原文链接:http://tecdat.cn/?p=23869
原文出处:拓端数据部落公众号
1 引言
在比较性的纵向临床研究中,主要终点往往是发生特定临床事件的时间,如死亡、心衰住院、肿瘤进展等。风险比例估计值几乎被常规用于量化治疗差异。然而,当基础模型假设(即比例危害假设)被违反时,这种基于模型的组间总结的临床意义可能相当难以解释,而且很难保证模型的建立在经验上的正确。例如,拟合度检验的非显著性结果并不一定意味着风险比例假设是 "正确的"。基于限制性平均生存时间(RMST)的组间总结指标是风险比例或其他基于模型的措施的有用替代方法。本文说明了如何使用该包中的函数来比较两组限制平均生存时间。
2 样本数据
在这个文章中,我们使用了梅奥诊所进行的原发性胆汁性肝硬化(pbc)研究中的部分数据,该研究包括在R语言的生存包中。
-
> library(survival)
-
> ?pbc
生存包中的原始数据由418名患者的数据组成,其中包括参加了随机临床试验的患者和没有参加的患者。在下面的说明中,我们只使用了312个参加了随机试验的病例(158个病例在Dpenicillamine组,154个病例在安慰剂组)。从原始数据文件中选择子集。
-
-
> head(D[,1:3])
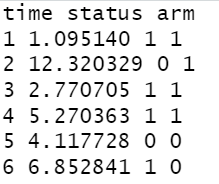
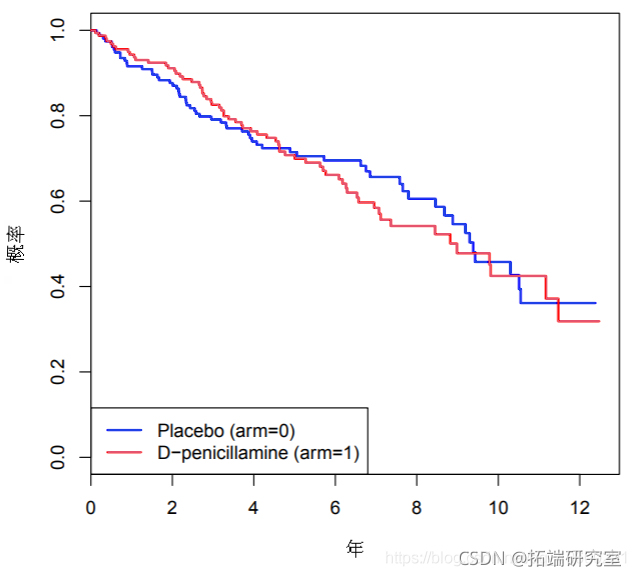
这里,时间是指从登记到死亡或最后已知活着的年数,状态是事件的指标(1:死亡,0:审查),臂膀是治疗分配指标(1:Dpenicillamin,0:安慰剂)。下面是每个实验组的死亡时间的卡普兰-梅尔(KM)估计。
3 限制平均生存时间(RMST)和限制平均损失时间(RMTL
RMST被定义为生存函数曲线下的面积,直到一个时间τ(< ∞)。
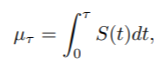
其中S(t)是所关注的时间-事件变量的生存函数。对RMST的解释是:"当我们对患者进行τ的随访时,患者平均会存活μτ",这是对删减的生存数据的相当直接和有临床意义的总结。如果没有删减的观察值,我们可以使用平均生存时间
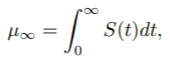
而不是μτ。对μτ的一个自然估计是
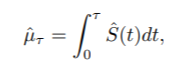
其中Sˆ(t)是S(t)的KM估计。ˆµτ的标准误差也是用分析法计算的;详细的公式在[3]中给出。请注意,即使在重度删减的情况下,μτ也是可以估计的。另一方面,尽管中位生存时间S-1(0.5)也是生存时间分布的一个稳健总结,但由于严重删减或罕见事件,当KM曲线没有达到0.5时,它变得不可估计。
RMTL被定义为截止到某一时间τ的生存函数曲线 "上方 "的面积。
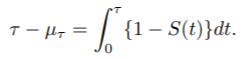
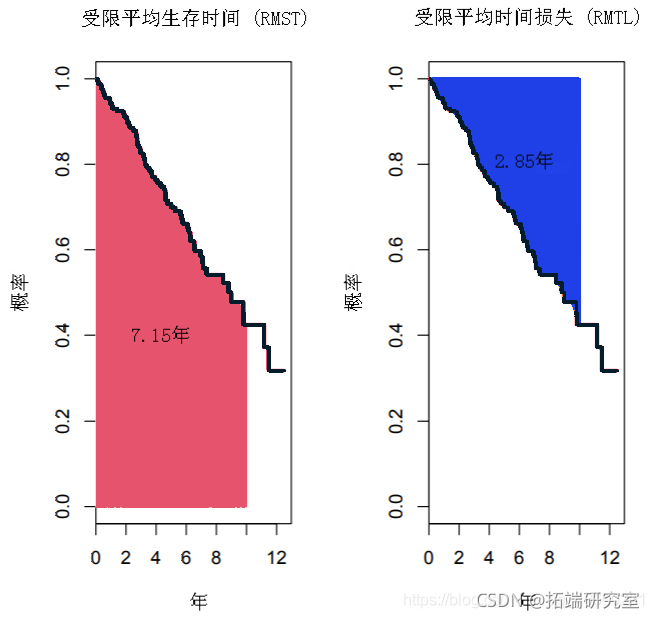
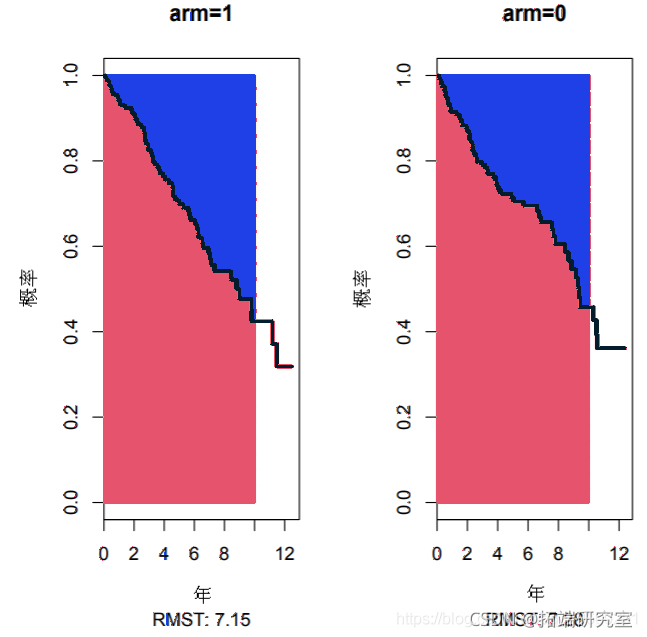
在下图中,粉红色和橙色的区域分别是D-青霉胺组的RMST和RMTL估计值,当τ为10年时。结果显示,在10年的随访中,D-青霉胺组的平均生存时间为7.28年。换句话说,在10年的随访中,接受D-青霉胺治疗的患者平均减少2.72年。
3.1 未经调整的分析及其实施
让μτ(1)和μτ(0)分别表示治疗组1和0的RMST。现在,我们用RMST或RMTL来比较这两条生存曲线。具体来说,我们考虑用以下三种措施来进行组间对比。
1. RMST的差异
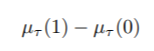
2. RMST的比值
![]()
3. RMTL的比率
![]()
这些估计是通过简单地用它们的经验对应(即分别为µτ(1)和µτ(0))来取代µτ(1)和µτ(0))。对于比率度量的推断,我们使用delta方法来计算标准误差。具体来说,我们考虑log{µˆτ(1)}和log{µˆτ(0)},并计算log-RMST的标准误差。然后,我们计算RMST的对数比率的置信区间,并将其转换回原始比率尺度。下面展示了如何实现这些分析。
-
> time=D$time
-
> status=D$status
-
> arm=D$arm
第一个参数(time)是时间到事件的向量变量。第二个参数(status)也是一个向量变量,其长度与时间相同,每个元素取1(如果有事件)或0(如果没有事件)。第三个参数(arm)是一个向量变量,表示每个受试者的指定实验;这个向量的元素取1(如果积极实验组)或0(如果控制组)。第四个参数(tau)是一个标量值,用于指定RMST计算中的截断时间点τ。请注意,τ需要小于两组中每组的最大观察时间的最小值(我们称其为最大τ)。
尽管程序代码允许用户选择一个比默认τ大的τ(如果它小于最大的τ),但我们总是确认,在每组指定的τ下,风险集的规模足够大,来确保KM估计的稳定性。下面是指定τ=10(年)时的pbc例子的输出。rmst2函数返回每组的RMST和RMTL以及上述组间对比测量的结果。
> print(obj)

在本例中,RMST的差异(输出中 "组间对比 "部分的第一行)为-0.137年。该点估计表明,在对病人进行10年的跟踪调查时,接受积极治疗的病人比安慰剂组的病人平均生存时间短0.137年。虽然没有观察到统计学意义(P=0.738),但0.95置信区间(-0.665至0.939)在0附近相对紧密,表明RMST的差异最多为+/-1年。可以生成一个图。下图是在运行上述未经调整的分析后生成的。
> plot(obj)
3.2 调整后的分析和应用
在大多数随机临床试验中,调整后的分析通常包括在计划分析中的一项。原因之一是对重要的预后因素进行调整可以提高检测组间差异的能力。另一个原因是我们有时会观察到一些基准预后因素的分布不平衡,即使随机化保证了两组的平均可比性。本文实现了Tian等人[4]提出的ANCOVA类型的调整分析,此外还有上一节中提出的未经调整的分析。设Y为限制性平均生存时间,设Z为治疗指标。同时,让X表示一个q维的基准协变量向量。田氏方法考虑以下回归模型
![]()
其中g(-)是一个给定的平滑且严格增加的链接函数,(α, β, γ0 )是一个(q + 2)维的未知参数向量。在Tian等人[4]之前,Andersen等人[5]也研究了这个回归模型,并提出了一个未知模型参数的推断程序,使用伪值技术来处理删减的观测值。与Andersen的方法[5, 6, 7]相比,Tian的方法[4]利用反概率删减加权技术来处理删减的观测值。如下图所示,对于实现Tian的RMST的调整分析,唯一的区别是用户是否向函数传递协变量数据。下面是一个执行调整后分析的示例代码。
covariates=x
其中covariates是基准特征数据的向量/矩阵的参数,x。为了说明问题,让我们试试以下三个基准变量,在pbc数据中,作为调整的协变量。
-
> x=D[,c(4,6,7)]
-
> head(x)

rmst2函数将数据拟合到三个对比度量(即RMST的差异、RMST的比率和RMTL的比率)中的每个模型。对于差异度量,上述模型中的链接函数g(-)是链接。对于比率指标,采用的是对数链接。具体来说,通过这个pbc例子,我们现在试图将数据拟合到以下回归模型中。
1. RMST的差异
![]()
2. RMST的比值
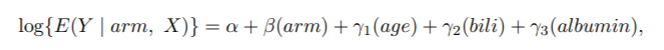
3. RMTL的比率
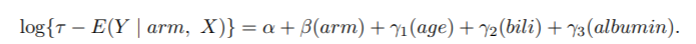
下面是rmst2对调整后的分析所返回的输出。
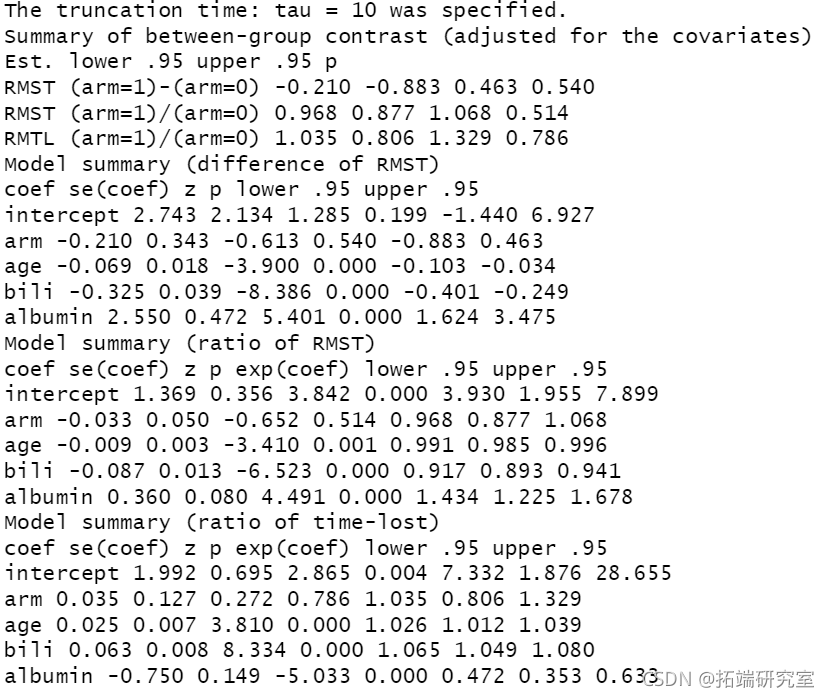
输出的第一块是调整后的实验效果的总结。随后,对三个模型中的每一个都进行了总结。
4 结论
风险比的问题在其他地方已经讨论过了,也提出了许多替代方法,但风险比的方法仍然被常规使用。受限的平均生存时间是一个稳健的、临床上可解释的生存时间分布的总结方法。与中位生存时间不同,即使在严重的删减情况下,它也是可以估计的。关于限制性平均生存时间,有相当多的方法学研究可以替代风险比方法。然而,这些方法在实践中似乎很少被使用。缺乏用户友好的、有明确例子的程序将是一个新的替代方法在实践中使用的主要障碍。我们希望这个文章有助于临床研究人员尝试超越舒适区--风险比。
参考文献
[1] Hernan, M. A. ´ (2010). The hazards of hazard ratios. Epidemiology (Cambridge, Mass) 21, 13–15.
[2] Uno, H., Claggett, B., Tian, L., Inoue, E., Gallo, P., Miyata, T., Schrag, D., Takeuchi, M., Uyama, Y., Zhao, L., Skali, H., Solomon, S., Jacobus, S., Hughes, M., Packer, M. & Wei, L.-J. (2014). Moving beyond the hazard ratio in quantifying the between-group difference in survival analysis. Journal of clinical oncology : official journal of the American Society of Clinical Oncology 32, 2380–2385.
[3] Miller, R. G. (1981). Survival Analysis. Wiley.

最受欢迎的见解
3.R语言如何在生存分析与Cox回归中计算IDI,NRI指标