原文链接:http://tecdat.cn/?p=22588
原文出处:拓端数据部落公众号
今天我们将计算投资组合收益的CAPM贝塔。这需要拟合一个线性模型,得到可视化,从资产收益的角度考虑我们的结果的意义。
简单的背景介绍,资本资产定价模型(CAPM)是由威廉·夏普(William Sharpe)创建的一个模型,它根据市场收益和资产与市场收益的线性关系来估算资产的收益。这种线性关系就是股票的贝塔系数。
计算CAPM的betas可以作为一个团队工作中更复杂的模型的一个很好的模板。
我们将专注于CAPM的一个特定方面:β值。正如我们上面所指出的,贝塔系数是指一项资产的收益率回归到市场收益率的结果。它抓住了资产与市场之间的线性关系
在计算该投资组合的贝塔值之前,我们需要找到投资组合的月度收益率。
-
-
pri <-
-
getSymbols(symbols, src = 'yahoo',
-
from = "2013-01-01",
-
to = "2017-12-31",
-
auto.assign = TRUE, warnings = FALSE) %>%
-
monthly <- to.monthly(pri
我们将两个投资组合收益和一个资产收益一起分析。
CAPM和市场收益
我们的第一步是做出选择,用哪种资产作为市场收益的代理,我们将选择SPY ETF,将标准普尔500指数视为市场收益。
让我们计算一下SPY的市场收益。注意开始日期是 "2013-01-01",结束日期是 "2017-12-31",所以我们将使用五年的收益。
-
getSymbols("SPY",
-
src = 'yahoo',
-
from = "2013-01-01",
-
to = "2017-12-31",
-
auto.assign = TRUE,
-
warnings = FALSE) %>%
-
-
return <-
-
Return.calculate(monthl, method = "log") %>%
我们还想要一个市场收益率的data.frame对象,并转换xts对象。
-
returns_tidy <-
-
returns_xts %>%
-
tk_tbl(preserve_index = TRUE, rename_index = "date") %>%
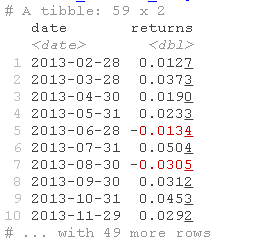
我们有一个market_returns_tidy对象。我们确保它的周期性与投资组合周期一致
-
monthly %>%
-
mutate(market_returns = returns_tidy$returns) %>%
-
head()
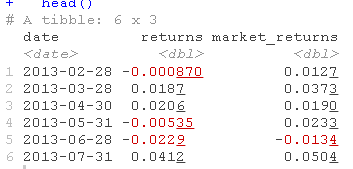
如果周期性不一致,mutate()就会抛出一个错误。
计算CAPM贝塔
计算投资组合的β值,首先让我们看看这个方程式。
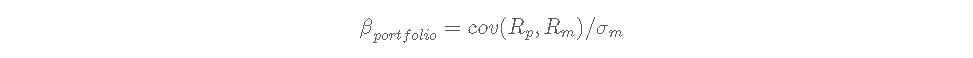
投资组合β等于投资组合收益和市场收益的协方差,除以市场收益的方差。
我们可以用cov计算分子,即投资组合和市场收益的协方差,用var计算分母。
我们的投资组合β值等于。
cov(monthly,returns)/var(returns)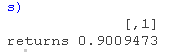
这个β值相当接近于1,毕竟SPY是这个投资组合的一个重要部分。
我们也可以通过找到我们每个资产的贝塔值,然后乘以资产权重来计算组合贝塔值。也就是说,投资组合贝塔值的另一个方程式是资产贝塔值的加权和。
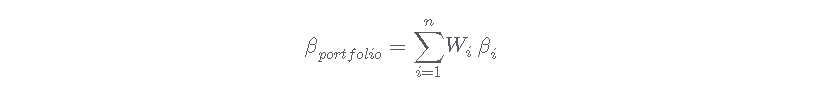
为了在R中使用这种方法,我们首先要找到我们每个资产的β值。
我们需要将每项资产的收益率回归到市场收益率上。我们可以用lm()对资产1进行回归,然后再用lm()对资产2进行回归,等等。但如果我们有一个50个资产的投资组合,这将是不现实的。相反,我们写一个代码流程,使用map()来回归我们所有的资产,并通过一次调用计算betas。
我们将从我们的returns_long整齐的数据框架开始。
assets
nest(-asset)改变了我们的数据框架,所以有两列:一列叫做asset,保存我们的资产名称,一列叫做data,保存每个资产的收益列表。现在我们已经将收益列表 "嵌套 "在一列中。
现在我们可以使用map()对每个嵌套的列表应用一个函数,并通过mutate()函数将结果存储在一个新的列中。整个管道命令是mutate(model = map(, ~ lm())
-
long %>%
-
-
mutate( map(data, ~ lm(returns ~ returns)
-
assets

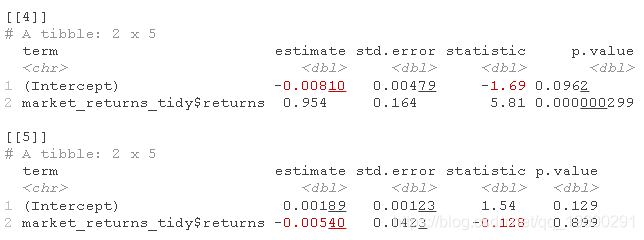
我们现在有三列:之前的资产,之前的数据,以及我们刚刚添加的模型。模型一栏是我们对每项资产进行回归的结果lm( )。这些结果是我们每个资产的β值和截距。
让我们用tidy()函数整理一下我们的结果。我们想将该函数应用于我们的模型列,并将再次使用mutate()和map()组合。
-
mutate(model = map(data, ~ lm(returns ~ returns)) %>%
-
mutate(model = map(model, tidy))

我们现在已经很接近了,但是模型栏里有嵌套的数据框。它们是格式化很好的数据框架。
beta_assets$model
不过,我不喜欢最终出现嵌套的数据框架,所以我们调整模型列。
-
mutate(model = map(data, ~ lm(returns ~returns)) %>%
-
unnest(model)
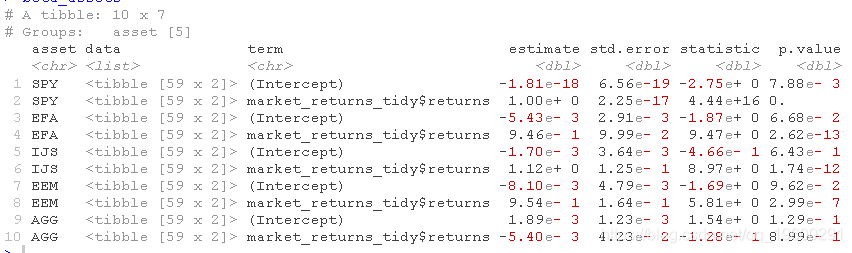
现在,这看起来比较整洁。我们将做进一步的清理,去掉截距,因为我们需要贝塔值。
-
-
mutate(map( ~ lm(returns ~ returns)) %>%
-
filter(term == "returns") %>%

快速检查应该发现SPY与自身的贝塔为1。
bet %>% filter(asset == "SPY")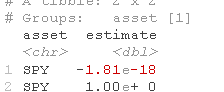
现在让我们看看我们对这些资产的组合如何影响投资组合的β值。
让我们按照上面的选择来分配投资组合的权重。
现在我们可以使用这些权重来获得我们的投资组合的β值,基于每个资产的β值。
-
-
w[1] * beta$estimate[1] +
-
w[2] * beta$estimate[2] +
-
w[3] * beta$estimate[3] +
-
w[4] * beta$estimate[4] +
-
w[5] * beta$estimate[5]
-
这个贝塔值与我们上面用协方差/方差法计算的是一样的,现在我们知道投资组合收益和市场收益的协方差除以市场收益的方差等于我们把每项资产的收益回归到市场收益上得到的加权估计。
xts计算CAPM的Beta值
使用内置CAPM.beta()函数。该函数需要两个参数:我们希望计算其β值的投资组合(或任何资产)的收益,以及市场收益。
CAPM.beta(_monthly, returns_xts)
![]()
在Tidyverse中计算CAPM Beta
首先,我们将使用dplyr来抓取我们的投资组合贝塔。我们稍后会进行一些可视化,但现在将提取投资组合的β值。
为了计算贝塔值,我们调用do(model = lm())。然后我们使用tidy()函数,使模型结果更容易看懂。
-
do(model = lm(returns ~return)) %>%
-
mutate(term = c("alpha", "beta"))

Tidyquant计算CAPM的β值
使用tidyquant函数。能够将CAPM.beta()函数应用于一个数据框架。
-
-
tq_performance(Ra = returns,
-
Rb = return,
-
performance_fun = CAPM.beta)
![]()
稳定的结果和接近1的贝塔值是比较理想的,因为我们的投资组合有25%分配给标准普尔500指数。
CAPM beta的可视化
在可视化之前,我们需要计算投资组合的收益,然后计算投资组合涉及到的单个资产的CAPMβ。
可视化投资组合收益、风险和市场收益之间的关系
CAPM的β值告诉我们投资组合收益与市场收益之间的线性关系。它还告诉我们投资组合的风险性--投资组合相对于市场的波动程度。在我们讨论贝塔系数本身之前,让我们先看看我们的资产的预期月度收益与我们个别资产的月度风险的对比。
-
-
ggplot(aes(x = sdev, y = ex_return)) +
-
geom_point(size = 2) +
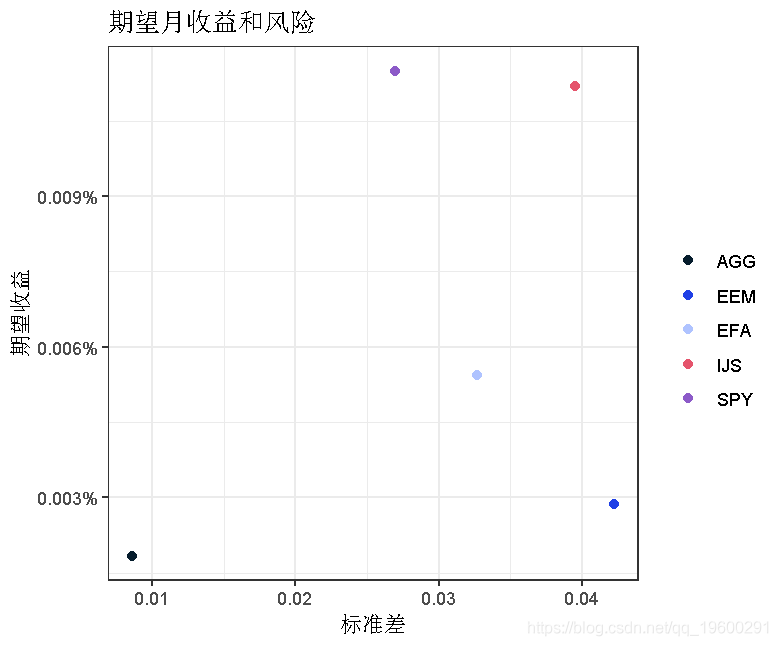
我们的投资组合在这个散点图上的位置如何?让我们用geom_point()把它添加到ggplot()中。
-
-
ggplot(aes(x = stdev, y = expreturn)) +
-
geom_point(size = 2) +
-
geom_point(aes(x = sd(returns),
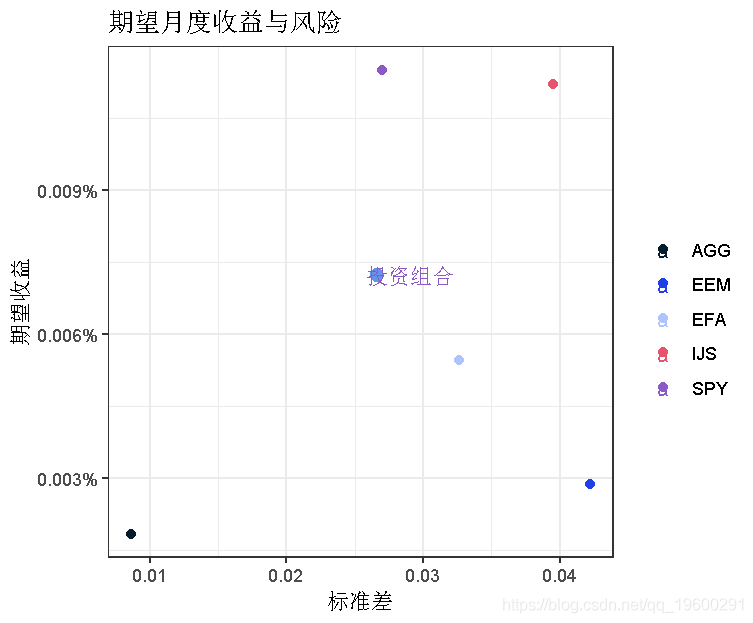
我们的投资组合收益/风险看起来都不错,尽管SP500指数的预期收益率更高,只是风险更大一些。在过去的五年里,要战胜市场是很困难的。EEM和EFA有较高的风险和较低的预期收益,而IJS有较高的风险和较高的预期收益。
一般来说,散点是为我们的投资组合提供一些收益-风险的背景。它不是CAPM的直接组成部分。
接下来,让我们更直接地转向CAPM,用X轴上的市场收益和Y轴上的投资组合收益的散点图来直观地显示我们的投资组合与市场之间的关系。首先,我们将通过调用mutate()将市场收益添加到我们的投资组合tibble中。然后,我们用ggplot()设置我们的x轴和y轴。
-
-
ggplot(aes(x = market_returns, y = returns)) +
-
geom_point() +
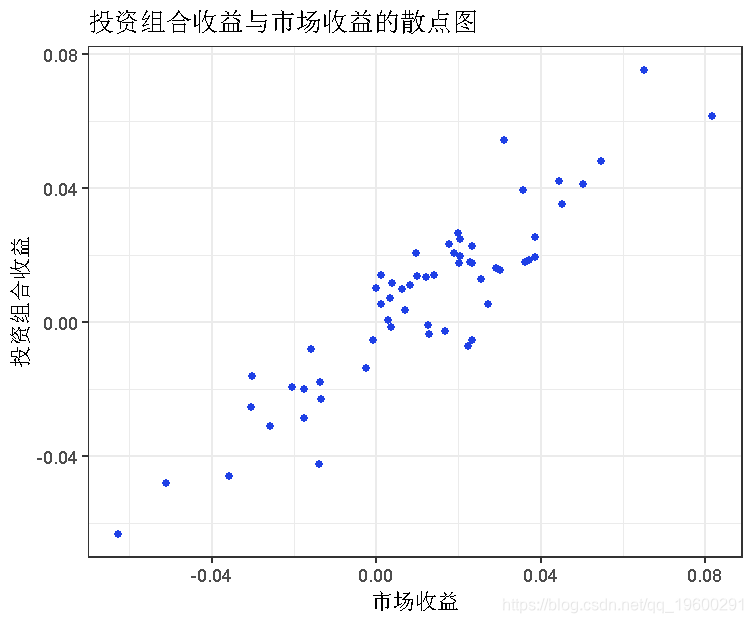
这个散点图与β计算传达了相同的强线性关系。我们可以用geom_smooth()给它添加一个简单的回归线。
-
ggplot(aes(x = market_returns, y = returns)) +
-
geom_point() +
-
geom_smooth(method = "lm") +
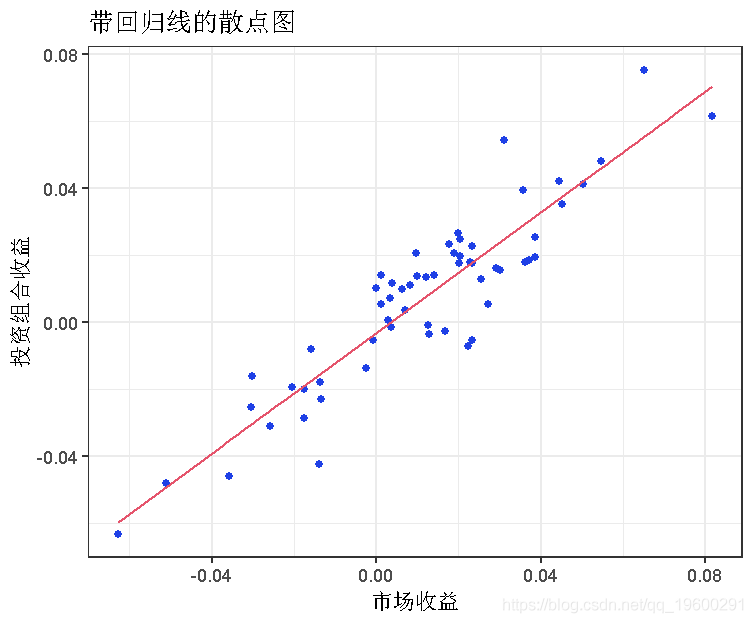
线性回归
在结束CAPM beta的分析之前,让我们来探讨一下如何创建更有趣的可视化数据。
下面的代码块从lm()的模型结果开始,它将我们的投资组合收益率回归到市场收益率上。我们将结果存储在一个名为model的列表列中。接下来,我们调用augment(),将预测值添加到原始数据集,并返回一个tibble。
这些预测值将被放在.fitted列中。
-
-
do(model = lm(returns ~ returns)%>%
-
augment(model) %>%
-
mutate(date = date)
-
head(portfolio_model)

让我们用ggplot()来看看拟合的收益值与实际收益值的匹配程度。
-
-
ggplot(aes(x = date)) +
-
geom_line(aes(y = returns, color = "actual returns")) +
-
geom_line(aes(y = .fitted, color = "fitted returns")) +
-
scale_colour_manual("",
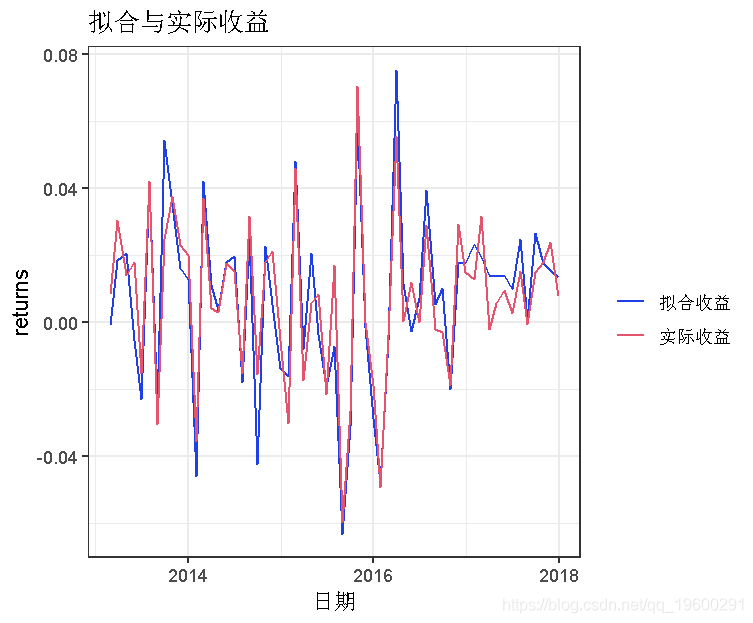
这些月度收益和拟合值似乎重合得不错。让我们把实际收益和拟合收益都转换为一元的增长,并进行同样的比较。
-
-
ggplot(aes(x = date)) +
-
geom_line(aes()) +
-
geom_line(aes)) +
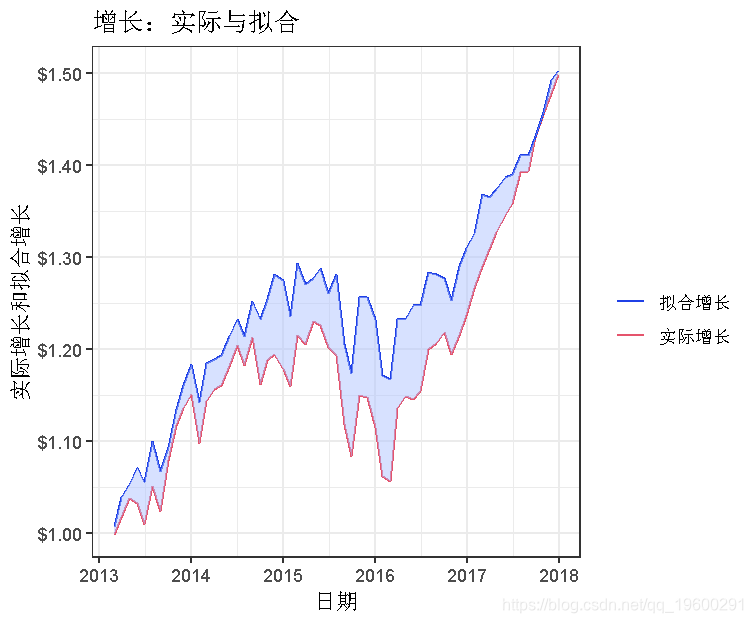
我们的拟合增长很好地预测了我们的实际增长,尽管在大部分时间里,实际增长低于预测值。
参考文献
The Capital Asset Pricing Model: Theory and Evidence Eugene F. Fama and Kenneth R. French, The Capital Asset Pricing Model: Theory and Evidence, The Journal of Economic Perspectives, Vol. 18, No. 3 (Summer, 2004), pp. 25-46

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析