原文链接:http://tecdat.cn/?p=24016
原文出处:拓端数据部落公众号
摘要
面板向量自回归(VAR)模型在应用研究中的应用越来越多。虽然专门用于估计时间序列VAR模型的程序通常作为标准功能包含在大多数统计软件包中,但面板VAR模型的估计和推断通常用通用程序实现,需要一些编程技巧。在本文中,我们简要讨论了广义矩量法(GMM)框架下面板VAR模型的模型选择、估计和推断,并介绍了一套Stata程序来方便地执行它们。
一、简介
时间序列向量自回归 (VAR) 模型起源于宏观计量经济学文献,作为多元联立方程模型的替代品 (Sims, 1980)。VAR 系统中的所有变量通常都被视为内生变量,尽管可能会根据理论模型或统计程序来确定限制,以解决外生冲击对系统的影响。随着 VAR 在面板数据设置中的引入(Holtz-Eakin、Newey 和 Rosen,1988),面板 VAR 模型已在跨领域的多个应用中使用。
在本文中,我们简要概述了广义矩量法 (GMM) 框架中面板 VAR 模型的选择、估计和推理,并提供了一组 Stata 程序,我们使用国家纵向调查和投资、收入和消费数据。 包括实现Granger(1969)因果关系检验的子程序,以及按照Andrews和Lu(2001)进行的最佳时刻和模型选择。
2.面板向量自回归
我们考虑具有特定面板固定效应的阶数 -变量面板 VAR,由以下线性方程组表示:
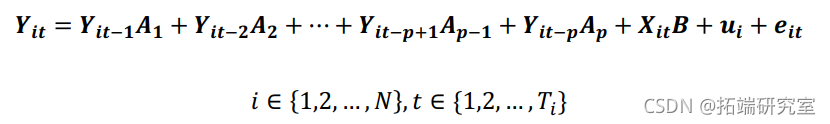
其中,![]() 是因变量的(1)向量;
是因变量的(1)向量;![]() 是外生协变量的(1)向量;
是外生协变量的(1)向量;![]() 以及
以及![]() 分别是因变量特定的固定效应和特异性误差的(1)向量。
分别是因变量特定的固定效应和特异性误差的(1)向量。![]() 矩阵和
矩阵和![]() 矩阵是要估计的参数。我们假设创新点具有以下特征。
矩阵是要估计的参数。我们假设创新点具有以下特征。
![]()
![]()
上面的参数可以与固定效应联合估计,或者在一些转换后独立于固定效应,使用普通最小二乘法 (OLS)。然而,由于方程组右侧存在滞后因变量,即使是大的估计也会有偏差(尼克尔,1981)。尽管偏差随着变大而趋近于零,但 Judson 和 Owen (1999) 的模拟发现即使在 = 30 时也存在显着偏差。
2.1.GMM估计
已经提出了基于 GMM 的各种估计器来计算上述方程的一致估计。4在我们假设误差是连续不相关的情况下,一阶差分变换可以通过用较早时期的差异和水平检测滞后差异,如安德森和萧 (1982) 所提出的那样,逐个方程地一致估计。然而,这个估计会带来一些问题。一阶差分变换放大了不平衡面板中的间隙。例如,如果某些不可用,则时间和 − 1 处的一阶差分同样缺失。此外,观察每个面板的必要时间段随着面板 VAR 的滞后顺序而变大。例如,对于二阶面板 VAR,
Arellano 和 Bover (1995) 提出前向正交偏差作为替代变换,它不具有一阶差分变换的缺点。它不使用与过去实现的偏差,而是减去所有可用的未来观察的平均值,从而最大限度地减少数据丢失。可能只有最近的观察不会用于估计。由于过去的实现不包括在这个转换中,它们仍然是有效的工具。例如,在二阶面板 VAR 中,只有 ![]() ≥ 4 个实现才能在水平上使用工具。
≥ 4 个实现才能在水平上使用工具。
虽然逐个方程的 GMM 估计会产生对面板 VAR 的一致估计,但将模型估计为方程组可能会导致效率增益(Holtz-Eakin、Newey 和 Rosen,1988 年)。考虑以下基于等式 (1) 的变换面板 VAR 模型,但以更紧凑的形式表示:
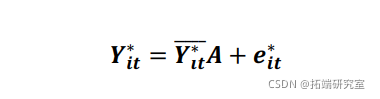
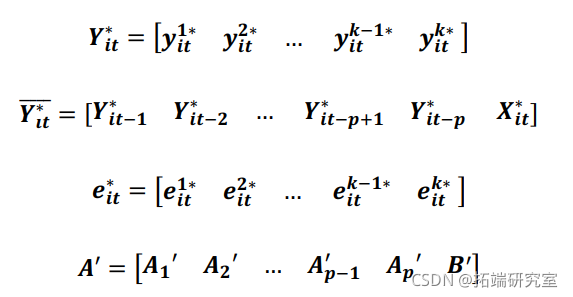
其中星号表示原始变量的某种变换。如果我们把原始变量表示为![]() ,那么第一差分转换意味着
,那么第一差分转换意味着![]() ,而对于正向正交偏差
,而对于正向正交偏差 ![]() ,其中是面板在时间上的可用未来观测值的数量,是其平均值。
,其中是面板在时间上的可用未来观测值的数量,是其平均值。
假设我们随着时间的推移将观察叠加在面板上。GMM 估计量由下式给出
![]()
其中是一个 ( ) 加权矩阵,假定为非奇异、对称和半正定。假设![]() 和 rank
和 rank![]() ,GMM 估计量是一致的。可以选择加权矩阵来最大化效率(Hansen,1982)。
,GMM 估计量是一致的。可以选择加权矩阵来最大化效率(Hansen,1982)。
方程组的联合估计使交叉方程假设检验变得简单明了。可以基于 ![]() 的 GMM 估计及其协方差矩阵来实现关于参数的 Wald 检验。格兰杰因果检验,假设变量 的方程中变量滞后的所有系数共同为零,同样可以使用该检验进行。
的 GMM 估计及其协方差矩阵来实现关于参数的 Wald 检验。格兰杰因果检验,假设变量 的方程中变量滞后的所有系数共同为零,同样可以使用该检验进行。
2.2.模型选择
面板 VAR 分析的前提是在面板 VAR 规范和矩条件中选择最佳滞后阶数。Andrews和Lu(2001)提出了基于Hansen(1982)统计学的过度识别限制的GMM模型的一致时刻和模型选择标准(MMSC)。他们提出的 MMSC 类似于各种常用的基于最大似然的模型选择标准,即 Akaike 信息标准 (AIC) (Akaike, 1969)、贝叶斯信息标准 (BIC) (Schwarz, 1978; Rissanen, 1978; Akaike, 1977 ),以及 Hannan-Quinn 信息标准 (HQIC)(Hannan 和 Quinn,1979)。
将 Andrews 和 Lu 的 MMSC 应用 GMM 估计,他们提出的标准选择最小化的向量对![]()
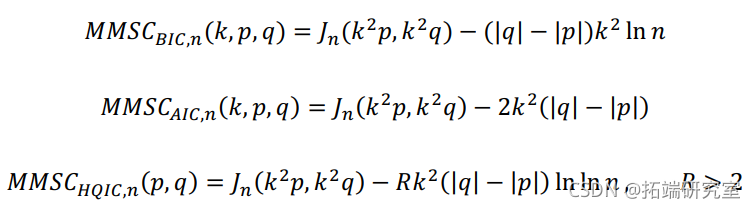
其中![]() 是基于样本大小为
是基于样本大小为![]() 的因变量滞后的阶次和矩条件的变量面板 VAR 的过度识别限制的统计量。
的因变量滞后的阶次和矩条件的变量面板 VAR 的过度识别限制的统计量。
通过构造,上述 MMSC 仅在![]() 时可用。作为替代标准,即使使用刚刚识别的 GMM 模型,也可以计算整体确定系数 (CD)。假设我们用
时可用。作为替代标准,即使使用刚刚识别的 GMM 模型,也可以计算整体确定系数 (CD)。假设我们用 ![]() 表示因变量的
表示因变量的 ![]() 无约束协方差矩阵。CD 为面板 VAR 模型解释的变异比例,可以计算为
无约束协方差矩阵。CD 为面板 VAR 模型解释的变异比例,可以计算为
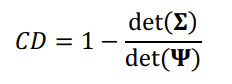
2.3.脉冲响应
我们删除外生变量,并专注于方程(1)中面板 VAR 的自回归结构。Lutkepohl (2005) 和 Hamilton (1994) 都表明,如果伴随矩阵的所有模都严格小于 1,则 VAR 模型是稳定的,其中伴随矩阵由
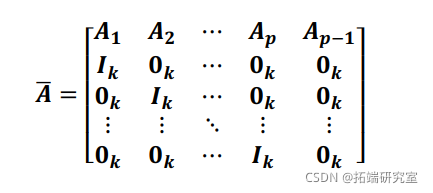
稳定性意味着面板 VAR 是可逆的,并且具有无限阶向量移动平均 (VMA) 表示,为估计的脉冲响应函数和预测误差方差分解提供已知的解释。可以通过将模型重写为无限向量移动平均来计算简单的脉冲响应函数,其中![]() 是 VMA 参数。
是 VMA 参数。
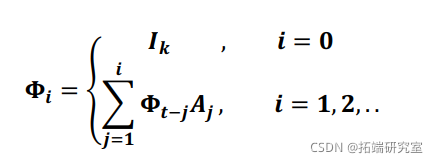
然而,简单的 IRF 没有因果解释。由于创新是同时相关的,一个变量的冲击很可能伴随着其他变量的冲击。假设我们有一个矩阵 ![]() ,使得
,使得![]() 。然后可用于将创新点正交化,并将 VMA 参数转换为正交化的脉冲响应。矩阵有效地对动态方程组施加了识别限制。Sims (1980) 提出了 的 Cholesky 分解以在 VAR 上强加递归结构。然而,分解不是唯一的,而是取决于
。然后可用于将创新点正交化,并将 VMA 参数转换为正交化的脉冲响应。矩阵有效地对动态方程组施加了识别限制。Sims (1980) 提出了 的 Cholesky 分解以在 VAR 上强加递归结构。然而,分解不是唯一的,而是取决于![]() 中变量的顺序。
中变量的顺序。
脉冲响应函数置信区间可以基于面板 VAR 参数的渐近分布和交叉方程误差方差-协方差矩阵分析导出。或者,也可以使用蒙特卡罗模拟和自举重采样方法来估计置信区间。
2.4.预测误差方差分解
ℎ步提前预测误差可以表示为
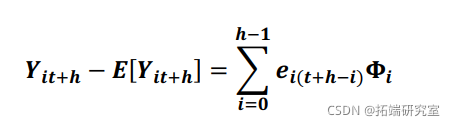
其中![]() 是在时间 + ℎ 处的观察向量,
是在时间 + ℎ 处的观察向量,![]() 是在时间 ℎ 预测的提前 ℎ 步预测向量。与脉冲响应函数类似,我们使用矩阵将冲击正交化,以隔离每个变量对预测误差方差的贡献。正交化冲击
是在时间 ℎ 预测的提前 ℎ 步预测向量。与脉冲响应函数类似,我们使用矩阵将冲击正交化,以隔离每个变量对预测误差方差的贡献。正交化冲击![]() 有一个协方差矩阵
有一个协方差矩阵 ![]() ,可以直接分解预测误差方差。更具体地说,m变量对变量n的ℎ步预测误差方差的贡献可以计算为
,可以直接分解预测误差方差。更具体地说,m变量对变量n的ℎ步预测误差方差的贡献可以计算为
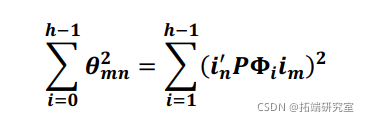
在应用中,贡献通常相对于变量的ℎ步超前预测误差方差进行归一化。
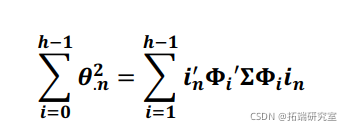
与脉冲响应函数类似,置信区间可以通过分析得出或使用各种重采样技术进行估计
4. 例子
我们通过分析年工作时间和小时收入之间的关系来说明 pvar使用,Holtz-Eakin、Newey 和 Rosen(1988)之前在他们关于面板向量自回归的开创性论文中对此进行了分析。为了将我们的新程序与 Stata 的内置 var 命令套件进行比较,我们还将新的 pvar 应用于投资、收入和消费数据时间序列数据。
我们通过分析年工作时间和小时收入之间的关系来说明pvar使用,Holtz-Eakin、Newey和Rosen(1988)曾在他们关于面板向量自回归的开创性论文中分析过这种关系。我们还将pvar应用于Lutkephol(1993)的时间序列数据。
4.1.全国纵向调查数据
我们使用来自 1968 年至 1978 年国家纵向调查的 1968 年 14-26 岁女性子样本。我们的子样本由 2,039 名女性组成,她们在至少三轮调查中报告了工资(wage)和年工作时数(hours),其中两轮是连续年份。使用相同的调查,但具有不同的时间段和不同的工人子样本,因此结果可能不具有直接可比性。
下面是使用模型选择,用于以工时和工资的前四个滞后期为工具的一到三阶面板VARs。
-
.ua3 vs(ns(1/4))
-
.gen wge = exp(nwage)
-
.erk
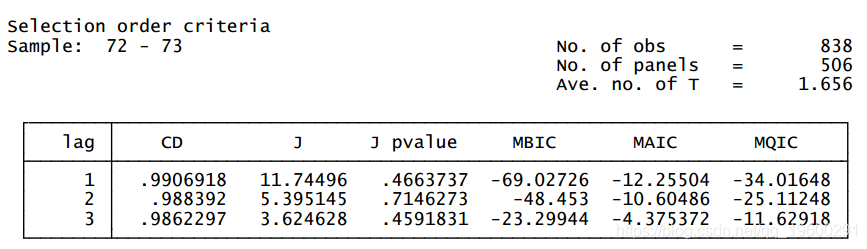
基于 Andrews 和 Lu (2001) 的三个模型选择标准和整体决定系数,一阶面板 VAR 是首选模型,因为它具有最小的 MBIC、MAIC 和 MQIC。虽然我们也想最小化 Hansen 的 J 统计量,但它并没有像 Andrews 和 Lu 的模型和矩选择标准那样修正模型中的自由度。基于选择标准,我们使用由 pvar 实现的 GMM 估计拟合具有与上述相同的一阶面板 VAR 模型。
-
面板向量自回归
-
. wg rs, in(1/4)
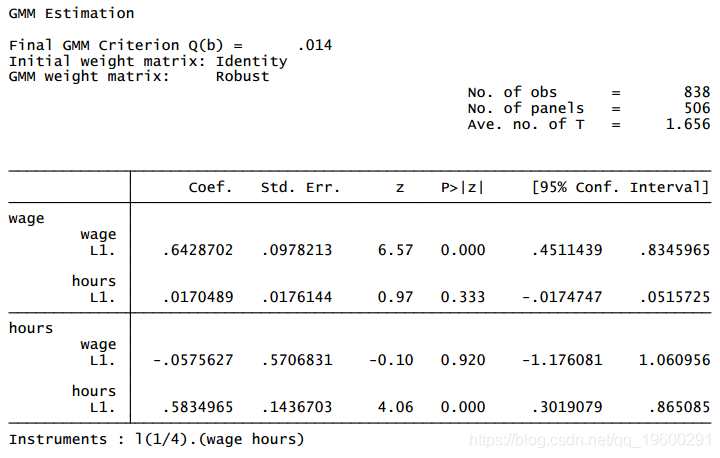
请注意,估计中包括的506名妇女明显少于数据中的全部妇女子样本。默认情况下,pvar会从估计中删除任何缺失数据的观察。由于子样本中的所有妇女的工作时间和工资并不是在所有年份都被观察到的,所以被剔除的观察值的数量会随着作为工具变量的滞后阶数而增加。我们可以通过使用Holtz-Eakin等人提出的 "GMM式 "工具来改善估计。这增加了估计样本,从而使估计更加有效。
-
面板向量自回归
-
.s tl(1/4) gmm
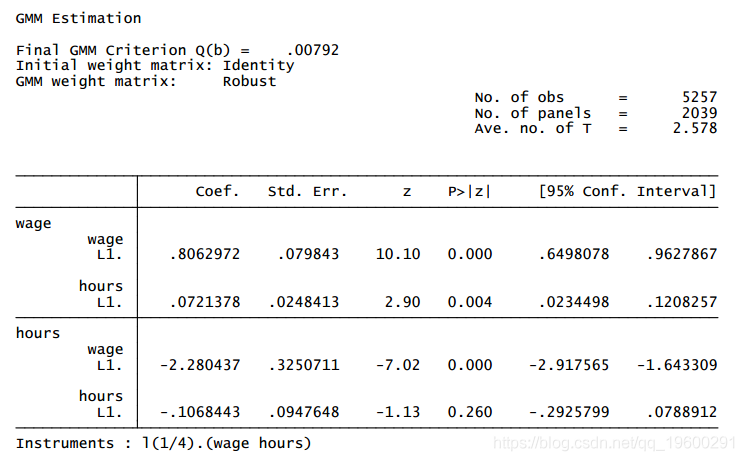
尽管可以从上面的 var 输出推断出一阶面板 VAR 的格兰杰因果关系,但我们仍然使用 granger 作为说明进行检验。下面格兰杰因果检验的结果表明,在通常的置信水平下,工资格兰杰导致工时和工时格兰杰导致工资,这与 Holtz-Eakin 等人的发现相似。
. granger
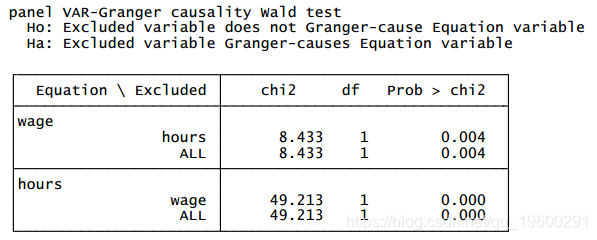
面板向量自回归模型估计很少由其自身解释。在实践中,研究人员通常对面板 VAR 系统中每个内生变量的外生变化对其他变量的影响感兴趣。然而,在估计脉冲响应函数 (IRF) 和预测误差方差分解 (FEVD) 之前,我们首先检查估计面板 VAR 的稳定性条件。生成的特征值表和图证实了估计是稳定的。
.table, rph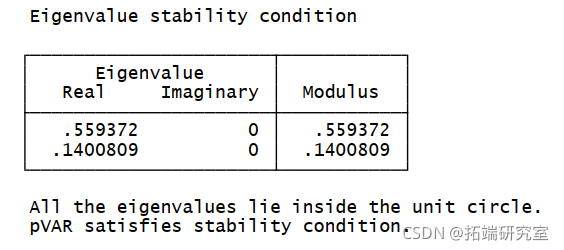
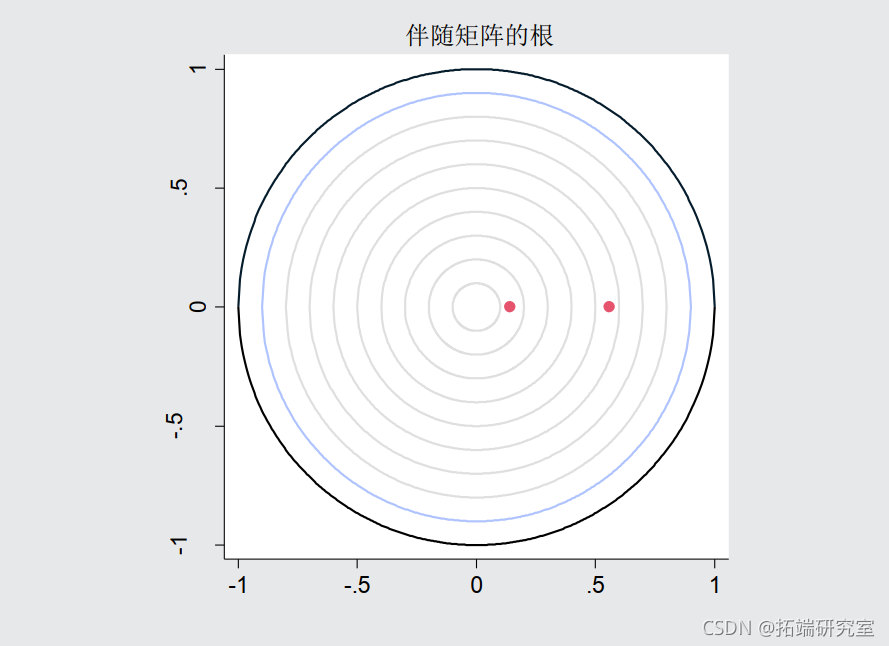
我们认为工资水平的冲击对同期的工作时间有直接影响,而当前的工作努力只影响未来的工资。使用这种因果顺序,我们使用 fevd 计算了隐含的 IRF,使用 fevd 计算了隐含的 FEVD。IRF 置信区间是根据估计模型使用 200 次蒙特卡罗绘制计算的。FEVD 估计值的标准误差和置信区间同样可用。
-
.
-
. pirf, c20) irf op
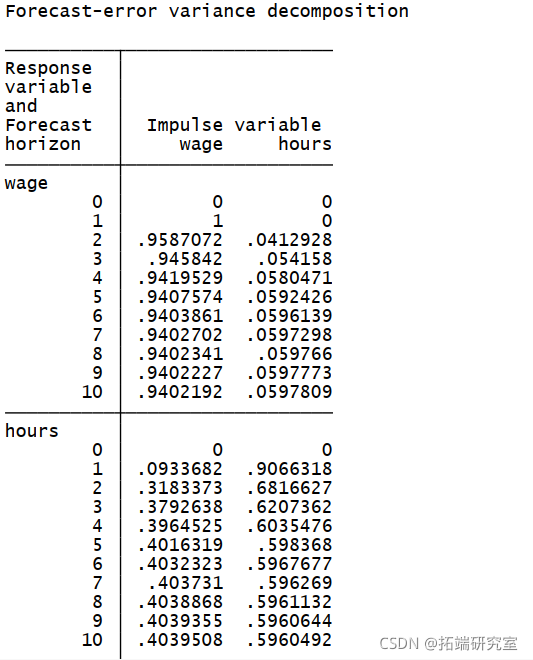
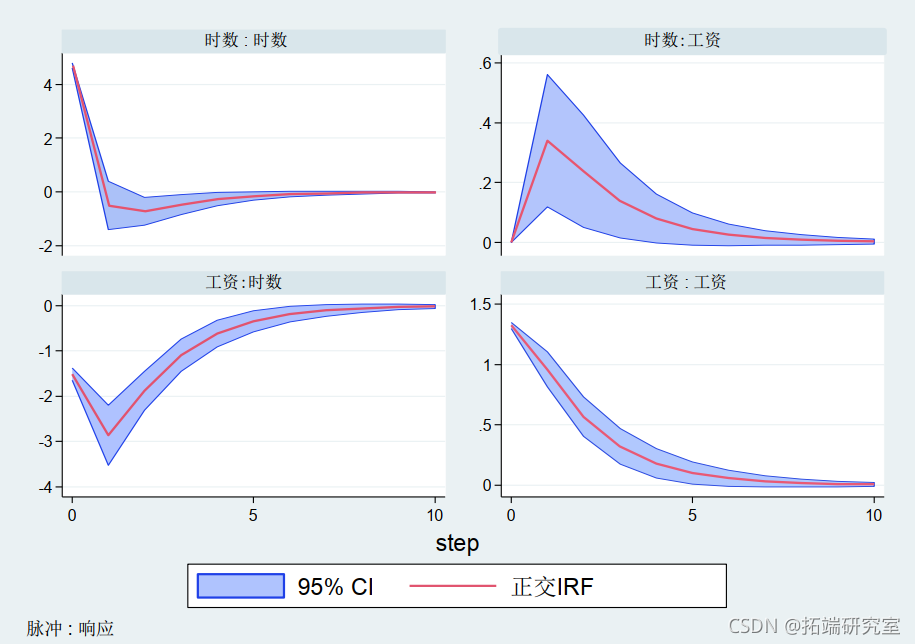
根据FEVD的估计,我们看到,在我们的例子中,多达40%的妇女工作时间的变化可以由她们的工资来解释。另一方面,工作时间只解释了妇女未来工资变化的5%。就水平而言,IRF图显示,实际工资的正冲击导致工作努力的减少,这意味着样本中妇女的劳动供给向后弯曲。同样值得注意的是,当前工作强度的冲击对工作时间和工资都有积极但短暂的影响。另一方面,当前冲击对工资的影响对未来工资有持续的积极影响。
4.2.投资、收入和消费数据
我们使用投资、收入和消费数据时间序列数据进行比较。该数据包含从 1962 年第二季度到 1982 年第四季度的投资、收入和消费 自然对数的一阶差分。 仅使用截至第四季度的观测值1978 年在他的例子中,但我们在这里的说明中使用了完整的样本。我们将时间序列数据设置为单面板数据,以便 pvar 发挥作用。
-
delta: 1 qt
-
time vaabl qr, 1960q1 to 1982q4
-
panel aiale: id
-
. xet d tr
-
. gen id = 1
-
. wue utph2
为简单起见,我们使用内置的var(在下面的输出中表示为 var1)和新的 pvar 来比较 VAR(1) 估计值。VAR/面板 VAR 点估计总结为下表。根据计算的点估计和标准误差,请注意每个系数的 95% 置信区间,即点估计两侧的大约两个标准误差,在估计量之间重叠。此外,由于前向正交变换,pvar 使用的观察值比 var 少一个。
-
. est table v1_pvr5, st(Nmntmx) drop(_cons)
-
. est tor pr1
-
. est store ar1_
-
. qui al_ l_ic dnm, gs(1)
-
. est sor vr1

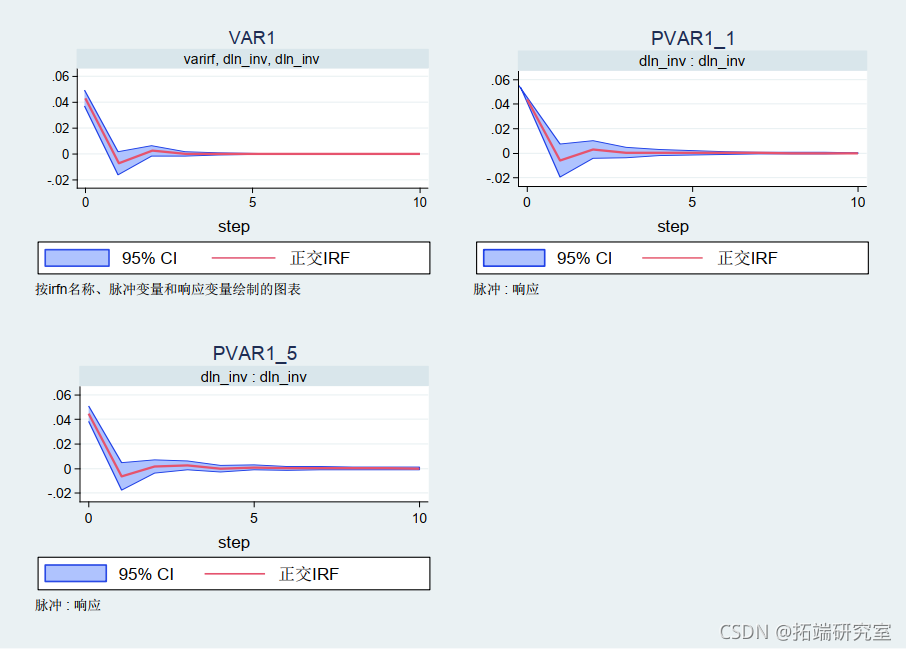
Cholesky 脉冲响应函数和预测误差方差分解同样可以使用新的 Stata 命令 pvarirf 和 pvarfevd 进行估计。与 VAR/面板 VAR 点估计类似,95% 置信区间三个估计量的 Cholesky IRF 和 FEVD 重叠。下面,我们使用三个模型展示了 inv 对inv 上一个标准差冲击的响应。
5. 参考
Akaike, H. (1969)。拟合自回归模型进行预测。统计数学研究所年鉴,21, 243-247。

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析