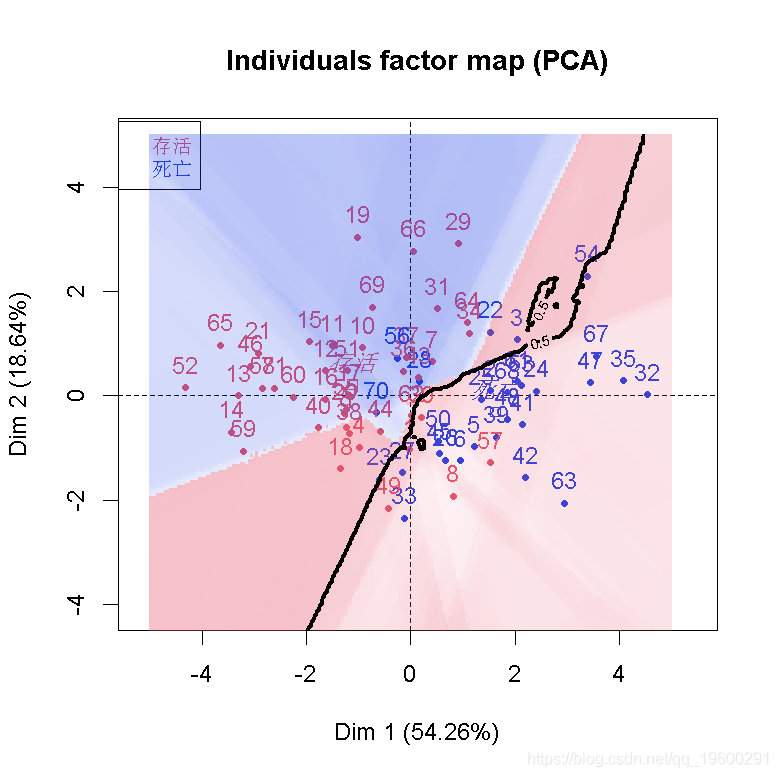
现在,我们不能在前两个主成分上得到一个分类器并将其可视化吗? 因为PCA是简单的基于正交投影的,所以我们可以(这里的数据是标准化的)。给定前两个分量平面上的两个坐标,给定我们的变换矩阵、归一化分量和一个分类器(这里是基于逻辑回归),我们可以回到原始空间,并对新数据进行分类。
-
PCA(X,ncp=ncol(X))
-
function(d1,d2,Mat,reg){
-
z=Mat %*% c(d1,d2,rep(0,ncol(X)-2))
-
newd=data.frame(t(z*s+m))
-
pred(reg, newd }
逻辑回归
现在考虑一个逻辑回归。只是为了简化(去掉非显著变量),我们使用一个逐步回归的程序来简化模型。
-
-
reg_tot=step(glm(是否存活~. ,
-
family=binomial))

可视化等概率线(如个人有50%的生存机会)使用以下
-
-
xgrid=seq(-5,5,length=25 )
-
ygrid=seq(-5,5,length=25 )
-
zgrid=ter(xgrid,ygrid,p)
然后,我们在之前的图形上添加一条等高线
-
PCA(data,quali.sup=8 )
-
-
contour( zgrid )
结果不差,但我们应该可以做得更好。如果我们把所有的变量都保留在这里(即使它们不重要),会怎么样呢?
-
glm(是否存活~.,
-
family=binomial)
-
-
contour(xgrid,ygrid,zgrid )
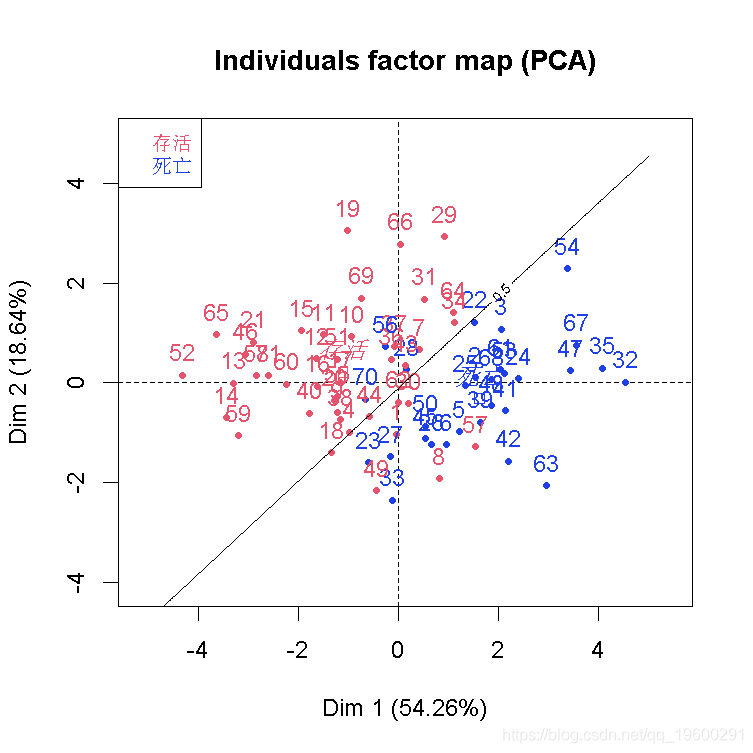
在现实生活中,要想真正说出我们的分类器的一些相关信息,我们应该在观测值的一个子集上拟合我们的模型,然后在另一个子集上测试它。在这里,我们的目标更多的是在某个投影空间上得到一个函数来可视化我们的分类。
决策树
默认分类树
> plot( re,type=4,extra=6)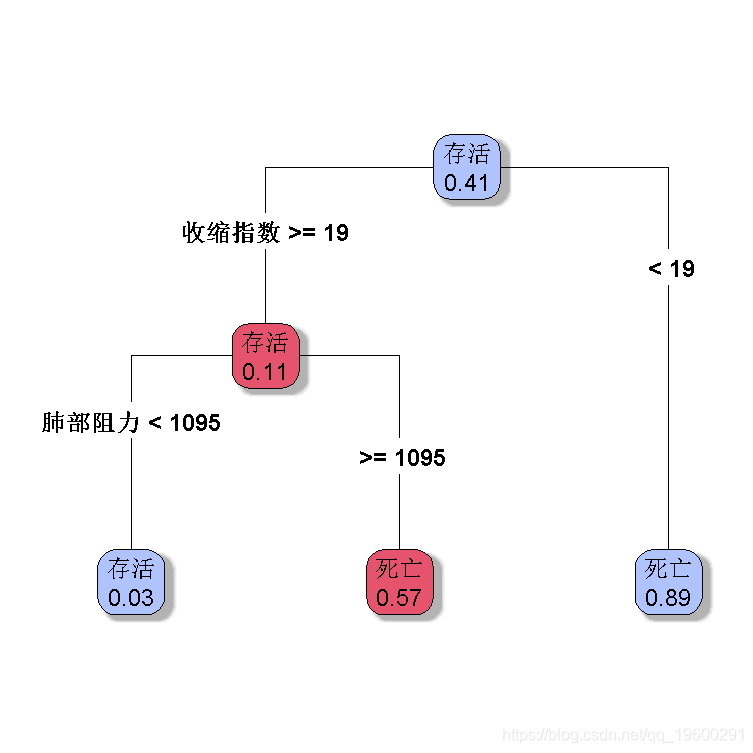
我们可以在此更改选项,例如每个节点的最小观察数
-
rpart(factor(是否存活)~ ,
-
+ control=rpart.control(minsplit=10))
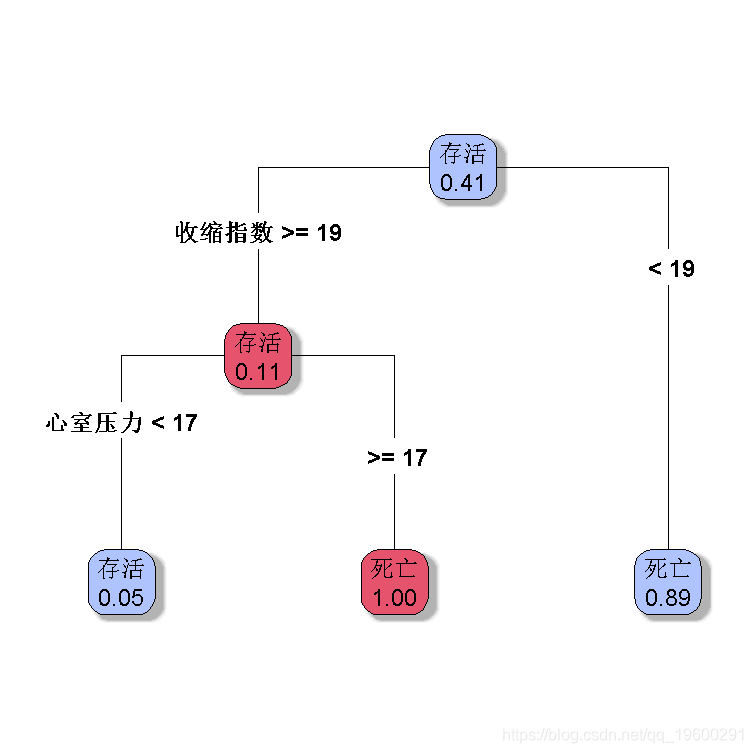
或者
-
rpart(
-
+ control=rpart.control(minsplit=5))
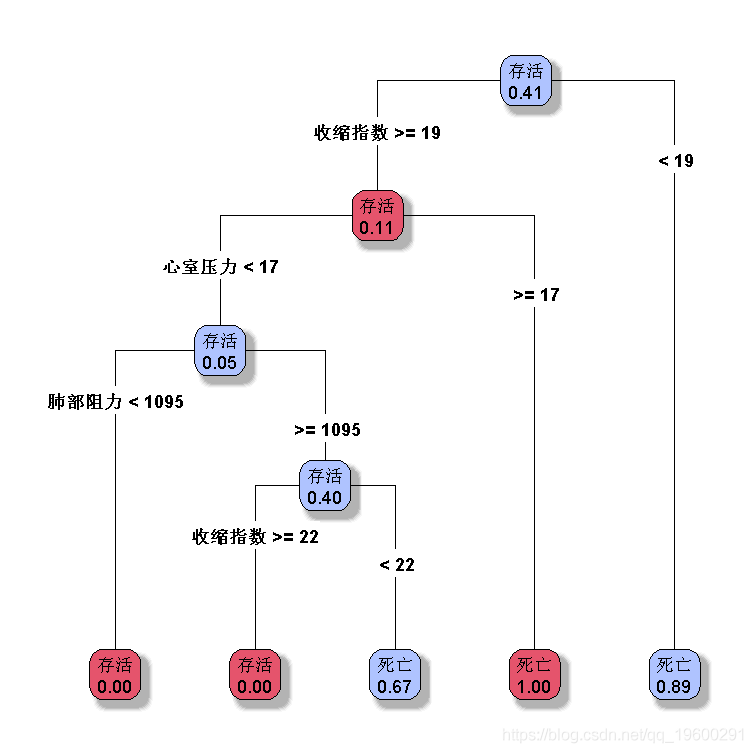
要将该分类可视化,获得前两个成分的投影
-
-
> p=function(d1,d2) pred2(d1,d2 )
-
-
> zgrid=Outer(xgrid,ygrid,p)
-
PCA( quali.sup=8,graph=TRUE)
-
> image(xgrid,ygrid,zgrid )
-
> contour(xgrid,ygrid,zgrid,add=TRUE,levels=.5)
也可以考虑这种情况
rpart( control=rpart.control(minsplit=5))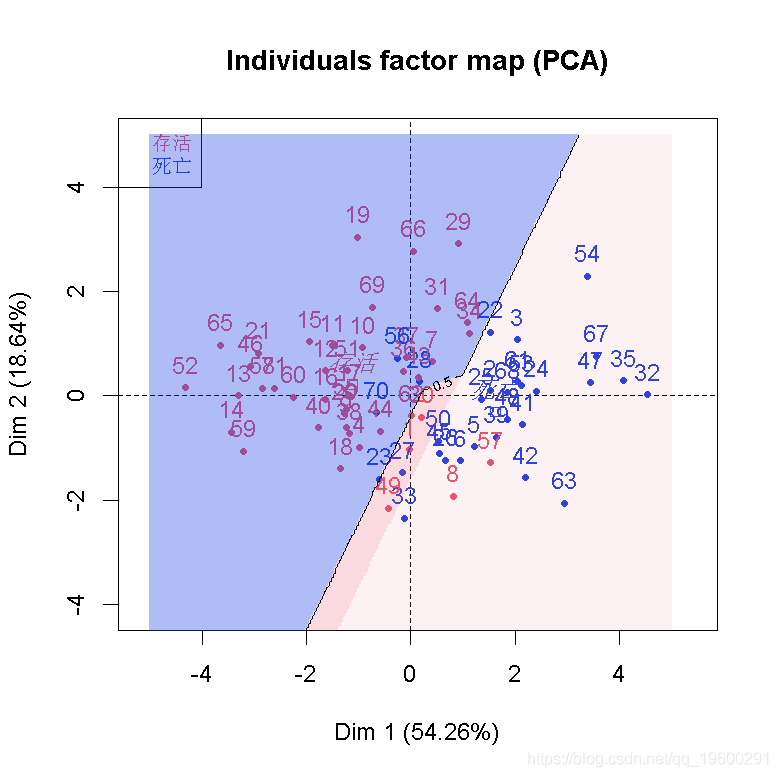
最后,我们还可以生成更多的树,通过采样获得。这就是bagging的概念:我们boostrap 观测值,生长一些树,然后,我们将预测值进行汇总。在网格上
-
-
> for(i in 1:1200){
-
+ indice = sample(1:nrow(MYOCARDE),
-
+ arbre_b = rpart(factor(是否存活)~.,
-
+}
-
>Zgrid = Z/1200
可视化
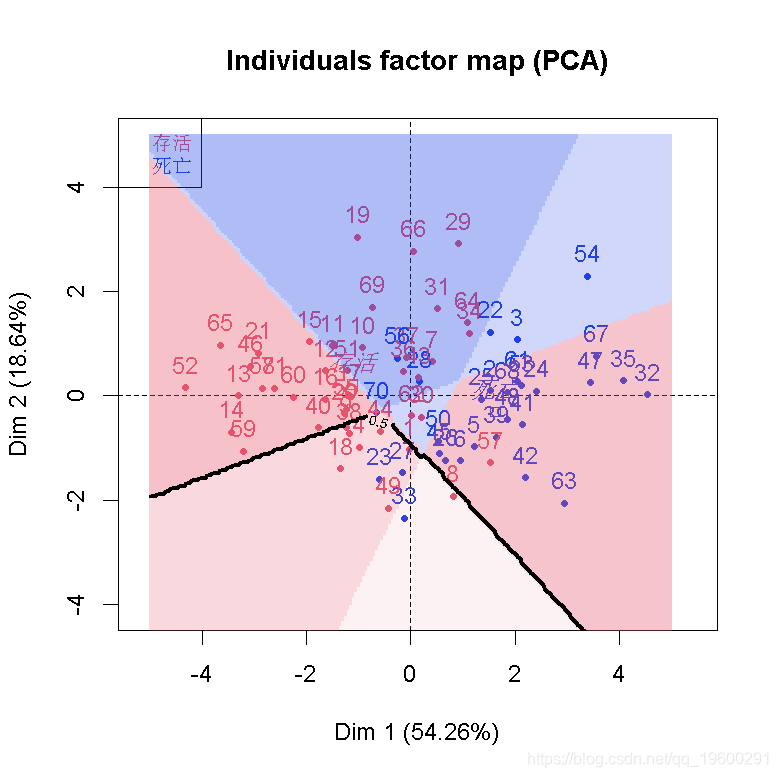
随机森林
最后,可以使用随机森林算法。
-
> fore= randomForest(factor(是否存活)~.,
-
> pF=function(d1,d2) pred2(d1,d2,Minv,fore)
-
> zgridF=Outer(xgrid,ygrid,pF)
-
PCA(data,.sup=8,graph=TRUE)
-
> image(xgrid,ygrid,Zgrid,add=TRUE,
-
> contour(xgrid,ygrid,zgridF,

最受欢迎的见解
3.python中使用scikit-learn和pandas决策树
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用