原文链接:http://tecdat.cn/?p=23955
原文出处:拓端数据部落公众号
关联规则学习 在机器学习中用于发现变量之间的有趣关系。Apriori算法是一种流行的关联规则挖掘和频繁项集提取算法,在关联规则学习中有应用。它旨在对包含交易的数据库进行操作,例如商店客户的购买(购物篮分析)。除了购物篮分析之外,该算法还可以应用于其他问题。例如,在网络用户导航领域,我们可以搜索诸如访问过网页A和网页B的客户也访问过网页C的规则。
Python sklearn 库没有 Apriori 算法,其中 Python 库 MLxtend 用于市场篮子分析。在这篇文章中,我将分享如何使用Python 获取关联规则和绘制图表,为数据挖掘中的关联规则创建数据可视化 。首先我们需要得到关联规则。
从数组数据中获取关联规则
要获取关联规则,您可以运行以下代码
-
-
-
-
import pandas as pd
-
-
-
-
-
oary = ott(daset).trafrm(dtset)
-
-
df = pd(oh_ry, column=oht.cns)
-
print (df)
-

-
-
-
frequent = apror(df, mn_upprt=0.6, useclaes=True)
-
-
print (frequent )
-

数据挖掘中的置信度和支持度
为了选择有趣的规则,我们可以使用最知名的约束,即置信度和支持度的最小阈值 。
支持度是指项目集在数据集中出现的频率。
置信度表示规则被发现为真的频率。
-
suprt=rules(['suport'])
-
-
cofidece=rules(['confience'])
关联规则——散点图
建立散点图的python代码。由于这里有几个点有相同的值,我添加了小的随机值来显示所有的点。
-
-
-
for i in range (len(supprt)):
-
-
suport[i] = suport[i] + 0.00 * (ranom.radint(,10)- 5)
-
confidence[i] = confidence[i] + 0.0025 * (rao.rant(1,10) - 5)
-
-
-
plt.show()
以下是支持度和置信度的散点图:
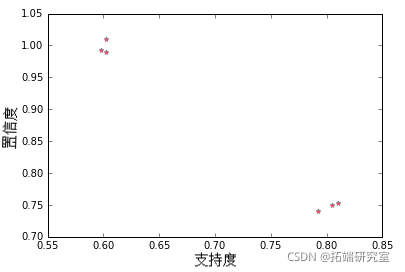
如何为数据挖掘中的关联规则创建数据可视化
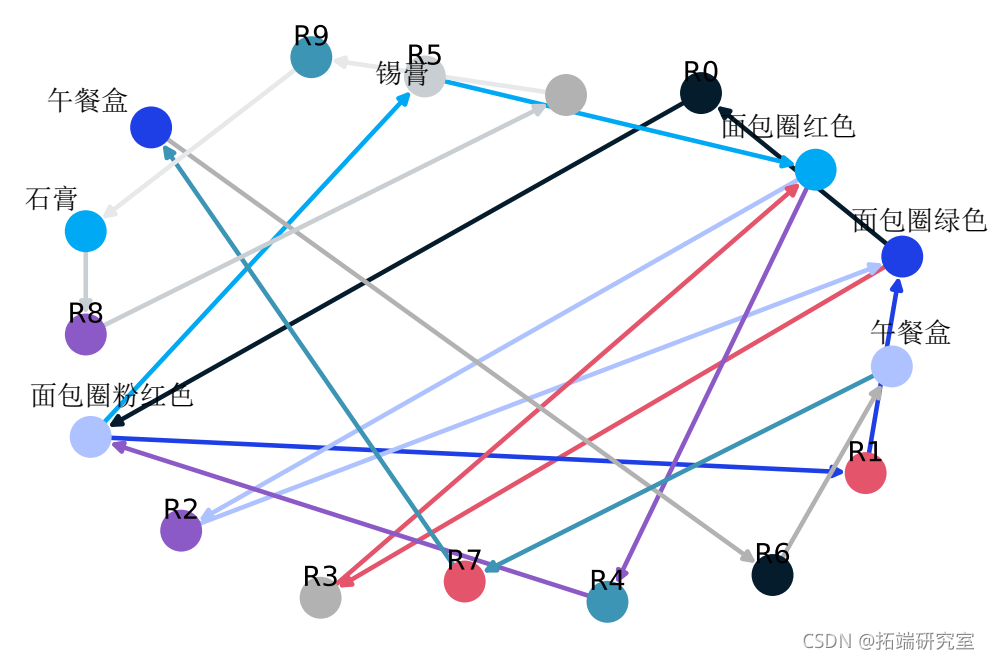
为了将关联规则表示为图。这是关联规则示例:(豆,洋葱)==>(鸡蛋)
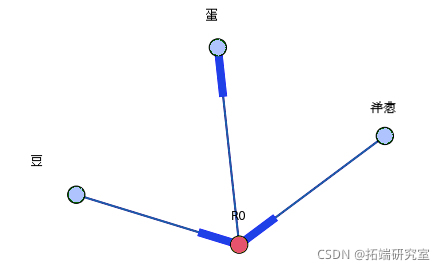
下面的有向图是为此规则构建的,如下所示。具有 R0 的节点标识一个规则,并且它总是具有传入和传出边。传入边将代表规则前项,箭头在节点旁边。
下面是一个从实例数据集中提取的所有规则的图形例子。
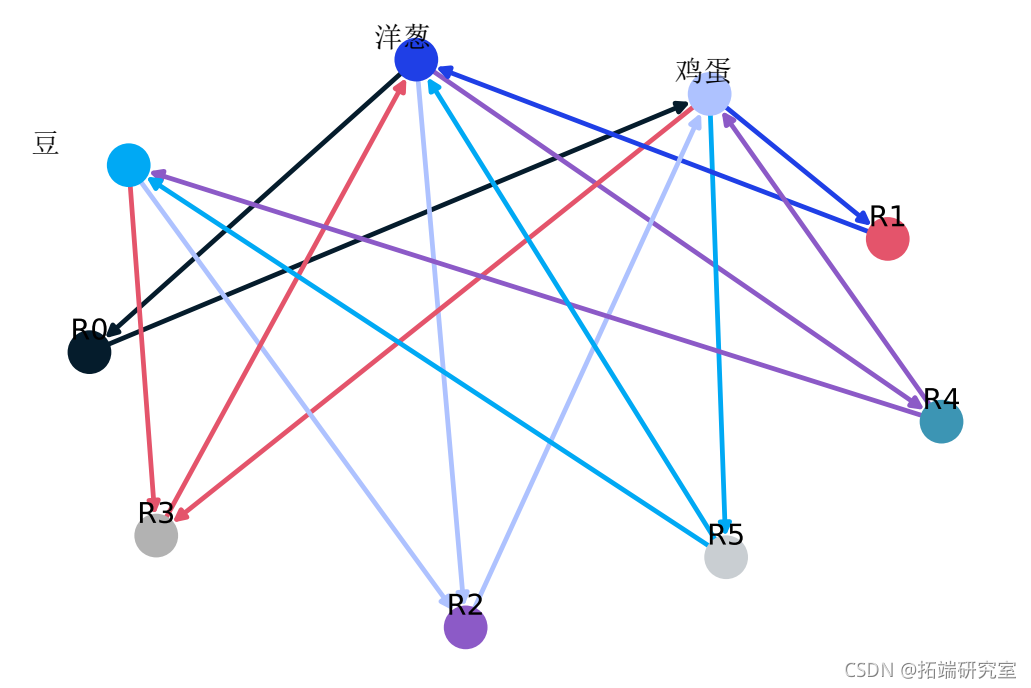
这是构建关联规则的源代码。
-
import networkx as nx
-
-
G1 = nx.iGaph()
-
-
-
-
colr_ap=[]
-
-
N = 50
-
-
colors = np.randm.rndN)
-
-
-
-
-
-
for i in range (rue_o_w):
-
-
G1.a_od_from(["R"+st(i)])
-
-
-
-
-
-
for a in rsloc[i]['anedts']:
-
-
-
-
G1.dnoesrom([a])
-
-
-
-
G1.adedg(a, "R"+str(i))
-
-
-
-
for c in ruleioc[i]['']:
-
-
-
-
G1.addnodsom()
-
-
-
-
G1.adddge"R"str(i), c, colo=[i], weht=2)
-
-
-
-
for noe in G1:
-
-
fod_astring = alse
-
-
for iem in sts:
-
-
if nde==itm:
-
-
found_a_ring = True
-
-
if fond_sting:
-
-
cor_mp.apend('ellw')
-
-
else:
-
cor_mapapped('green')
-
-
-
-
-
plt.show()
在线零售数据集的数据可视化
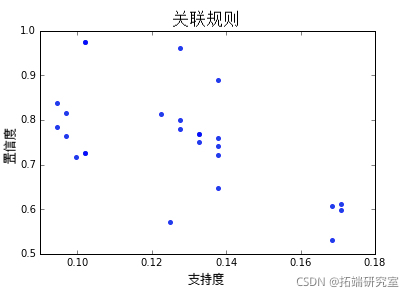
为了对可视化进行真实感受和测试,我们可以采用可用的在线零售商店数据集并应用关联规则图的代码。
以下是支持度和置信度的散点图结果。这次使用seaborn库来构建散点图。下面是零售数据集关联规则(前 10 条规则)的可视化。

最受欢迎的见解
3.r语言文本挖掘tf-idf主题建模,情感分析n-gram建模研究
4.python主题建模可视化lda和t-sne交互式可视化